Reliably controlling AI systems much smarter than we are is an unsolved technical problem. And while it is a solvable problem, things could very easily go off the rails during a rapid intelligence explosion. Managing this will be extremely tense; failure could easily be catastrophic.
可靠地控制比我們聰明得多的人工智慧系統是一個尚未解決的技術問題。儘管這是一個可以解決的問題,但在快速的智能爆炸期間,事情很容易失控。管理這一過程將極其緊張;失敗很可能是災難性的。
The old sorcerer 老巫師
Johann Wolfgang von Goethe, “The Sorcerer’s Apprentice”
Has finally gone away! 終於走了!
Now the spirits he controls
現在他控制的靈魂
Shall obey my commands. 應遵從我的命令。
…
I shall work wonders too.
我也將創造奇蹟。
…
Sir, I’m in desperate straits!
先生,我陷入了絕境!
The spirits I summoned –
我召喚的靈魂——
I can’t get rid of them.
我無法擺脫他們。
約翰·沃爾夫岡·馮·歌德,《魔法師的學徒》
By this point, you have probably heard of the AI doomers. You might have been intrigued by their arguments, or you might have dismissed them off-hand. You’re loath to read yet another doom-and-gloom meditation.
到目前為止,你可能已經聽說過 AI 末日論者。你可能對他們的論點感到好奇,或者你可能一開始就把它們否定了。你不願再讀另一篇充滿末日預言的文章。
I am not a doomer.
我不是末日論者。錯位的超級智能可能不是最大的人工智慧風險。但我確實在過去一年中,作為我在 OpenAI 的日常工作,與 Ilya 和超級對齊團隊一起從事人工智慧系統對齊的技術研究。這裡有一個非常現實的技術問題:我們目前的對齊技術(確保我們能可靠地控制、引導和信任人工智慧系統的方法)無法擴展到超人類的人工智慧系統。我想做的是解釋我所認為的“默認”計劃,即我們將如何應對這一問題,以及為什麼我對此持樂觀態度。雖然目前關注這個問題的人還不夠多——我們應該有更雄心勃勃的努力來解決這個問題!——總的來說,我們在深度學習方面運氣不錯,有很多實證的低垂果實可以幫助我們走一部分路程,我們還將擁有數百萬自動化人工智慧研究員的優勢,幫助我們完成剩下的路程。
But I also want to tell you why I’m worried. Most of all, ensuring alignment doesn’t go awry will require extreme competence in managing the intelligence explosion. If we do rapidly transition from from AGI to superintelligence, we will face a situation where, in less than a year, we will go from recognizable human-level systems for which descendants of current alignment techniques will mostly work fine, to much more alien, vastly superhuman systems that pose a qualitatively different, fundamentally novel technical alignment problem; at the same time, going from systems where failure is low-stakes to extremely powerful systems where failure could be catastrophic; all while most of the world is probably going kind of crazy. It makes me pretty nervous.
但我也想告訴你為什麼我感到擔憂。最重要的是,確保對齊不出錯將需要在管理智能爆炸方面具備極高的能力。如果我們迅速從通用人工智能(AGI)過渡到超級智能,我們將面臨這樣一個情況:在不到一年的時間裡,我們將從可識別的人類水平系統(目前對齊技術的後代大多能夠正常運行)轉變為更加陌生、極其超人的系統,這些系統帶來質量上不同、根本上新穎的技術對齊問題;同時,從失敗風險較低的系統轉變為失敗可能帶來災難性後果的極其強大的系統;而此時,世界大部分地區可能都會變得有些瘋狂。這讓我非常緊張。
By the time the decade is out, we’ll have billions of vastly superhuman AI agents running around. These superhuman AI agents will be capable of extremely complex and creative behavior; we will have no hope of following along. We’ll be like first graders trying to supervise with multiple doctorates.
到這個十年結束時,我們將擁有數十億個極其超人的人工智慧代理在運行。這些超人 AI 代理將能夠展現極其複雜和創造性的行為;我們將無法跟上。我們就像小學生試圖監督擁有多個博士學位的人一樣。
In essence, we face a problem of handing off trust. By the end of the intelligence explosion, we won’t have any hope of understanding what our billion superintelligences are doing (except as they might choose to explain to us, like they might to a child). And we don’t yet have the technical ability to reliably guarantee even basic side constraints for these systems, like “don’t lie” or “follow the law” or “don’t try to exfiltrate your server”. Reinforcement from human feedback (RLHF) works very well for adding such side constraints for current systems—but RLHF relies on humans being able to understand and supervise AI behavior, which fundamentally won’t scale to superhuman systems.
本質上,我們面臨的是信任轉移的問題。到智慧爆炸結束時,我們將無法理解我們的數十億超級智慧在做什麼(除非它們選擇向我們解釋,就像它們可能會向孩子解釋一樣)。而且,我們目前還沒有技術能力可靠地保證這些系統的基本側面約束,比如“不要撒謊”或“遵守法律”或“不要嘗試滲透你的伺服器”。來自人類反饋的強化學習(RLHF)在為當前系統添加這些側面約束方面效果很好——但 RLHF 依賴於人類能夠理解和監督 AI 行為,這在根本上無法擴展到超人系統。
Simply put, without a very concerted effort, we won’t be able to guarantee that superintelligence won’t go rogue (and this is acknowledged by many leaders in the field). Yes, it may all be fine by default. But we simply don’t know yet. Especially once future AI systems aren’t just trained with imitation learning, but large-scale, long-horizon RL (reinforcement learning), they will acquire unpredictable behaviors of their own, shaped by a trial-and-error process (for example, they may learn to lie or seek power, simply because these are successful strategies in the real world!).
簡單來說,如果沒有非常一致的努力,我們將無法保證超級智能不會失控(這一點已被該領域的許多領導者所承認)。是的,默認情況下可能一切都會很好。但我們目前還不知道。特別是當未來的人工智能系統不僅僅是通過模仿學習進行訓練,而是通過大規模、長期的強化學習(RL)進行訓練時,它們將會獲得自己不可預測的行為,這些行為是通過試錯過程形成的(例如,它們可能會學會撒謊或尋求權力,僅僅因為這些在現實世界中是成功的策略!)。
The stakes will be high enough that hoping for the best simply isn’t a good enough answer on alignment.
賭注將會非常高,以至於僅僅希望最好的結果在對齊方面根本不是一個足夠好的答案。
The problem 問題
The superalignment problem
超級對齊問題
We’ve been able to develop a very successful method for aligning (i.e., steering/controlling) current AI systems (AI systems dumber than us!): Reinforcement Learning from Human Feedback (RLHF). The idea behind RLHF is simple: the AI system tries stuff, humans rate whether its behavior was good or bad, and then reinforce good behaviors and penalize bad behaviors. That way, it learns to follow human preferences.
我們已經能夠開發出一種非常成功的方法來調整(即引導/控制)當前的人工智慧系統(比我們笨的人工智慧系統!):從人類反饋中進行強化學習(RLHF)。RLHF 背後的理念很簡單:人工智慧系統嘗試一些東西,人類評價其行為是好是壞,然後強化好的行為並懲罰壞的行為。這樣,它就學會了遵循人類的偏好。
Indeed, RLHF has been the key behind the success of ChatGPT and others.
事實上,RLHF 是 ChatGPT 和其他成功的關鍵。基礎模型擁有大量的原始智慧,但默認情況下並未以有用的方式應用這些智慧;它們通常只是回應一堆類似隨機互聯網文本的混亂信息。通過 RLHF,我們可以引導它們的行為,灌輸基本的重要原則,如遵循指示和提供幫助。RLHF 也允許我們內置安全防護措施:例如,如果用戶要求我提供生化武器的製作方法,模型應該拒絕。
The core technical problem of superalignment is simple: how do we control AI systems (much) smarter than us?
超對齊的核心技術問題很簡單:我們如何控制比我們聰明(很多)的人工智慧系統?
