

GB200 Hardware Architecture - Component Supply Chain & BOM
GB200 硬件架构 - 组件供应链与物料清单
Hyperscale customization, NVLink Backplane, NVL36, NVL72, NVL576, PCIe Retimers, Switches, Optics, DSP, PCB, InfiniBand/Ethernet, Substrate, CCL, CDU, Sidecar, PDU, VRM, Busbar, Railkit, BMC
超大规模定制,NVLink 背板,NVL36,NVL72,NVL576,PCIe 重定时器,交换机,光学,数字信号处理器,印刷电路板,InfiniBand/以太网,基板,CCL,CDU,侧车,PDU,VRM,母线,轨道套件,BMC




Nvidia’s GB200 brings significant advances in performance via superior hardware architecture, but the deployment complexities rise dramatically. While on the face of it, Nvidia has released a standard rack that people will just install in their datacenters without much trouble, plug-and-play style, the reality is there are dozens of different deployment variants with tradeoffs and a significant complexity increase generation on generation. The supply chain gets reworked for end datacenter deployers, clouds, server OEMs / ODMs, and downstream component supply chains.
Nvidia 的 GB200 通过卓越的硬件架构带来了显著的性能提升,但部署的复杂性大幅增加。表面上看,Nvidia 发布了一个标准机架,人们可以轻松地在数据中心安装,像即插即用一样,但实际上有数十种不同的部署变体,伴随着权衡和代际间显著的复杂性增加。供应链为最终数据中心部署者、云服务、服务器 OEM/ODM 以及下游组件供应链进行了重组。
Today we are going to go from A to Z on the different form factors of GB200 and how they changed versus the prior 8 GPU HGX baseboard servers. We will break downs on unit volumes, supplier market share and cost for over 50 different subcomponents of the GB200 rack. Furthermore, we will dive into the hyperscale customization that changes the subcomponent supply chain heavily. Lastly we will also do a deep dive into the various types of liquid cooling architectures, deployment complexities, and the supply chain there.
今天我们将全面探讨 GB200 的不同形态因素,以及它们与之前的 8 GPU HGX 基板服务器的变化。我们将分析 GB200 机架上 50 多个不同子组件的单位数量、供应商市场份额和成本。此外,我们还将深入研究超大规模定制如何大幅改变子组件供应链。最后,我们还将深入探讨各种液冷架构、部署复杂性及其供应链。
Table of Contents: 目录:
GB200 form factors GB200 表单因素
Power budget 电力预算
Compute tray architecture
计算托盘架构Networking fabrics 网络结构
NVLink fabric NVLink 结构
NVL72
NVL36x2
NVL576
Backend fabric (Infiniband/Ethernet)
后端网络(Infiniband/以太网)Frontend fabric 前端织物
Networking dollar content summary
网络美元内容摘要Optics 光学
DSP
Hyperscaler customization
超大规模定制Substrate, PCB, and CCL 基板、PCB 和 CCL
Liquid cooling 液体冷却
Rack architecture changes & content
机架架构变更与内容Heat transfer flow 热传递流动
L2A (Liquid to Air) vs L2L (Liquid to Liquid)
L2A(液体到空气)与 L2L(液体到液体)Redesigning data center infrastructure
重新设计数据中心基础设施Supply chain procurement decision maker & analysis
供应链采购决策者与分析Liquid cooling components competition
液冷组件竞争
Power delivery network, PDB, Busbar, VRM
电力传输网络,PDB,母线,VRMBMC
Mechanical components 机械组件
OEM / ODM Mapping OEM / ODM 映射
The 4 Rack Scale Form Factors of Blackwell
布莱克威尔的四种机架规模形式因素
With GB200 Racks, there are 4 different major form factors offered, with customization within each.
