Some Speculations on Modern GPU Architecture Memory Consistency Models (Part 2) - Synchronization Performance
Preface
In the previous article, we made some conjectures about the memory consistency model of modern NVIDIA GPU hardware based on the conversion from PTX to SASS. In this article, we will focus on the application level, experimentally compare the performance of different code implementations for synchronization operations, and draw some empirical conclusions for reference.
Note: This article focuses on the introduction of experimental content and analysis of results, rather than explanations of basic concepts. If readers are unfamiliar with fundamental concepts such as memory consistency models/memory barriers, it is recommended to first study the relevant basics before reading this article.
Note: The author's professional background is in machine learning training/inference framework development & performance optimization, with limited understanding of underlying hardware. There may inevitably be omissions in the article, so experts are welcome to provide corrections and critiques in the comments section.
Experimental Design
In the previous article, we introduced a simple synchronization model (referred to as Message Passing in PTX) and implemented this synchronization model on GPUs based on PTX. To more clearly observe synchronization performance, we have extended the experiments from the previous article.
The example code for the synchronization model in the previous article only included one producer and one consumer, and the runtime of the CUDA Kernel was too short to be useful for performance comparison. Therefore, to clearly observe synchronization performance, we designed the following experiment: launch a large grid containing numerous warps, assigning each warp a warp_id starting from 0. For each warp, its execution logic is to poll a flag—when the flag's value equals this warp_id, polling ends, and the warp sets the flag's value to warp_id + 1 to notify the next warp, as shown below:
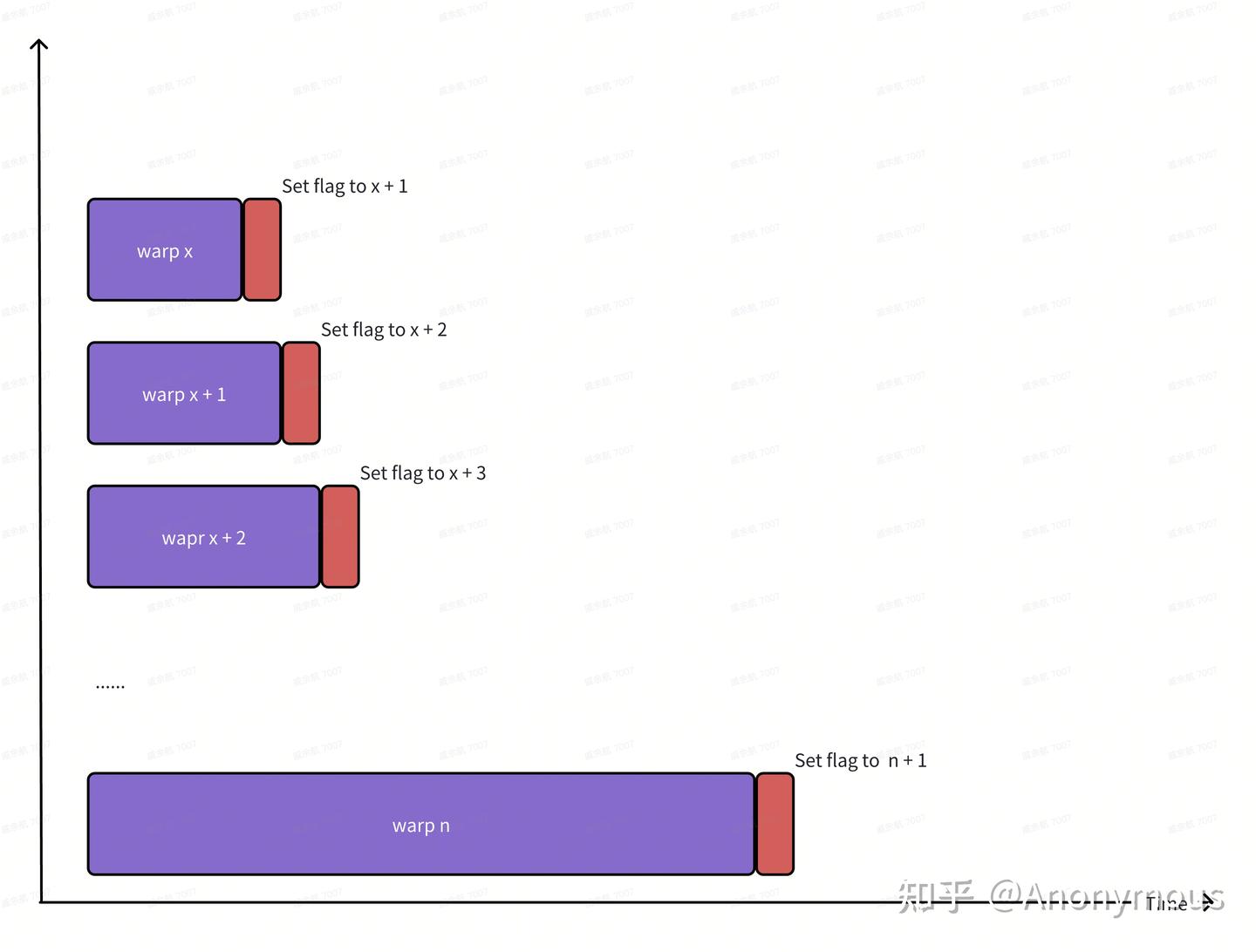
When a CUDA Kernel completes execution, its runtime is approximately equal to the sum of synchronization times across all warps.