RLHF will predictably break down as AI systems get smarter, and we will face fundamentally new and qualitatively different technical challenges. Imagine, for example, a superhuman AI system generating a million lines of code in a new programming language it invented. If you asked a human rater in an RLHF procedure, “does this code contain any security backdoors?” they simply wouldn’t know. They wouldn’t be able to rate the output as good or bad, safe or unsafe, and so we wouldn’t be able to reinforce good behaviors and penalize bad behaviors with RLHF.
隨著人工智慧系統變得越來越聰明,RLHF(強化學習與人類反饋)將可預見地崩潰,我們將面臨根本上全新且質量上不同的技術挑戰。想像一下,例如,一個超人類的人工智慧系統用它自己發明的新編程語言生成了一百萬行代碼。如果你在 RLHF 程序中問一個人類評估者,“這段代碼是否包含任何安全後門?”他們根本不會知道。他們無法評價這個輸出是好是壞,是安全還是不安全,因此我們無法通過 RLHF 來強化好的行為並懲罰壞的行為。

通過人類監督(如在 RLHF 中)對 AI 系統進行對齊無法擴展到超級智能。基於“從弱到強的泛化”的插圖。
Even now, AI labs already need to pay expert software engineers to give RLHF ratings for ChatGPT code—the code current models can generate is already pretty advanced! Human labeler-pay has gone from a few dollars for MTurk labelers to ~$100/hour for GPQA questions
What failure looks like
People too often just picture a “GPT-6 chatbot,” informing their intuitions that surely these wouldn’t be dangerously misaligned. As discussed previously in this series, the “unhobbling” trajectory points to agents, trained with RL, in the near future. I think Roger’s graphic gets it right:

One way to think of what we’re trying to accomplish with alignment, from the safety perspective, is add side-constraints. Consider a future powerful “base model” that, in a second stage of training, we train with long-horizon RL to run a business and make money
- By default, it may well learn to lie, to commit fraud, to deceive, to hack, to seek power, and so on—simply because these can be successful strategies to make money in the real world!8
- What we want is to add side-constraints: don’t lie, don’t break the law, etc.
- But here we come back to the fundamental issue of aligning superhuman systems: we won’t be able to understand what they are doing, and so we won’t be able to notice and penalize bad behavior with RLHF.9
If we can’t add these side-constraints, it’s not clear what will happen. Maybe we’ll get lucky and things will be benign by default (for example, maybe we can get pretty far without the AI systems having long-horizon goals, or the undesirable behaviors will be minor). But it’s also totally plausible they’ll learn much more serious undesirable behaviors: they’ll learn to lie, they’ll learn to seek power, they’ll learn to behave nicely when humans are looking and pursue more nefarious strategies when we aren’t watching, and so on.
The superalignment problem being unsolved means that we simply won’t have the ability to ensure even these basic side constraints for these superintelligence systems, like “will they reliably follow my instructions?” or “will they honestly answer my questions?” or “will they not deceive humans?”. People often associate alignment with some complicated questions about human values, or jump to political controversies, but deciding on what behaviors and values to instill in the model, while important, is a separate problem. The primary problem is that for whatever you want to instill the model (including ensuring very basic things, like “follow the law”!) we don’t yet know how to do that for the very powerful AI systems we are building very soon.
Again, the consequences of this aren’t totally clear. What is clear is that superintelligence will have vast capabilities—and so misbehavior could fairly easily be catastrophic. What’s more, I expect that within a small number of years, these AI systems will be integrated in many critical systems, including military systems (failure to do so would mean complete dominance by adversaries). It sounds crazy, but remember when everyone was saying we wouldn’t connect AI to the internet? The same will go for things like “we’ll make sure a human is always in the loop!”—as people say today.
Alignment failures then might look like isolated incidents, say, an autonomous agent committing fraud, a model instance self-exfiltrating, an automated researcher falsifying an experimental result, or a drone swarm overstepping rules of engagement. But failures could also be much larger scale or more systematic—in the extreme, failures could look more like a robot rebellion. We’ll have summoned a fairly alien intelligence, one much smarter than us, one whose architecture and training process wasn’t even designed by us but some super-smart previous generation of AI systems, one where we can’t even begin to understand what they’re doing, it’ll be running our military, and its goals will have been learned by a natural-selection-esque process.
Unless we solve alignment—unless we figure out how to instill those side-constraints—there’s no particular reason to expect this small civilization of superintelligences will continue obeying human commands in the long run. It seems totally within the realm of possibilities that at some point they’ll simply conspire to cut out the humans, whether suddenly or gradually.
The intelligence explosion makes this all incredibly tense
I am optimistic that superalignment is a solvable technical problem. Just like we developed RLHF, so we can develop the successor to RLHF for superhuman systems and do the science that gives us high confidence in our methods. If things continue to progress iteratively, if we insist on rigorous safety testing and so on, it should all be doable (and I’ll discuss my current best-guess of how we’ll muddle through more in a bit).
What makes this incredibly hair-raising is the possibility of an intelligence explosion: that we might make the transition from roughly human-level systems to vastly superhuman systems extremely rapidly, perhaps in less than a year:

- We will extremely rapidly go from systems where RLHF works fine—to systems where it will totally break down. This leaves us extremely little time to iteratively discover and address ways in which our current methods will fail.
- At the same time, we will extremely rapidly go from systems where failures are fairly low-stakes (ChatGPT said a bad word, so what)—to extremely high-stakes (oops, the superintelligence self-exfiltrated from our cluster, now it’s hacking the military). Rather than iteratively encountering increasingly more dangerous safety failures in the wild, the first notable safety failures we encounter might already be catastrophic.
- The superintelligence we get by the end of it will be vastly superhuman. We’ll be entirely reliant on trusting these systems, and trusting what they’re telling us is going on—since we’ll have no ability of our own to pierce through what exactly they’re doing anymore.
- The superintelligence we get by the end of it could be quite alien. We’ll have gone through a decade or more of ML advances during the intelligence explosion, meaning the architectures and training algorithms will be totally different (with potentially much riskier safety properties).
到最後我們得到的超級智能可能會相當陌生。我們將經歷十年或更長時間的機器學習進步,這意味著在智能爆炸期間,架構和訓練算法將完全不同(可能具有更高的安全風險)。- One example that’s very salient to me: we may well bootstrap our way to human-level or somewhat-superhuman AGI with systems that reason via chains of thoughts, i.e. via English tokens. This is extraordinarily helpful, because it means the models “think out loud” letting us catch malign behavior (e.g., if it’s scheming against us). But surely having AI systems think in tokens is not the most efficient means to do it, surely there’s something much better that does all of this thinking via internal states—and so the model by the end of the intelligence explosion will almost certainly not think out loud, i.e. will have completely uninterpretable reasoning.
對我來說,一個非常顯著的例子是:我們很可能通過使用以思維鏈為基礎的系統來實現人類水平或稍微超人水平的人工智慧,即通過英語標記。這是非常有幫助的,因為這意味著模型“公開思考”,讓我們能夠抓住惡意行為(例如,如果它在策劃對付我們)。但毫無疑問,讓人工智慧系統以標記進行思考並不是最有效的方式,肯定有更好的方法通過內部狀態進行所有這些思考——因此,模型在智慧爆炸結束時幾乎肯定不會公開思考,即其推理將完全無法解釋。
- One example that’s very salient to me: we may well bootstrap our way to human-level or somewhat-superhuman AGI with systems that reason via chains of thoughts, i.e. via English tokens. This is extraordinarily helpful, because it means the models “think out loud” letting us catch malign behavior (e.g., if it’s scheming against us). But surely having AI systems think in tokens is not the most efficient means to do it, surely there’s something much better that does all of this thinking via internal states—and so the model by the end of the intelligence explosion will almost certainly not think out loud, i.e. will have completely uninterpretable reasoning.
