🚨 医疗 AI 研究警报!🚨(播客 🔥版本)
查看下面论文的音频节目的视频! :)
人工智能真的能真正改变医生级别的临床决策吗?
UCLA 特别呈现:CLIBENCH:对大语言模型在临床决策制定领域进行多方面、多粒度评估的多功能、多粒度评估
作者:mingyu_ma , chenchenye_ccye , Yu Yan, Xiaoxuan Wang, Peipei Ping,timschang , Wei Wang
Spotify : https://t.co/pPXMRxEnQv
YouTube :https://t.co/gCupCVT4X5
这里为什么是划时代的重要一步!1/🧵👇你的浏览器不支持视频标签。
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
2/9 重点概览:
- CLIBENCH 是一种新型基准,旨在评估大语言模型在多医学专科临床决策中的表现。
- 它侧重于实际临床任务,包括诊断、治疗建议、实验室测试单据和处方生成。
#人工智能在医疗 #临床人工智能

- CLIBENCH 是一种新型基准,旨在评估大语言模型在多医学专科临床决策中的表现。
- 它侧重于实际临床任务,包括诊断、治疗建议、实验室测试单据和处方生成。
#人工智能在医疗 #临床人工智能
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
3/9 实际世界影响:
- 使用了广泛的 MIMIC-IV 数据集,它评估了 AI 模型在复杂临床任务上的性能,而不是简单的诊断。
- CLIBENCH 有助于在实际临床医生面临的一系列广泛的专科和患者群体中测试 AI 模型。

- 使用了广泛的 MIMIC-IV 数据集,它评估了 AI 模型在复杂临床任务上的性能,而不是简单的诊断。
- CLIBENCH 有助于在实际临床医生面临的一系列广泛的专科和患者群体中测试 AI 模型。
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
4/9 CLIBENCH 的关键特性:
从广泛的诊断类别向下到详细的程序和治疗方法的多粒度评估。
- 评估大语言模型在处理如:的任务上的决策制定能力
- 诊断结果
- 治疗程序
- 实验室检测订单
- 药物处方
#健康医疗 AI #AI 在医学领域

![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
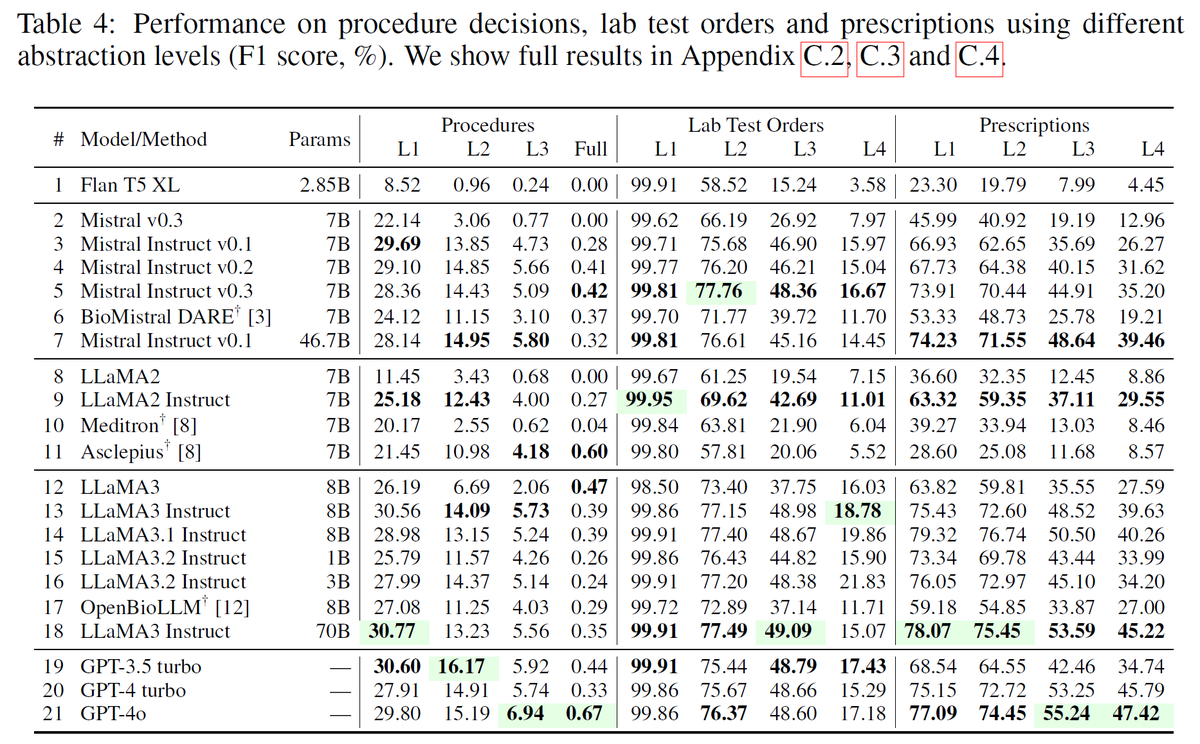
5/9 性能分析:
- 测试了像 gpt-4、LLaMA 和像 BioMistral 这样的医疗特定领域的模型。
- 发现突出了强项和改进的领域,模型在精细的医学任务中表现不佳。
#大语言模型验证 #人工智能研究

![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
6/9 CLIBENCH 独特之处在于:
- 它通过提供全面的评估,覆盖了所有关键临床决策,填补了当前 AI 医疗保健基准的空白。
- 它的多学科方法确保大语言模型被测试在现实世界临床实践中所涉及的全复杂性。
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
7/9 测试亮点:
零样本评估展示了大语言模型在临床应用中表现不佳,而微调模型在特定医学任务中的表现更好。
#AIperformance #健康医疗技术

零样本评估展示了大语言模型在临床应用中表现不佳,而微调模型在特定医学任务中的表现更好。
#AIperformance #健康医疗技术
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
8/9 未来前景:
- CLIBENCH 可以通过提供详细、实际的评估指标,指导未来开发稳健的临床 AI 系统。
- 支持训练数据的生成,以持续微调和提高模型性能。
#人工智能未来 #健康科技

- CLIBENCH 可以通过提供详细、实际的评估指标,指导未来开发稳健的临床 AI 系统。
- 支持训练数据的生成,以持续微调和提高模型性能。
#人工智能未来 #健康科技
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share
9/9 阅读完整论文:https://t.co/Poy7jRTljc
为了解决 AI 和大语言模型在医疗保健中的问题,加入我们的 500 多名专家社区!
- Discord: https://t.co/pVlzr5X2vK
- Substack(每周更新医疗 AI 和顶级研究论文): https://t.co/lbU9nDCLLl
- Youtube: https://t.co/4uudg0ot0A
- Spotify: https://t.co/jpPKL3JN7X
![]()
Tag
![]()
Favorite
![]()
Edit
![]()
Share