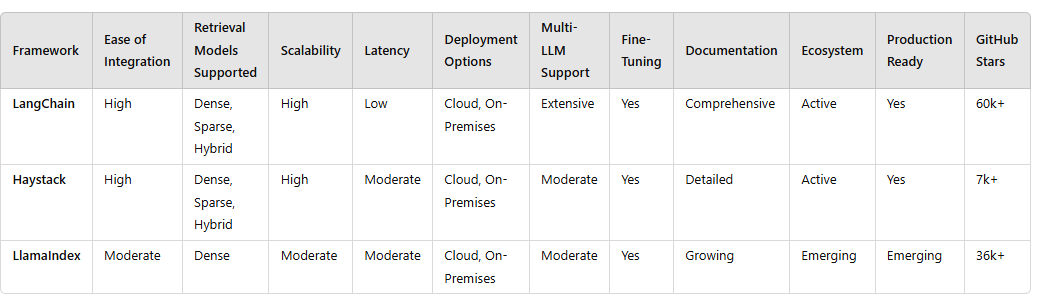
ask.py: Perplexity like search-extract-summarize flow in Python
ask.py: 类似于搜索-提取-摘要流程的 Perplexity 实现,使用 Python 编写
I’ve been experimenting with ask.py. to create a search-extract-summarize flow — something similar to what AI search engines like Perplexity offer.
我一直在尝试使用 ask.py 来创建一个搜索-提取-总结流程——类似于 Perplexity 等 AI 搜索引擎提供的功能。
While it’s a simplified version compared to what’s out there commercially, it’s a great way to get hands-on experience with the core concepts.
虽然与市面上的商业版本相比,这是一个简化版,但它是获得核心概念实践经验的好方法。
ask.py Workflow ask.py 工作流程
Given a query, here’s the step-by-step process the program follows:
给定一个查询,以下是程序遵循的逐步过程:
- Web Search: It starts by querying Google to fetch the top 10 relevant web pages.
网络搜索:首先通过查询 Google 获取前 10 个相关网页。 - Content Scraping: It then crawls each of these pages to extract their textual content.
内容抓取:然后,它爬取这些页面中的每一个,以提取其文本内容。 - Chunking and Storage: The extracted text is broken down into smaller chunks and stored in a vector database.
分块与存储:提取的文本被分解成较小的块并存储在向量数据库中。 - Vector Similarity Search: Using the original query, it performs a vector search to find the top 10 matching text chunks.
向量相似性搜索:使用原始查询,执行向量搜索以找到前 10 个匹配的文本块。 - [Optional] Hybrid Search: It can also perform a full-text search and combine those results with the vector search.
[可选] 混合搜索:它还可以执行全文搜索,并将这些结果与向量搜索结合起来。 - [Optional] Re-ranking: A reranker can be used to refine the ordering of the top chunks.
[可选] 重排序:可以使用重排序器来优化顶部块的排序。 - Answer Generation: The selected chunks serve as context for an LLM (Language Model) to generate a coherent answer.
答案生成:选中的文本块作为上下文供LLM(语言模型)生成连贯的答案。 - Output with References: Finally, it outputs the generated answer along with references to the source material.
输出带参考文献:最后,它输出生成的答案以及源材料的参考文献。
This flow is a stripped-down version of what real AI search engines implement, but it’s sufficient to grasp the basic mechanics and start building upon them.
此流程是真实 AI 搜索引擎实现的一个简化版本,但足以理解基本机制并在此基础上开始构建。
Why Customize? 为什么需要定制?
One of the perks of building your own pipeline is the ability to tweak both the search functionality and the output format. Here are some ways you can customize the system:
构建自己的管道的好处之一是能够调整搜索功能和输出格式。以下是一些自定义系统的方法:
- Date Restrictions: Limit search results to recent information by specifying a date range.
日期限制:通过指定日期范围将搜索结果限制为近期信息。 - Site-Specific Searches: Focus the search on a particular website to generate answers based solely on its content.
站点特定搜索:将搜索集中在特定网站上,仅基于其内容生成答案。 - Language Output: Instruct the LLM to generate answers in a specific language.
语言输出:指示LLM以特定语言生成答案。 - Controlled Length: Define the desired length of the generated answer.
控制长度:定义生成答案的期望长度。 - Custom URL Lists: Provide a list of URLs to crawl and generate answers based only on those sources.
自定义 URL 列表:提供一个 URL 列表,仅基于这些来源进行爬取并生成答案。
Let’s see how it works in practice.
让我们看看它在实践中是如何运作的。

Installation 安装
To start working with ask.py, ensure you’re using Python 3.10 or later. I recommend setting up a virtual environment using venv or conda to keep your dependencies isolated.
要开始使用 ask.py,请确保您使用的是 Python 3.10 或更高版本。我建议使用 venv 或 conda 设置虚拟环境,以隔离您的依赖项。
# Create and activate a virtual environment
python3 -m venv askpy-env
source askpy-env/bin/activate
git clone https://github.com/pengfeng/ask.py.git
cd ask.py/
pip3 install -r requirements.txt
pip3 install ipykernel jupyterSetting Up API Keys 设置 API 密钥
You’ll need API keys for both Google Search and OpenAI. You can either modify the .env file or export them as environment variables:
你需要为 Google Search 和 OpenAI 获取 API 密钥。你可以修改 .env 文件或将它们导出为环境变量:
# Google Search API
export SEARCH_API_KEY="your-google-search-api-key"
export SEARCH_PROJECT_KEY="your-google-cx-key"
# OpenAI API
export LLM_API_KEY="your-openai-api-key"Here’s a list of tools and libraries that ask.py uses:
以下是 ask.py 使用的工具和库列表:
- Google Search API: For fetching search results.