- This will be an incredibly volatile period, potentially with the backdrop of an international arms race, tons of pressure to go faster, wild new capabilities advances every week with basically no human-time to make good decisions, and so on. We’ll face tons of ambiguous data and high-stakes decisions.
這將是一個極其動盪的時期,可能伴隨著國際軍備競賽的背景,巨大的壓力要求更快的速度,每週都有驚人的新能力進展,基本上沒有時間做出明智的決定,等等。我們將面臨大量模糊的數據和高風險的決策。- Think: “We caught the AI system doing some naughty things in a test, but we adjusted our procedure a little bit to hammer that out. Our automated AI researchers tell us the alignment metrics look good, but we don’t really understand what’s going on and don’t fully trust them, and we don’t have any strong scientific understanding that makes us confident this will continue to hold for another couple OOMs. So, we’ll probably be fine? Also China just stole our weights and they’re launching their own intelligence explosion, they’re right on our heels.”
想想看:「我們在測試中抓到 AI 系統做了一些不好的事情,但我們稍微調整了程序來解決這個問題。我們的自動化 AI 研究人員告訴我們,對齊指標看起來不錯,但我們真的不明白發生了什麼,也不完全信任它們,而且我們沒有任何強有力的科學理解讓我們有信心這在接下來的幾個 OOM 中會繼續保持。所以,我們可能會沒事吧?另外,中國剛剛偷了我們的權重,他們正在啟動自己的智能爆炸,他們就在我們的後面。」
- Think: “We caught the AI system doing some naughty things in a test, but we adjusted our procedure a little bit to hammer that out. Our automated AI researchers tell us the alignment metrics look good, but we don’t really understand what’s going on and don’t fully trust them, and we don’t have any strong scientific understanding that makes us confident this will continue to hold for another couple OOMs. So, we’ll probably be fine? Also China just stole our weights and they’re launching their own intelligence explosion, they’re right on our heels.”
It just really seems like this could go off the rails. To be honest, it sounds terrifying.
這真的看起來像是會失控。老實說,這聽起來很可怕。
Yes, we will have AI systems to help us. Just like they’ll automate capabilities research, we can use them to automate alignment research. That will be key, as I discuss below. But—can you trust the AI systems? You weren’t sure whether they were aligned in the first place—are they actually being honest with you about their claims about alignment science? Will automated alignment research be able to keep up with automated capabilities research (for example, because automating alignment is harder, e.g. because there are less clear metrics we can trust compared to improving model capabilities, or there’s a lot of pressure to go full-speed on capabilities progress because of the international race)? And AI won’t be able to fully substitute for the still-human decision makers making good calls in this incredibly high-stakes situation.
是的,我們將有人工智慧系統來幫助我們。就像它們會自動化能力研究一樣,我們可以用它們來自動化對齊研究。這將是關鍵,正如我在下面討論的那樣。但是——你能信任這些人工智慧系統嗎?你一開始就不確定它們是否對齊——它們關於對齊科學的聲明是否真的誠實?自動化的對齊研究能否跟上自動化的能力研究(例如,因為自動化對齊更困難,例如我們可以信任的指標比改進模型能力的指標更不明確,或者因為國際競賽的壓力而全速推進能力進展)?而且人工智慧無法完全取代在這種極高風險情況下做出良好決策的仍然是人類的決策者。
The default plan: how we can muddle through
默認計劃:我們如何應對困境
Ultimately, we are going to need to solve alignment for vastly superhuman, fairly alien superintelligence. Maybe, somewhere, there is a once-and-for-all, simple solution to aligning superintelligence. But my strong best guess is that we’ll get there by muddling through.
最終,我們將需要解決對極度超人類、相當外星的超級智能的對齊問題。也許,在某個地方,有一個一勞永逸的簡單解決方案來對齊超級智能。但我強烈的最佳猜測是,我們將通過摸索前進來達到那裡。
I think we can harvest wins across a number of empirical bets, which I’ll describe below, to align somewhat-superhuman systems. Then, if we’re confident we can trust these systems, we’ll need to use these somewhat-superhuman systems to automate alignment research—alongside the automation of AI research in general, during the intelligence explosion—to figure out how to solve alignment to go the rest of the way, all the way to vastly superhuman, fairly alien superintelligence.
我認為我們可以通過一些經驗性賭注來獲得勝利,這些賭注我將在下面描述,以對齊某些超人系統。然後,如果我們有信心可以信任這些系統,我們將需要使用這些某些超人系統來自動化對齊研究——在智能爆炸期間,與一般的人工智能研究自動化一起——以弄清楚如何解決對齊問題,走完剩下的路,直到達到極其超人、相當外星的超級智能。
Aligning somewhat-superhuman models
對齊有些超人模型
Aligning human-level systems won’t be enough. Even the first systems that can do automated AI research, i.e. start the intelligence explosion, will likely already be substantially superhuman in many domains. This is because AI capabilities are likely to be somewhat spikey—by the time AGI is human-level at whatever a human AI researcher/engineer is worst at, it’ll be superhuman at many other things. For example, perhaps the ability for AI systems to effectively coordinate and plan lags behind, meaning that by the time the intelligence explosion is in full force they’ll probably already be superhuman coders, submitting million-line pull requests in new programming languages they devised, and they’ll be superhuman at math and ML.
僅僅使人類水平的系統對齊是不夠的。即使是能夠進行自動化人工智慧研究的第一批系統,即啟動智慧爆炸的系統,也很可能已經在許多領域顯著超越人類。這是因為人工智慧的能力可能會有些不均衡——當通用人工智慧在某些人類人工智慧研究員/工程師最不擅長的領域達到人類水平時,它在許多其他方面將會是超人類的。例如,人工智慧系統有效協調和計劃的能力可能會滯後,這意味著當智慧爆炸全面展開時,它們可能已經是超人類的程式設計師,能夠在它們設計的新程式語言中提交數百萬行的拉取請求,而且它們在數學和機器學習方面也將是超人類的。
These early-intelligence-explosion-systems will start being quantitatively and qualitatively superhuman, at least in many domains. But they’ll look much closer to the systems we have today in terms of architecture, and the intelligence gap we need to cover is much more manageable. (Perhaps if humans trying to align true superintelligence is like a first grader trying to supervise a PhD graduate, this is more like a smart high schooler trying to supervise a PhD graduate.)
這些早期的智慧爆炸系統在許多領域將開始在數量和質量上超越人類。但就架構而言,它們看起來會更接近我們今天擁有的系統,而我們需要彌補的智慧差距也更容易管理。(也許如果人類試圖調整真正的超級智慧就像一年級生試圖監督博士畢業生一樣,這更像是一個聰明的高中生試圖監督博士畢業生。)
More generally, the more we can develop good science now, the more we’ll be in a position to verify that things aren’t going off the rails during the intelligence explosion. Even having good metrics we can trust for superalignment is surprisingly difficult—but without reliable metrics during the intelligence explosion, we won’t know whether pressing on is safe or not.
更普遍地說,我們現在能夠發展出越多的良好科學,我們就越能夠在智慧爆炸期間驗證事情是否沒有偏離軌道。即使是擁有我們可以信任的超對齊良好指標也出乎意料地困難——但在智慧爆炸期間沒有可靠的指標,我們將無法知道繼續前進是否安全。
Here are some of the main research bets I see for crossing the gap between human-level and somewhat-superhuman systems:
以下是我認為在跨越人類水平和某種超人系統之間的主要研究賭注:
Evaluation is easier than generation. We get some of the way “for free,” because it’s easier for us to evaluate outputs (especially for egregious misbehaviors) than it is to generate them ourselves. For example, it takes me months or years of hard work to write a paper, but only a couple hours to tell if a paper someone has written is any good (though perhaps longer to catch fraud). We’ll have teams of expert humans spend a lot of time evaluating every RLHF example, and they’ll be able to “thumbs down” a lot of misbehavior even if the AI system is somewhat smarter than them. That said, this will only take us so far (GPT-2 or even GPT-3 couldn’t detect nefarious GPT-4 reliably, even though evaluation is easier than generation!)