使用 GB200 机架,提供 4 种不同的主要外形因素,并在每种外形中提供定制选项。
GB200 NVL72
GB200 NVL36x2
GB200 NVL36x2 (Ariel) GB200 NVL36x2 (阿里尔)
x86 B200 NVL72/NVL36x2
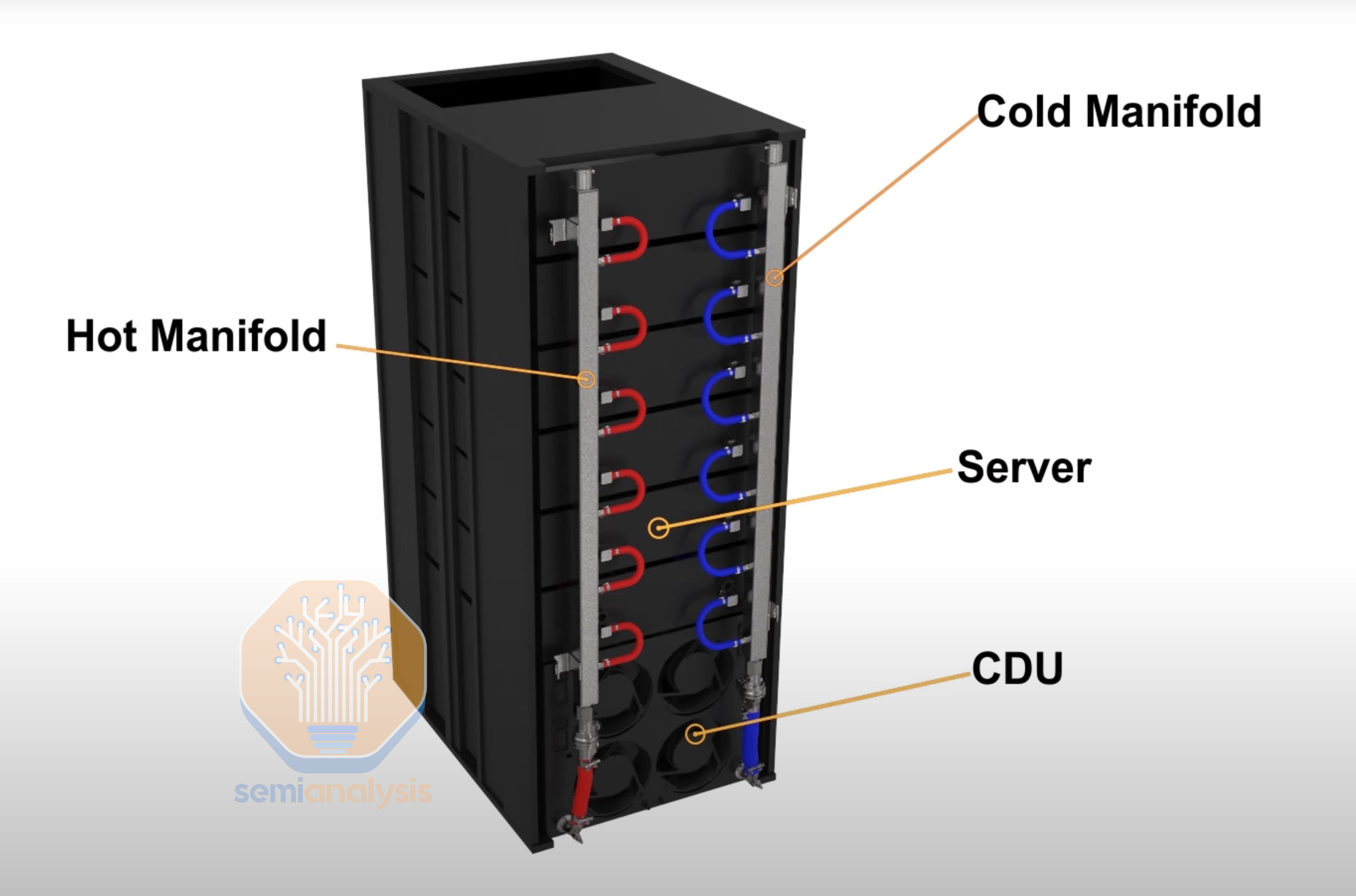
The first one is the GB200 NVL72 form factor. This form factor requires approximately 120kW per rack. To put this density into context, a general-purpose CPU rack supports up to 12kW/rack, while the higher-density H100 air-cooled racks typically only support about 40kW/rack. Moving well past 40kW per rack is the primary reason why liquid cooling is required for GB200.
第一个是 GB200 NVL72 机型。该机型每个机架需要大约 120kW 的功率。为了将这个密度放入上下文中,一般用途的 CPU 机架支持最高 12kW/机架,而高密度的 H100 风冷机架通常仅支持约 40kW/机架。每个机架超过 40kW 是 GB200 需要液冷的主要原因。

The GB200 NVL72 racks consists of 18 1U compute trays and 9 NVSwitch trays. Each compute tray is 1U in height and contains 2 Bianca boards. Each Bianca board is 1 Grace CPU and 2 Blackwell GPUs. The NVSwitch trays have two 28.8Tb/s NVSwitch5 ASICs.
GB200 NVL72 机架由 18 个 1U 计算托盘和 9 个 NVSwitch 托盘组成。每个计算托盘高 1U,包含 2 块 Bianca 板。每块 Bianca 板上有 1 个 Grace CPU 和 2 个 Blackwell GPU。NVSwitch 托盘上有两个 28.8Tb/s 的 NVSwitch5 ASIC。
With the exception of one hyperscaler who plans to deploy this as the primary variant, we believe that this version will be rarely deployed until Blackwell Ultra as most datacenter infrastructure cannot support this high of a rack density even with direct-to-chip liquid cooling (DLC).