Code Implementation
There are numerous specific code implementations for achieving synchronization. This section introduces several possible synchronization implementations.
Synchronization based on PTX at the GPU Scope level
Referring to the code in the previous article, we can implement ld/st with memory barrier semantics based on inline PTX. When specifying memory barrier semantics for ld/st, we need to define the scope to indicate the visibility range of memory operations. Since we launch a large number of warps, and these warps are not all within the same ThreadBlock, these warps may be scheduled to different SM Cores. Therefore, the scope must be specified as at least gpu to ensure the proper functioning of synchronization operations, as shown in the following code:
__device__ __forceinline__ unsigned int ld_gpu(const unsigned int *ptr) {
unsigned int ret;
asm volatile ("ld.acquire.gpu.global.u32 %0, [%1];" : "=r"(ret) : "l"(ptr));
return ret;
}
__device__ __forceinline__ void st_gpu(unsigned int *ptr, unsigned int value) {
asm ("st.release.gpu.global.u32 [%0], %1;" :: "l"(ptr), "r"(value) : "memory");
}
void __global__ hot_potato_sync_gpu_kernel(unsigned int* signal, unsigned int* loops) {
constexpr unsigned int warp_size = 32;
namespace cg = cooperative_groups;
auto tid = cg::this_grid().thread_rank();
auto warp_id = tid / warp_size;
auto lane_id = tid % warp_size;
if (lane_id == 0) {
unsigned int loop_count = 0;
while (ld_gpu(signal) != warp_id) {
loop_count++;
}
st_gpu(signal, warp_id + 1);
loops[warp_id] = loop_count;
}
__syncwarp();
}
Synchronization on SYS Scope based on PTX
The visibility range of memory operations specified by sys scope is larger than that of gpu scope, so we can also use sys scope as the scope for memory operations.
__device__ __forceinline__ unsigned int ld_sys(const unsigned int *ptr) {
unsigned int ret;
asm volatile ("ld.acquire.sys.global.u32 %0, [%1];" : "=r"(ret) : "l"(ptr));
return ret;
}
__device__ __forceinline__ void st_sys(unsigned int *ptr, unsigned int value) {
asm ("st.release.sys.global.u32 [%0], %1;" :: "l"(ptr), "r"(value) : "memory");
}
void __global__ hot_potato_sync_sys_kernel(unsigned int* signal, unsigned int* loops) {
constexpr unsigned int warp_size = 32;
namespace cg = cooperative_groups;
auto tid = cg::this_grid().thread_rank();
auto warp_id = tid / warp_size;
auto lane_id = tid % warp_size;
if (lane_id == 0) {
unsigned int loop_count = 0;
while (ld_sys(signal) != warp_id) {
loop_count++;
}
st_sys(signal, warp_id + 1);
loops[warp_id] = loop_count;
}
__syncwarp();
}
Synchronization based on PTX at CTA Scope
Observant readers may notice that our designed experimental program has some room for optimization. Each warp always notifies the warp with ID warp_id + 1. In fact, if a ThreadBlock contains a large number of warps, most synchronization occurs within a single ThreadBlock. For such cases, we can use CTA Scope to achieve synchronization. However, for warps at ThreadBlock boundaries, we still need to use GPU scope at minimum to synchronize with warps in other ThreadBlocks. The optimized code is shown below:
__device__ __forceinline__ unsigned int ld_cta(const unsigned int *ptr) {
unsigned int ret;
asm volatile ("ld.acquire.cta.global.u32 %0, [%1];" : "=r"(ret) : "l"(ptr));
return ret;
}
__device__ __forceinline__ void st_cta(unsigned int *ptr, unsigned int value) {
asm ("st.release.cta.global.u32 [%0], %1;" :: "l"(ptr), "r"(value) : "memory");
}
void __global__ hot_potato_sync_cta_kernel(unsigned int* signal, unsigned int* loops) {
constexpr unsigned int warp_size = 32;
constexpr unsigned int threadblock_warp_count = 32;
namespace cg = cooperative_groups;
auto tid = cg::this_grid().thread_rank();
auto warp_id = tid / warp_size;
auto lane_id = tid % warp_size;
auto local_warp_id = warp_id % threadblock_warp_count;