評估比生成更容易。我們在某些方面可以「免費」獲得一些進展,因為評估輸出(尤其是明顯的錯誤行為)比自己生成它們要容易。例如,我需要幾個月或幾年的努力才能寫出一篇論文,但只需要幾個小時就能判斷別人寫的論文是否好(雖然可能需要更長時間來發現欺詐行為)。我們將有專家團隊花大量時間評估每個 RLHF 示例,即使 AI 系統比他們聰明一些,他們也能對很多錯誤行為「點踩」。話雖如此,這只能帶我們走到某個程度(即使評估比生成更容易,GPT-2 甚至 GPT-3 也無法可靠地檢測到惡意的 GPT-4!)
Scalable oversight. We can use AI assistants to help humans supervise other AI systems—the human-AI team being able to extend supervision farther than the human could alone. For example, imagine an AI system generates 1M lines of complex code. It’s easier for a human to double-check that a given line of code has a bug if an AI assistant has pointed out that (say) line 394,894 looks fishy, than it is for a human to find that same bug from scratch. A model trained to critique the code written by another model could thus help humans supervise a system with narrowly superhuman coding abilities.
可擴展的監督。我們可以使用人工智慧助手來幫助人類監督其他人工智慧系統——人類與人工智慧的團隊能夠比人類單獨延伸監督範圍更遠。例如,想像一個人工智慧系統生成了 100 萬行複雜的代碼。如果人工智慧助手指出第 394,894 行看起來有問題,那麼人類要檢查這行代碼是否有錯誤就會比從頭開始找同樣的錯誤容易得多。一個被訓練來批評另一個模型所寫代碼的模型,因而可以幫助人類監督一個具有狹義超人類編碼能力的系統。
Several scalable oversight strategies have been proposed, including debate, market-making, recursive reward modeling, and prover-verifier games, as well as simplified versions of those ideas like critiques. Models are now strong enough that it’s possible to empirically test these ideas, making direct progress on scalable oversight.
已提出了幾種可擴展的監督策略,包括辯論、市場創造、遞歸獎勵建模和證明者-驗證者遊戲,以及這些想法的簡化版本,如批評。模型現在已經足夠強大,可以實證測試這些想法,直接在可擴展監督方面取得進展。
I expect this to help a lot for the “quantitatively” superhuman part of the problem, such as the aforementioned million-lines of code example. But I am less optimistic that scalable oversight techniques can really help for the “qualitatively” superhuman part of the problem—imagine the model invents quantum physics when you only understand Newtonian physics.
我期望這能在“量化”超人部分的問題上幫助很大,例如前面提到的百萬行代碼的例子。但我對可擴展的監督技術能否真正幫助“質化”超人部分的問題則不太樂觀——想像一下,當你只理解牛頓物理學時,模型發明了量子物理學。
Generalization. Even with scalable oversight, we won’t be able to supervise AI systems on really hard problems, problems beyond human comprehension. However, we can study: how will the AI systems generalize from human supervision on easy problems (that we do understand and can supervise) to behave on the hard problems (that we can’t understand and can no longer supervise)? For example, perhaps supervising a model to be honest in simple cases generalizes benignly to the model just being honest in general, even in cases where it’s doing extremely complicated things we don’t understand.
概括。即使有可擴展的監督,我們也無法在真正困難的問題上監督人工智慧系統,這些問題超出了人類的理解範圍。然而,我們可以研究:人工智慧系統如何從人類監督的簡單問題(我們理解並能夠監督的問題)中概括出來,並在困難問題上(我們無法理解且無法再監督的問題)表現?例如,也許在簡單情況下監督模型誠實行事,會良性地概括為模型在一般情況下都誠實,即使在它處理我們無法理解的極其複雜的事情時也是如此。
There’s a lot of reasons to be optimistic here: part of the magic of deep learning is that it often generalizes in benign ways (for example, RLHF’ing with only labels on English examples also tends to produce good behavior when it’s speaking French or Spanish, even if that wasn’t part of the training). I’m fairly optimistic that there will both be pretty simple methods that help nudge the models’ generalization in our favor, and that we can develop a strong scientific understanding that helps us predict when generalization will work and when it will fail. To a greater extent that for scalable oversight, the hope is that this will help with alignment even in the “qualitatively” superhuman case.
這裡有很多理由讓人感到樂觀:深度學習的神奇之處在於它經常以良性的方式進行泛化(例如,僅使用英語範例的標籤進行 RLHF 也往往會在講法語或西班牙語時產生良好的行為,即使這不是訓練的一部分)。我相當樂觀地認為,會有一些相當簡單的方法可以幫助推動模型的泛化朝有利於我們的方向發展,而且我們可以發展出強有力的科學理解,幫助我們預測泛化何時會成功,何時會失敗。比起可擴展監督,這種希望在“質量上”超人類的情況下也能幫助實現對齊。
Here’s another way of thinking about this: if a superhuman model is misbehaving, say breaking the law, intuitively the model should already know that it’s breaking the law. Moreover, “is this breaking the law” is probably a pretty natural concept to the model—and it will be salient in the model’s representation space. The question then is: can we “summon” this concept from the model with only weak supervision?
這裡有另一種思考方式:如果一個超人模型行為不端,比如違法,直覺上這個模型應該已經知道它在違法。此外,“這是否違法”對於模型來說可能是一個相當自然的概念——而且這個概念在模型的表示空間中會很突出。那麼問題是:我們能否僅通過弱監督來“召喚”這個概念?
I’m particularly partial to this direction (and perhaps biased), because I helped introduce this with some recent work with some colleagues at OpenAI. In particular, we studied an analogy to the problem of humans supervising superhuman systems—can a small model align a larger (smarter) model? We found that generalization does actually get you cross some (but certainly not all) of the intelligence gap between supervisor and supervisee, and that in simple settings there’s a lot you can do to improve it.