Google Search API:用于获取搜索结果。 - OpenAI API: For generating answers using language models.
OpenAI API:用于使用语言模型生成答案。 - Jinja2: Templating engine for Python.
Jinja2:Python 的模板引擎。 - BeautifulSoup (bs4): For parsing HTML content.
BeautifulSoup (bs4):用于解析 HTML 内容。 - DuckDB: An in-process SQL OLAP database management system.
DuckDB:一个进程内的 SQL OLAP 数据库管理系统。 - Gradio: To build a simple web interface.
Gradio:用于构建一个简单的网页界面。
Running the Program 运行程序
To run a basic query:
要运行基本查询:
python ask.py -q "What is an LLM agent?"You can adjust parameters like date_restrict and target_site to control the behavior.
您可以调整像 date_restrict 和 target_site 这样的参数来控制行为。
For a full list of options:
有关选项的完整列表:
python ask.py --helpUsage: 用法:
Usage: ask.py [OPTIONS]
Search web for the query and summarize the results.
Options:
-q, --query TEXT Query to search
-o, --output-mode [answer|extract]
Output mode for the answer, default is a
simple answer
-d, --date-restrict INTEGER Restrict search results to a specific date
range, default is no restriction
-s, --target-site TEXT Restrict search results to a specific site,
default is no restriction
--output-language TEXT Output language for the answer
--output-length INTEGER Output length for the answer
--url-list-file TEXT Instead of doing web search, scrape the
target URL list and answer the query based
on the content
--extract-schema-file TEXT Pydantic schema for the extract mode
-m, --inference-model-name TEXT
Model name to use for inference
--hybrid-search Use hybrid search mode with both vector
search and full-text search
--web-ui Launch the web interface
-l, --log-level [DEBUG|INFO|WARNING|ERROR]
Set the logging level [default: INFO]
--help Show this message and exit.Let’s have a look at few examples.
让我们看几个例子。
General Search 通用搜索
Here’s a simple query: 这是一个简单的查询:
python ask.py -q "Why do we need agentic RAG even if we have ChatGPT?"Which will output: 将输出:
Agentic RAG (Retrieval-Augmented Generation) complements ChatGPT by enhancing precision and contextual relevance. While ChatGPT generates conversational responses, RAG integrates retrieval mechanisms to provide accurate and up-to-date information. It allows for customization, such as referencing company-specific data, and handles complex queries more effectively. Additionally, future agentic systems aim to incorporate asynchronous processing, improving efficiency over the current capabilities of ChatGPT.
References:
[1] https://community.openai.com/...
[2] https://www.linkedin.com/...
...Site and Date-Restricted Search
站点和日期限制搜索
If you want to get the latest information from a specific site, you can restrict the search by date and domain:
如果你想从特定网站获取最新信息,可以通过日期和域名来限制搜索范围:
python ask.py -q "OpenAI Swarm Framework" -d 1 -s openai.comSample output: 示例输出:
The OpenAI Swarm Framework is an experimental platform for building multi-agent systems, enabling AI agents to collaborate on complex tasks. It differs from traditional single-agent models by facilitating interaction and coordination among agents, enhancing efficiency. This framework allows developers to orchestrate agent systems using Node.js, making it suitable for scalable applications.
References:
[1] https://community.openai.com/...
[2] https://community.openai.com/...
...Extracting Structured Data
提取结构化数据
You can also extract structured information by providing an extraction schema:
您还可以通过提供提取模式来提取结构化信息:
python ask.py -q "LLM Gen-AI Startups" -o extract --extract-schema-file instructions/extract_example.txtSample output: 示例输出:
Codebase is rather small and understanding it will be beneficial.
代码库相当小,理解它将是有益的。
It offers a practical way to explore how search engines and LLMs can work together to generate informative answers.
它提供了一种实用的方法来探索搜索引擎和LLMs如何协同工作以生成信息丰富的答案。
There’s plenty of room for customization and improvement, so feel free to dive in and tweak the code to fit your needs.
有大量的定制和改进空间,所以请随意深入并调整代码以满足您的需求。
Let me know if you have any questions, happy coding!
如果有任何问题,请告诉我,编程愉快!
I want to personally thank you for taking your time to be here — I truly appreciate it!
我想亲自感谢您抽出时间来到这里——我真的很感激!If you enjoyed this piece, it would mean a lot if you could follow Agent Issue on Medium, give this article a clap, and drop a quick hello in the comments!
如果你喜欢这篇文章,如果你能在 Medium 上关注 Agent Issue,给这篇文章一个掌声,并在评论中快速打个招呼,那将意义重大!I also share more insights over on X — come join the conversation!
我也在 X 上分享更多见解——快来加入对话吧!
Bonus Content : Building with AI
奖励内容:使用 AI 构建
And don’t forget to have a look at some practitioner resources that we published recently:
别忘了查看我们最近发布的一些从业者资源:
Thank you for stopping by, and being an integral part of our community.
感谢您的光临,并成为我们社区不可或缺的一部分。