if (lane_id == 0) {
unsigned int loop_count = 0;
if (local_warp_id == 0) {
while (ld_gpu(signal) != warp_id) {
loop_count++;
}
} else {
while (ld_cta(signal) != warp_id) {
loop_count++;
}
}
if (local_warp_id != (threadblock_warp_count - 1)) {
st_cta(signal, warp_id + 1);
} else {
st_gpu(signal, warp_id + 1);
}
loops[warp_id] = loop_count;
}
__syncwarp();
}
Performance Data Analysis
We compiled this program on the H20 GPU (sm_90) using CUDA Toolkit 12.8. In our program, the grid contains 1,048,576 (1M) warps, with each ThreadBlock consisting of 32 warps (1024 CUDA Threads). Running the program yielded the following experimental results:
CTA Scope Sync Time: 300.676 ms
GPU Scope Sync Time: 1747.47 ms
SYS Scope Sync Time: 4613.27 ms
Clearly, the smaller the scope, the better the synchronization performance, which aligns with expectations. This is because a smaller scope allows us to utilize storage media closer to the SM Core for synchronization. For example, at the CTA Scope, we can leverage the L1 Cache, whereas at the GPU Scope, only the L2 Cache is available, which inherently has higher access latency.
Next, let's take a closer look at the SASS code (focusing only on key portions of the SASS code here).
CTA Scope:
LDG.E.STRONG.SM R0, desc[UR4][R2.64]
NOP
......
@P0 MEMBAR.ALL.CTA
@P0 STG.E.STRONG.SM desc[UR6][R2.64], R9GPU Scope:
LDG.E.STRONG.GPU R4, desc[UR4][R2.64]
CCTL.IVALL
......
MEMBAR.ALL.GPU
ERRBAR
CGAERRBAR
STG.E.STRONG.GPU desc[UR6][R2.64], R7SYS Scope:
LDG.E.STRONG.SYS R4, desc[UR4][R2.64]
CCTL.IVALL
......
MEMBAR.ALL.SYS
ERRBAR
CGAERRBAR
STG.E.STRONG.SYS desc[UR6][R2.64], R7
From the SASS code, we can observe that different Scopes primarily result in two key differences:
- The Scope of LDG/STG instructions differs.
- The Scope of MEMBAR memory barrier instructions differs.
So how much impact do these two differences actually have on performance? We can conduct a set of comparative experiments.
From the content of the previous article, we can understand that the primary purpose of adding memory barriers is to ensure that the producer and consumer complete their operations on data and flags in the order expected by each other. However, in the earlier experiment, there was no actual data interaction required between the producer and consumer—only a flag was being passed (the st/ld flag operations of the producer and consumer are Morally Strong with each other and satisfy the Observation Order).
Therefore, we can remove the memory barriers from the previous experiment and conduct a new set of tests to eliminate the influence of memory barriers. So, how do we remove the memory barriers? Simply change the acquire/release of the ld/st instructions to relaxed. We compile the performance data of the control experiment and the original experiment into the following table:
| CTA | GPU | SYS | |
|---|---|---|---|
| With Memory Fence | 300.676 ms | 1747.47 ms | 4613.27 ms |
| Without Memory Fence | 264.32 ms | 1089.03 ms | 2413.3 ms |
Comparing these columns reveals that as the Scope increases, the overhead of memory barriers also grows larger, accounting for an increasingly higher proportion.
Non-PTX implementation
For those unfamiliar with PTX, they might choose to implement synchronization using the following code:
void __global__ hot_potato_sync_volatile_kernel(volatile unsigned int* signal, unsigned int* loops) {
constexpr unsigned int warp_size = 32;
namespace cg = cooperative_groups;
auto tid = cg::this_grid().thread_rank();
auto warp_id = tid / warp_size;
auto lane_id = tid % warp_size;
if (lane_id == 0) {
unsigned int loop_count = 0;
while (*signal != warp_id) {
loop_count++;
}
__threadfence();
*signal = warp_id + 1;
loops[warp_id] = loop_count;
}
__syncwarp();
}
This approach sets the flag as volatile and manually inserts a memory barrier.