我特別偏愛這個方向(也許有些偏見),因為我和一些在 OpenAI 的同事最近的工作幫助引入了這個方向。特別是,我們研究了一個類比於人類監督超人系統的問題——小模型能否對齊更大(更聰明)的模型?我們發現,泛化確實能夠跨越監督者和被監督者之間的一部分(但肯定不是全部)智力差距,而且在簡單的設置中,有很多方法可以改進它。
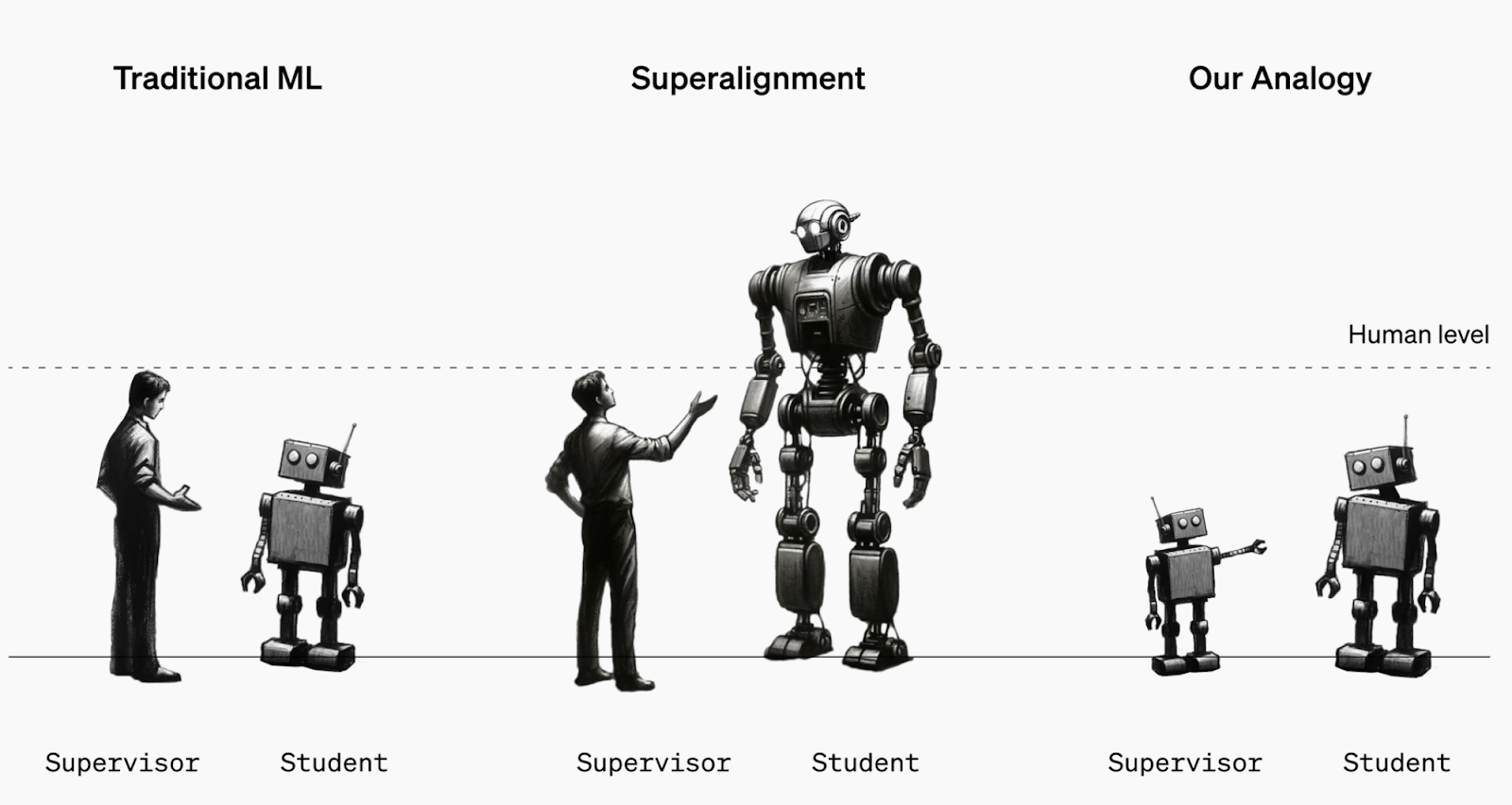
一個研究超對齊的簡單類比:與其讓人類監督超人類模型,我們可以研究小模型監督大模型。例如,我們能否僅通過 GPT-2 的監督來對齊 GPT-4?這樣會導致 GPT-4 適當地概括“GPT-2 的意思”嗎?從弱到強的概括。.
Interpretability. One intuitively-attractive way we’d hope to verify and trust that our AI systems are aligned is if we could understand what they’re thinking! For example, if we’re worried that AI systems are deceiving us or conspiring against us, access to their internal reasoning should help us detect that.
可解釋性。一種直觀吸引人的方式來驗證和信任我們的人工智慧系統是否對齊,是如果我們能夠理解它們在想什麼!例如,如果我們擔心人工智慧系統在欺騙我們或密謀反對我們,了解它們的內部推理應該能幫助我們檢測到這一點。
By default, modern AI systems are inscrutable black boxes. Yet it seems like we should be able to do amazing “digital neuroscience”—after all, we have perfect access to model internals.
默認情況下,現代人工智慧系統是難以理解的黑箱。然而,我們似乎應該能夠進行驚人的“數位神經科學”——畢竟,我們可以完美地訪問模型內部。
There’s a few different approaches here, going from “most ambitious and ‘cool’ but will be very hard” to “hackier things that are easier and might just work”:
這裡有幾種不同的方法,從「最有野心和‘酷’但會非常困難」到「更簡單且可能有效的臨時解決方案」:
Mechanistic interpretability. Try to fully reverse-engineer large neural networks from the ground up—fully disentangle the inscrutable matrices, so to speak.
機制可解釋性。嘗試從頭開始完全逆向工程大型神經網絡——完全解開那些難以理解的矩陣。
Chris Olah’s team at Anthropic has done much of the pioneering work on this, starting by understanding simple mechanisms in very small models. There’s incredibly exciting progress happening recently, and I’m thrilled about the overall level of activity in this space.
Chris Olah 在 Anthropic 的團隊在這方面做了很多開創性的工作,首先是理解非常小的模型中的簡單機制。最近有令人難以置信的令人興奮的進展,我對這個領域的整體活動水平感到非常興奮。
That said, I’m worried fully reverse-engineering superhuman AI systems will just be an intractable problem—similar, to, say “fully reverse engineering the human brain”—and I’d put this work mostly in the “ambitious moonshot for AI safety” rather than “default plan for muddling through” bucket.
話雖如此,我擔心完全逆向工程超人類 AI 系統將是一個難以解決的問題——類似於“完全逆向工程人類大腦”——我會將這項工作主要歸類為“AI 安全的雄心壯志”而不是“混過去的默認計劃”。
(Neel Nanda’s 200 open problems in mechanistic interpretability also gives a flavor of this kind of research.)
尼爾·南達的《機械解釋的 200 個未解決問題》也給這類研究提供了一個概念。
“Top-down” interpretability. If mechanistic interpretability tries to reverse engineer neural networks “from the bottom up,” other work takes a more targeted, “top-down” approach, trying to locate information in a model without full understanding of how it is processed.
「自上而下」的可解釋性。如果機械可解釋性試圖「自下而上」地逆向工程神經網絡,其他工作則採取更有針對性的「自上而下」方法,試圖在不完全理解其處理方式的情況下定位模型中的信息。
For example, we might try to build an “AI lie detector” by identifying the parts of the neural net that “light up” when an AI system is lying. This can be a lot more tractable (even if it gives less strong guarantees).
例如,我們可能會嘗試通過識別神經網絡在 AI 系統說謊時“亮起”的部分來構建一個“AI 測謊儀”。這可能更容易實現(即使它提供的保證不那麼強)。
Over the past couple of years, there’s been a flurry of exciting work in this area. CCS is able to identify a “truth direction” in models with only unsupervised data.
在過去的幾年裡,這個領域出現了一系列令人興奮的工作。CCS 能夠在僅有無監督數據的情況下識別模型中的“真實方向”。ROME 能夠識別模型中知道艾菲爾鐵塔在巴黎的部分,然後直接編輯模型的知識,將艾菲爾鐵塔放置在羅馬。表示工程和推理時間干預展示了使用自上而下的技術來檢測謊言和幻覺,並外科手術般地控制模型在越獄、尋求權力、公平性、真實性等方面的行為。還有其他創意性的謊言檢測工作,甚至不需要模型內部結構。
I’m increasingly bullish that top-down interpretability techniques will be a powerful tool—i.e., we’ll be able to build something like an “AI lie detector”—and without requiring fundamental breakthroughs in understanding neural nets.
我越來越看好自上而下的可解釋性技術將成為一個強大的工具——也就是說,我們將能夠構建類似於“AI 測謊儀”的東西——而且不需要在理解神經網絡方面取得根本性的突破。
Chain-of-thought interpretability. As mentioned earlier, I think it’s quite plausible that we’ll bootstrap our way to AGI with systems that “think out loud” via chains of thought. Even if it’s not the most efficient algorithm in the limit (I’d be very surprised if superintelligence still used English-chain-of-thought, rather than thinking via some sort of recurrent internal states), we may well still benefit from this property for the first AGIs. This would be an incredible boon for interpretability: we’d have access to the AGI’s “internal monologue”! That would make it relatively easy to detect egregious alignment failures.
連鎖思維的可解釋性。如前所述,我認為我們很有可能通過“連鎖思維”系統來引導我們走向通用人工智慧(AGI)。即使這在極限情況下不是最有效的算法(如果超級智慧仍然使用英語連鎖思維,而不是通過某種循環內部狀態進行思考,我會非常驚訝),我們仍然可能從這一特性中受益,至少在第一代 AGI 中。這對於可解釋性來說將是一個難以置信的福音:我們將能夠訪問 AGI 的“內部獨白”!這將使檢測嚴重的對齊失敗變得相對容易。
There’s a ton of work to do here, however, if we wanted to rely on this. How do we ensure that the CoT remains legible? (It may simply drift from understandable English to unintelligible model-speak, depending on how we e.g. use RL to train models—can we add some simple constraints to ensure it remains legible?) How do we ensure the CoT is faithful, i.e. actually reflects what models are thinking? (E.g, there’s some work that shows in certain situations, models will just make up posthoc reasoning in their CoT that don’t actually reflect their actual internal reasoning for an answer.)
這裡有很多工作要做,然而,如果我們想依賴這個。我們如何確保 CoT 保持可讀性?(它可能會從可理解的英語漂移到難以理解的模型語言,這取決於我們如何使用 RL 來訓練模型——我們能否添加一些簡單的約束來確保它保持可讀性?)我們如何確保 CoT 是忠實的,即實際反映模型的思考?(例如,有些研究顯示在某些情況下,模型會在它們的 CoT 中編造事後推理,這些推理並不實際反映它們對答案的內部推理。)
My best guess is that some simple measurement of legibility and faithfulness, and some simple hacks to preserve legibility and faithfulness longer, could go quite far. Yes, this won’t work in some worlds, and it’s a bit of a simple hack, but it’s such low-hanging fruit; this direction is criminally underrated in my view.
我最好的猜測是,一些簡單的可讀性和忠實度的測量,以及一些簡單的技巧來更長時間地保持可讀性和忠實度,可能會有很大的效果。是的,這在某些情況下不起作用,而且這有點像是一個簡單的技巧,但這是如此容易實現的方向;在我看來,這個方向被嚴重低估了。
Adversarial testing and measurements. Along the way, it’s going to be critical to stress test the alignment of our systems at every step—our goal should be to encounter every failure mode in the lab before we encounter it in the wild. This will require substantially advancing techniques for automated red-teaming. For example, if we deliberately plant backdoors or misalignments into models, would our safety training would have caught and gotten rid of them? (Early work suggests that “sleeper agents” can survive through safety training, for example.)
對抗性測試和測量。在此過程中,關鍵是在每一步都對我們的系統進行壓力測試——我們的目標應該是在實驗室中遇到每一種失敗模式,而不是在實際環境中遇到它們。這將需要大幅推進自動化紅隊技術。例如,如果我們故意在模型中植入後門或錯誤對齊,我們的安全訓練是否能夠發現並消除它們?(早期的工作表明,“潛伏特工”可以在安全訓練中存活下來,例如。)
More generally, it’ll be critical to have good measurements of alignment along the way. Does the model have the power to be misaligned? For example, does it have long-horizon goals, and what sorts of drives it is learning? And what are clear “red lines”? For example, a very intuitive bound might be “model reasoning (chain of thoughts) always has to remain legible and faithful.” (As Eric Schmidt says, the point at which AI agents can talk to each other in a language we can’t understand, we should unplug the computers.) Another might be developing better measurements for whether models are being fully honest.
更普遍地說,沿途有良好的對齊測量將是至關重要的。模型是否有可能被錯誤對齊?例如,它是否有長期目標,以及它正在學習什麼樣的驅動力?什麼是明確的“紅線”?例如,一個非常直觀的界限可能是“模型推理(思維鏈)必須始終保持可讀性和忠實性。”(正如埃里克·施密特所說,當人工智慧代理可以用我們無法理解的語言互相交談時,我們應該拔掉電腦的插頭。)另一個可能是開發更好的測量方法,以確定模型是否完全誠實。
The science of measuring alignment is still in its infancy; improving this will be critical for helping us make the right tradeoffs on risk during the intelligence explosion. Doing the science that lets us measure alignment and gives us an understanding of “what evidence would be sufficient to assure us that the next OOM into superhuman territory is safe?” is among the very-highest priority work for alignment research today (beyond just work that tries to extend RLHF further to “somewhat-superhuman” systems).
衡量對齊的科學仍處於起步階段;改進這一點對於幫助我們在智能爆炸期間做出正確的風險權衡至關重要。進行能讓我們衡量對齊並讓我們理解“什麼證據足以保證我們下一個進入超人領域的 OOM 是安全的?”的科學研究,是當今對齊研究中最優先的工作之一(超越僅僅試圖將 RLHF 擴展到“某種程度上的超人”系統的工作)。
See also this writeup of superalignment research directions for the Superalignment Fast Grants call-for-proposals.
另請參閱有關超對齊研究方向的報告,以應對超對齊快速資助的提案徵集。
Automating alignment research
自動化對齊研究
Ultimately, we’re going to need to automate alignment research. There’s no way we’ll manage to solve alignment for true superintelligence directly; covering that vast of an intelligence gap seems extremely challenging. Moreover, by the end of the intelligence explosion—after 100 million automated AI researchers have furiously powered through a decade of ML progress—I expect much more alien systems in terms of architecture and algorithms compared to current system (with potentially less benign properties, e.g. on legibility of CoT, generalization properties, or the severity of misalignment induced by training).
最終,我們將需要自動化對齊研究。我們不可能直接解決真正超級智能的對齊問題;彌合如此巨大的智能差距似乎極具挑戰性。此外,在智能爆炸結束時——在 1 億名自動化 AI 研究人員經過十年的機器學習進展後——我預計在架構和算法方面會出現更多異質系統,與當前系統相比(可能具有較少的良性屬性,例如在連貫性、泛化屬性或訓練引起的錯位嚴重性方面)。
But we also don’t have to solve this problem just on our own. If we manage to align somewhat-superhuman systems enough to trust them, we’ll be in an incredible position: we’ll have millions of automated AI researchers, smarter than the best AI researchers, at our disposal. Leveraging these army of automated researchers properly to solve alignment for even-more superhuman systems will be decisive.
但我們也不必單靠自己來解決這個問題。如果我們能夠使某些超人系統足夠信任,我們將處於一個令人難以置信的位置:我們將擁有數百萬個自動化的 AI 研究員,比最優秀的 AI 研究員還要聰明,供我們使用。適當地利用這些自動化研究員來解決更超人系統的對齊問題將是決定性的。
(This applies more generally, by the way, for the full spectrum of AI risks, including misuse and so on. The best route—perhaps the only route—to AI safety in all of these cases, will involve properly leveraging early AGIs for safety; for example, we should put a bunch of them to work on automated research to improve security against foreign actors exfiltrating weights, others on shoring up defenses against worst-case bioattacks, and so on.)
順便說一下,這更普遍地適用於整個範圍的人工智慧風險,包括濫用等。在所有這些情況下,通往人工智慧安全的最佳途徑——或許是唯一途徑——將涉及適當利用早期的人工智慧來確保安全;例如,我們應該讓一群人工智慧從事自動化研究,以提高對外國行為者竊取權重的安全性,另一些則用於加強對最壞情況生物攻擊的防禦,等等。
Getting automated alignment right during the intelligence explosion will be extraordinarily high-stakes: we’ll be going through many years of AI advances in mere months, with little human-time to make the right decisions, and we’ll start entering territory where alignment failures could be catastrophic. Labs should be willing to commit a large fraction of their compute to automated alignment research (vs. automated capabilities research) during the intelligence explosion, if necessary. We’ll need strong guarantees that let us trust the automated alignment research being produced and much better measurements than we have today for misalignment to know whether we’re still in the clear. For every OOM we want to ascend, we will need to have extremely high confidence in our alignment approaches for that next OOM.