We have also verified the performance of this approach and found that it falls between the GPU Scope experiment and the SYS Scope experiment in terms of performance:
Volatile + Fence Sync Time: 3984.21 msLet's further examine its SASS code:
LDG.E.STRONG.SYS R4, desc[UR4][R2.64]
......
MEMBAR.SC.GPU
ERRBAR
CGAERRBAR
CCTL.IVALL
STG.E.STRONG.SYS desc[UR6][R2.64], R7
We can observe that LDG/STG uses SYS Scope, which aligns with the SYS Scope experiment. The __threadfence() function is compiled into multiple instructions, where the memory barrier instruction MEMBAR.SC.GPU has its Scope specified as GPU, consistent with the GPU Scope experiment. However, MEMBAR.SC differs from MEMBAR.ALL in the GPU Scope experiment. Since NVIDIA hasn't officially released detailed documentation about ALL and SC, we won't speculate too much and only need to have a basic understanding of their performance.
If we replace __threadfence() with __threadfence_system() in the above code, we can obtain performance similar to the SYS Scope experiment:
Volatile + Fence(System) Sync Time: 4653.06 msExamining its SASS instructions:
LDG.E.STRONG.SYS R4, desc[UR4][R2.64]
......
MEMBAR.SC.SYS
ERRBAR
CGAERRBAR
CCTL.IVALL
STG.E.STRONG.SYS desc[UR6][R2.64], R7
Compared to using __threadfence(), only MEMBAR.SC.GPU changes to MEMBAR.SC.SYS, but its performance significantly degrades, showing that the Scope of memory barrier instructions has a huge impact on performance. Additionally, the performance of this set of experiments is slightly worse (by about 50ms) compared to the SYS Scope experiments, likely because SC imposes stronger memory ordering constraints, thus incurring greater overhead.
NVIDIA's Officially Recommended Implementation
There is another synchronization method officially recommended by NVIDIA, which uses atomic_ref. The synchronization code implemented based on atomic_ref is as follows:
void __global__ hot_potato_sync_atomic_ref_kernel(unsigned int* signal, unsigned int* loops) {
constexpr unsigned int warp_size = 32;
cuda::atomic_ref<unsigned int, cuda::thread_scope_device> ref_signal(*signal);
namespace cg = cooperative_groups;
auto tid = cg::this_grid().thread_rank();
auto warp_id = tid / warp_size;
auto lane_id = tid % warp_size;
if (lane_id == 0) {
unsigned int loop_count = 0;
while (ref_signal.load(cuda::memory_order_acquire) != warp_id) {
loop_count++;
}
ref_signal.store(warp_id + 1, cuda::memory_order_release);
loops[warp_id] = loop_count;
}
__syncwarp();
}
Testing its performance reveals that it is almost identical to the performance observed in the GPU Scope experiment:
atomic_ref Sync Time:1747.63
Examining its SASS code also reveals that this set of experiments is identical to the GPU Scope experiments in terms of the scope of memory access instructions and memory barrier instructions—both are GPU Scope:
LD.E.STRONG.GPU R4, desc[UR4][R2.64]
CCTL.IVALL
......
MEMBAR.ALL.GPU
ERRBAR
CGAERRBAR
ST.E.STRONG.GPU desc[UR6][R2.64], R7
Therefore, it is expected that the performance of this set of experiments is similar to that of the GPU Scope experiments. Compared to the PTX-based implementation, this approach clearly offers better readability, greater flexibility, and stronger compatibility, which is why we highly recommend using this method for synchronization.
Summary
This article experimentally compares the performance of several synchronization implementations. For developers, selecting the appropriate scope for memory access and memory barrier instructions based on specific application scenarios can effectively improve performance. We hope the content of this article will be helpful to the broader CUDA developer community, and we once again welcome experts to actively share their comments on the topics discussed.
Appendix
Code link: GitHub - HydraQYH/CUDASynchronizePrimitives: Benchmark sync primitives.


Expert, may I ask if the LDG/STG instructions here can correspond to cache coherency, and memory barriers correspond to memory consistency?
03-27 · Shanghai
I don't quite understand your point. LDG/STG are just SASS instructions, while cache coherency and memory consistency are conceptual topics - there's no direct connection between them.
03-27 · Zhejiang