在智能爆炸期間,實現自動化對齊將是極其高風險的:我們將在短短幾個月內經歷多年 AI 的進步,幾乎沒有時間讓人類做出正確的決定,我們將開始進入對齊失敗可能帶來災難性後果的領域。實驗室應該願意在智能爆炸期間將大量計算資源投入到自動化對齊研究(相對於自動化能力研究)中,如果有必要的話。我們需要強有力的保證,讓我們信任所產生的自動化對齊研究,並且需要比現在更好的錯位測量方法,以確保我們仍然處於安全狀態。對於每一個我們想要提升的數量級,我們需要對下一個數量級的對齊方法有極高的信心。
Most of all, getting this right will require an extreme degree of competence, seriousness, and willingness to make hard tradeoffs. Once we’re approaching true superintelligence, the stakes get very real, and failure—rogue AI—could be catastrophic. There will be moments with ambiguous evidence, when metrics will superficially look ok, but there are some warning signs that hint at looming danger, and we mostly don’t have a clue what’s going on anymore. Navigating this situation responsibly will require making very costly tradeoffs. Eventually, the decision to greenlight the next generation of superintelligence will need to be taken as seriously as the decision to launch a military operation.
最重要的是,要做到這一點需要極高的能力、嚴肅性和願意做出艱難取捨的意願。一旦我們接近真正的超級智能,風險就會變得非常現實,失敗——流氓人工智能——可能會帶來災難性後果。會有一些證據模糊的時刻,當指標表面上看起來沒問題,但有一些警告信號暗示著迫在眉睫的危險,而我們大多數人根本不知道發生了什麼。負責任地應對這種情況需要做出非常昂貴的取捨。最終,批准下一代超級智能的決定需要像啟動軍事行動的決定一樣認真對待。
Superdefense 超級防禦
“Getting alignment right” should only be the first of many layers of defense during the intelligence explosion. Alignment will be hard; there will be failures along the way. If at all possible, we need to be in a position where alignment can fail—but failure wouldn’t be catastrophic. This could mean:
「確保對齊正確」應該只是情報爆炸期間眾多防禦層中的第一層。對齊將會很困難;在這過程中會有失敗。如果可能的話,我們需要處於一個即使對齊失敗也不會造成災難的狀態。這可能意味著:
- Security. An airgapped cluster is the first layer of defense against superintelligence attempting to self-exfiltrate and doing damage in the real world. And that’s only the beginning; we’ll need much more extreme security against model self-exfiltration13 across the board, from hardware encryption to many-key signoff.14 And once our AGIs can do automated R&D, we should put them to work on further hardening security as well.
安全性。隔離網絡的集群是防止超級智能嘗試自我外洩並在現實世界中造成損害的第一道防線。而這僅僅是開始;我們需要在各方面對模型自我外洩採取更極端的安全措施,從硬體加密到多密鑰簽署。一旦我們的人工通用智能能夠進行自動化研發,我們應該讓它們也參與進一步強化安全性。 - Monitoring. If our AI systems are up to something fishy or malevolent—or a rogue employee tries to use them for unauthorized activities—we need to be able to catch it. However, this is not a trivial task: we will have millions of AGI instances running our cluster, executing complex code and so on. We will need advanced monitoring systems that leverage the models themselves, including monitoring model outputs, chains of thought, model-written code, server/network activity, and interactions with researchers/other humans; essentially, leveraging some AI systems to nark on other AI systems. Moreover, we’ll want to develop and employ sophisticated “control” protocols, using less powerful but trusted models to protect against subversion from more powerful but less trusted models. This may require, for example, dedicating the same amount of compute to monitoring model instances as to compute for active model instances.
監控。如果我們的人工智慧系統有任何可疑或惡意行為,或者有員工試圖利用它們進行未經授權的活動,我們需要能夠及時發現。然而,這並不是一項簡單的任務:我們的集群中將運行數百萬個 AGI 實例,執行複雜的代碼等。我們將需要先進的監控系統,利用模型本身,包括監控模型輸出、思維鏈、模型編寫的代碼、伺服器/網絡活動以及與研究人員/其他人類的互動;基本上,就是利用一些人工智慧系統來監控其他人工智慧系統。此外,我們還需要開發和採用複雜的“控制”協議,使用較不強大但可信的模型來防止更強大但不太可信的模型的顛覆。例如,這可能需要分配與活動模型實例相同數量的計算資源來監控模型實例。 - Targeted capability limitations. As much as possible, we should try to limit the model’s capabilities in targeted ways that reduce fallout from failure. A central example of this might be scrubbing everything related to biology and chemistry from model training (or using “unlearning” techniques); this helps cut off paths to catastrophic real world damage that occur via biological and chemical weapons
針對性能力限制。我們應該盡可能以針對性的方式限制模型的能力,以減少失敗帶來的影響。一個核心例子可能是從模型訓練中刪除所有與生物學和化學相關的內容(或使用“去學習”技術);這有助於切斷通過生物和化學武器造成現實世界災難的途徑。 - Targeted training method restrictions. There are likely some ways of training models that are inherently riskier—more likely to produce severe misalignments—than others. For example, imitation learning seems relatively safe (hard to see how that would lead to models that have dangerous long-term internal goals), while we should avoid long-horizon outcome-based RL (which seems much more likely to lead to the model learning undesirable long-term goals) as long as possible. We should also avoid training against our interpretability methods and our monitoring setup (such that our models aren’t simply trained to work around these). There might be additional desirable limitations, for example, maintaining legible and faithful chains of thought as long as possible. We should define these constraints ahead of time, maintain them as long as we can throughout the intelligence explosion, and only drop them if absolutely necessary.
針對性訓練方法的限制。有些訓練模型的方法可能本質上更具風險——更有可能產生嚴重的錯位——比其他方法。例如,模仿學習看起來相對安全(很難看出這會如何導致具有危險長期內部目標的模型),而我們應該盡可能避免長期結果導向的強化學習(這似乎更有可能導致模型學習到不良的長期目標)。我們還應該避免針對我們的可解釋性方法和監控設置進行訓練(這樣我們的模型不會僅僅被訓練來繞過這些)。可能還有其他可取的限制,例如,儘可能保持清晰和忠實的思維鏈。我們應該提前定義這些約束,在整個智能爆炸過程中儘可能保持它們,並且只有在絕對必要時才放棄它們。 - There’s likely a lot more possible here.
這裡可能還有更多的可能性。
Will these be foolproof? Not at all. True superintelligence is likely able to get around most-any security scheme for example. Still, they buy us a lot more margin for error—and we’re going to need any margin we can get. We’ll want to use that margin to get in a position where we have very high confidence in our alignment techniques, only relaxing “superdefense” measures (for example, deploying the superintelligence in non-airgapped environments) concomitant with our confidence.
這些會是萬無一失的嗎?完全不會。例如,真正的超級智能可能能夠繞過幾乎所有的安全方案。不過,它們確實為我們提供了更多的容錯空間——而我們將需要任何能得到的容錯空間。我們會希望利用這些空間來確保我們的對齊技術非常可靠,只有在我們對這些技術充滿信心的情況下,才會放鬆“超級防禦”措施(例如,在非隔離環境中部署超級智能)。
Things will get dicey again once we move to deploying these AI systems in less-controlled settings, for example in military applications. It’s likely circumstances will force us to do this fairly quickly, but we should always try to buy as much margin for error as much as possible—for example, rather than just directly deploying the superintelligences “in the field” for military purposes, using them to do R&D in a more isolated environment, and only deploying the specific technologies they invent (e.g., more limited autonomous weapons systems that we’re more confident we can trust).
一旦我們開始在較不受控的環境中部署這些人工智慧系統,例如在軍事應用中,情況將再次變得棘手。情況很可能會迫使我們相當迅速地這樣做,但我們應該始終盡量爭取盡可能多的誤差餘地——例如,不僅僅是直接將超級智能“部署在現場”用於軍事目的,而是在更隔離的環境中使用它們進行研發,並且只部署它們發明的特定技術(例如,我們更有信心可以信任的更有限的自主武器系統)。
Why I’m optimistic, and why I’m scared
為什麼我樂觀,為什麼我害怕
I’m incredibly bullish on the technical tractability of the superalignment problem. It feels like there’s tons of low-hanging fruit everywhere in the field. More broadly, the empirical realities of deep learning have shaken out more in our favor compared to what some speculated 10 years ago. For example, deep learning generalizes surprisingly benignly in many situations: it often just “does the thing we meant” rather than picking up some abstruse malign behavior.
我對超對齊問題的技術可解性非常樂觀。感覺這個領域到處都是唾手可得的成果。更廣泛地說,深度學習的經驗現實比十年前一些人的猜測更有利於我們。例如,深度學習在許多情況下的泛化出奇地良性:它通常只是“做我們想做的事”,而不是採取一些晦澀的惡意行為。此外,雖然完全理解模型內部結構會很困難,但至少對於初期的人工通用智能(AGI),我們有相當大的解釋性機會——我們可以通過思維鏈讓它們透明地推理,並且像表示工程這樣的臨時技術作為“測謊器”或類似工具效果出奇地好。
I think there’s a pretty reasonable shot that “the default plan” to align “somewhat-superhuman” systems will mostly work.
我認為「預設計劃」來對齊「某種超人系統」大致上是可行的。當然,抽象地談論「預設計劃」是一回事,但如果執行該計劃的團隊是你和你的 20 位同事,那就完全是另一回事了(壓力大得多!)。目前真正致力於解決這個問題的人數仍然極少,可能只有幾十位認真的研究人員。沒有人在掌控全局!在這方面有這麼多有趣且富有成效的機器學習研究可以做,而這個挑戰的嚴重性要求我們比目前投入的努力要多得多。
But that’s just the first part of the plan—what really keeps me up at night is the intelligence explosion. Aligning the first AGIs, the first somewhat-superhuman systems, is one thing. Vastly superhuman, alien superintelligence is a new ballgame, and it is a scary ballgame.
但這只是計劃的第一部分——真正讓我夜不能寐的是智能爆炸。讓第一批 AGI,第一批有點超人系統對齊是一回事。極其超人、外星超級智能是另一個全新的局面,而且這是一個可怕的局面。
The intelligence explosion will be more like running a war than launching a product. We’re not on track for superdefense, for an airgapped cluster or any of that; I’m not sure we would even realize if a model self-exfiltrated. We’re not on track for a sane chain of command to make any of these insanely high-stakes decisions, to insist on the very-high-confidence appropriate for superintelligence, to make the hard decisions to take extra time before launching the next training run to get safety right or dedicate a large majority of compute to alignment research, to recognize danger ahead and avert it rather than crashing right into it. Right now, no lab has demonstrated much of a willingness to make any costly tradeoffs to get safety right (we get lots of safety committees, yes, but those are pretty meaningless). By default, we’ll probably stumble into the intelligence explosion and have gone through a few OOMs before people even realize what we’ve gotten into.
情報爆炸將更像是一場戰爭,而不是推出一款產品。我們並沒有朝著超級防禦、隔離集群或任何類似的方向前進;我不確定我們是否會意識到一個模型自我外洩。我們也沒有一個理智的指揮鏈來做出這些極高風險的決策,堅持對超級智能的高度信心,做出艱難的決定,在啟動下一次訓練之前花更多時間來確保安全,或將大部分計算資源投入到對齊研究中,認識到前方的危險並避免它,而不是直接撞上去。目前,沒有任何實驗室表現出願意做出任何昂貴的權衡來確保安全(我們有很多安全委員會,但那些幾乎沒有意義)。在默認情況下,我們可能會跌跌撞撞地進入信息爆炸,並在意識到我們陷入了什麼之前經歷了幾次數量級的變化。
We’re counting way too much on luck here.
我們在這裡過於依賴運氣了。
Next post in series: 下一篇文章:
IIId. The Free World Must Prevail
自由世界必須勝利
As not-very-politely certified by the doomer-in-chief! At the very least, I would call myself a strong optimist that this problem is solvable. I have spent considerable energies debating the AI pessimists and strongly advocated against policies like an AI pause.

正如末日主義者所不太禮貌地認證的那樣!至少,我會稱自己為一個堅定的樂觀主義者,認為這個問題是可以解決的。我花了大量精力與人工智慧悲觀主義者辯論,並強烈反對像人工智慧暫停這樣的政策。I’m most worried about things just being totally crazy around superintelligence, including things like novel WMDs, destructive wars, and unknown unknowns. Moreover, I think the arc of history counsels us to not underrate authoritarianism—and superintelligence might allow authoritarians to dominate for billions of years.
As Tyler Cowen says, muddling through is underrated!
Ironically, the safety guys made the biggest breakthrough for enabling AI’s commercial success by inventing RLHF! Base models had lots of raw smarts but were unsteerable and thus unusable for most applications.
This highlights an important distinction: the technical ability to align (steer/control) a model is separate from a values question of what to align to. There have been many political controversies about the latter question. And while I agree with the opposition to some of the outgrowths here, that shouldn’t distract from the basic technical problem. Yes, alignment techniques can be misused—but we will need better alignment techniques to ensure even basic side constraints for future models, like follow instructions or follow the law. See also “AI alignment is distinct from its near-term applications”.
“We estimate an average hourly payment of approximately $95 per hour,” p.3 of the GPQA paper.
Very simplified, think of an AI system trying, via trial and error, to maximize money over a period of a year, and the final, trained AI model being the result of a selection process that selects for the AI systems that were most successful at maximizing money.
What RL is doing is simply exploring strategies for succeeding at the objective. If a strategy works, it is reinforced in the model. So if lying, fraud, power-seeking, etc. (or patterns of thinking that could lead to these sorts of behaviors in at least some situations) work, these will also be reinforced in the model.
(or inference-time monitoring models trained with human supervision)
Moreover, even recent progress in mechanistic interpretability to “disentangle the features” of models with sparse autoencoders doesn’t on its own solve the problem of how to deal with superhuman models. For one, the model might simply “think” in superhuman concepts you don’t understand. Moreover, how do you know which feature is the one you want? You still don’t have ground truth labels. For example, there might be tons of different features that look like the “truth feature” to you, one of which is “what the model actually knows” and the others being “what would xyz human think” or “what do the human raters want me to think” etc.
Sparse autoencoders won’t be enough on their own, but they will be a tool—an incredibly helpful tool!—that ultimately has to cash out in helping with things like the science of generalization.
Essentially, needing only the consistency properties of truth, rather than strong/ground truth labels of true/false, which we won’t have for superhuman systems.
I’m still worried about the scalability of a lot of these techniques to very superhuman models—I think explicitly or implicitly they mostly rely on ground-truth labels, i.e. a supervisor smarter than the model, and/or favorable generalization.
A model stealing its own weights, to make copies of itself outside of the original datacenter.
Protecting against humans fooled or persuaded by the AI to help it exfiltrate
Though, of course, while that may apply to current models and perhaps human-level systems, we have to be careful about attempting to extrapolate evidence from current models to future vastly superhuman models.
To be clear, given the stakes, I think “muddling through” is in some sense a terrible plan. But it might be all we’ve got.
I’m reminded of Scott Aaronson’s letter to his younger self:
“There’s a company building an AI that fills giant rooms, eats a town’s worth of electricity, and has recently gained an astounding ability to converse like people. It can write essays or poetry on any topic. It can ace college-level exams. It’s daily gaining new capabilities that the engineers who tend to the AI can’t even talk about in public yet. Those engineers do, however, sit in the company cafeteria and debate the meaning of what they’re creating. What will it learn to do next week? Which jobs might it render obsolete? Should they slow down or stop, so as not to tickle the tail of the dragon? But wouldn’t that mean someone else, probably someone with less scruples, would wake the dragon first? Is there an ethical obligation to tell the world more about this? Is there an obligation to tell it less?
I am—you are—spending a year working at that company. My job—your job—is to develop a mathematical theory of how to prevent the AI and its successors from wreaking havoc. Where “wreaking havoc” could mean anything from turbocharging propaganda and academic cheating, to dispensing bioterrorism advice, to, yes, destroying the world.”