除了一个计划将其作为主要变体的超大规模云服务商外,我们认为在黑威尔超高版推出之前,这个版本将很少被部署,因为大多数数据中心基础设施即使使用直接到芯片的液体冷却(DLC)也无法支持如此高的机架密度。
The next form factor is the GB200 NVL36 * 2 which is two racks side by side interconnected together. Most of the GB200 racks will use this form factor. Each rack contains 18 Grace CPUs and 36 Blackwell GPUs. Between the 2 racks, it still maintains being non-blocking all-to-all between all the 72 GPUs found in NVL72. Each compute tray is 2U in height and contains 2 Bianca boards. Each NVSwitch tray has two 28.8Tb/s NVSwitch5 ASIC chips. Each chip has 14.4Tb/s pointing backward toward the backplane and 14.4Tb/s pointing toward the front plate. Each NVswitch tray has 18 1.6T twin-port OSFP cages which connect horizontally to a pair NVL36 rack.
下一个形态因素是 GB200 NVL36 * 2,它是两个并排连接在一起的机架。大多数 GB200 机架将使用这种形态因素。每个机架包含 18 个 Grace CPU 和 36 个 Blackwell GPU。在这两个机架之间,仍然保持着非阻塞的全到全连接,涵盖 NVL72 中的所有 72 个 GPU。每个计算托盘的高度为 2U,包含 2 块 Bianca 板。每个 NVSwitch 托盘有两个 28.8Tb/s 的 NVSwitch5 ASIC 芯片。每个芯片有 14.4Tb/s 指向背板,14.4Tb/s 指向前面板。每个 NVswitch 托盘有 18 个 1.6T 双端口 OSFP 笼,水平连接到一对 NVL36 机架。

The per rack power & cooling density is 66kW per rack for a total of 132kW for NVL36 racks * 2. This is the time to market solution as each rack is only 66kW/rack. Unfortunately, a NVL36x2 system does use ~10kW more power compared to NVL72 due to the additional NVSwitch ASICs and the requirement for cross rack interconnect cabling. NVL36x2 will have 36 NVSwitch5 ASICs in total compared to only 18 NVSwitch5 ASICs on the NVL72. Even with this increase in overall power of 10kW, most firms will deploy this version next year instead of NVL72 as their datacenter can’t support 120kW per rack density. We will discuss the reason for this later in the liquid cooling section.
每个机架的电力和冷却密度为每个机架 66kW,总计为 NVL36 机架*2 的 132kW。这是市场快速解决方案,因为每个机架仅为 66kW/机架。不幸的是,NVL36x2 系统相比 NVL72 使用了大约 10kW 的额外电力,原因在于额外的 NVSwitch ASIC 和跨机架互连电缆的需求。NVL36x2 总共有 36 个 NVSwitch5 ASIC,而 NVL72 仅有 18 个 NVSwitch5 ASIC。即使整体功率增加了 10kW,大多数公司明年仍会部署这一版本,而不是 NVL72,因为他们的数据中心无法支持每个机架 120kW 的密度。我们将在液冷部分讨论原因。
The last form factor is the specific rack with a custom “Ariel” board instead of the standard Bianca. We believe this variant will primarily be used by Meta. Due to Meta’s recommendation system training and inferencing workloads, they require a higher CPU core and more memory per GPU ratio in order to store massive embedding tables and perform pre/post-processing on the CPUs.
最后的形态因素是特定的机架,配备定制的“Ariel”板,而不是标准的 Bianca。我们认为这个变体主要会被 Meta 使用。由于 Meta 的推荐系统训练和推理工作负载,他们需要更高的 CPU 核心和每个 GPU 更大的内存比率,以便存储大量的嵌入表并在 CPU 上进行前/后处理。
The content is similar to the standard GB200 NVL72: but instead the Bianca board is swapped for an Ariel board that has 1 Grace CPU and 1 Blackwell GPU. Due to the doubling of Grace CPU content per GPU, this SKU will be more expensive even compared to NVL36x2. Similar to NVL36x2, each NVSwitch tray has 18 1.6T twin-port OSFP cages which connect horizontally to a pair NVL36 rack.
内容类似于标准 GB200 NVL72:但 Bianca 板被替换为 Ariel 板,后者配备 1 个 Grace CPU 和 1 个 Blackwell GPU。由于每个 GPU 的 Grace CPU 内容翻倍,该 SKU 的价格将比 NVL36x2 更高。与 NVL36x2 类似,每个 NVSwitch 托盘有 18 个 1.6T 双端口 OSFP 机箱,横向连接到一对 NVL36 机架。
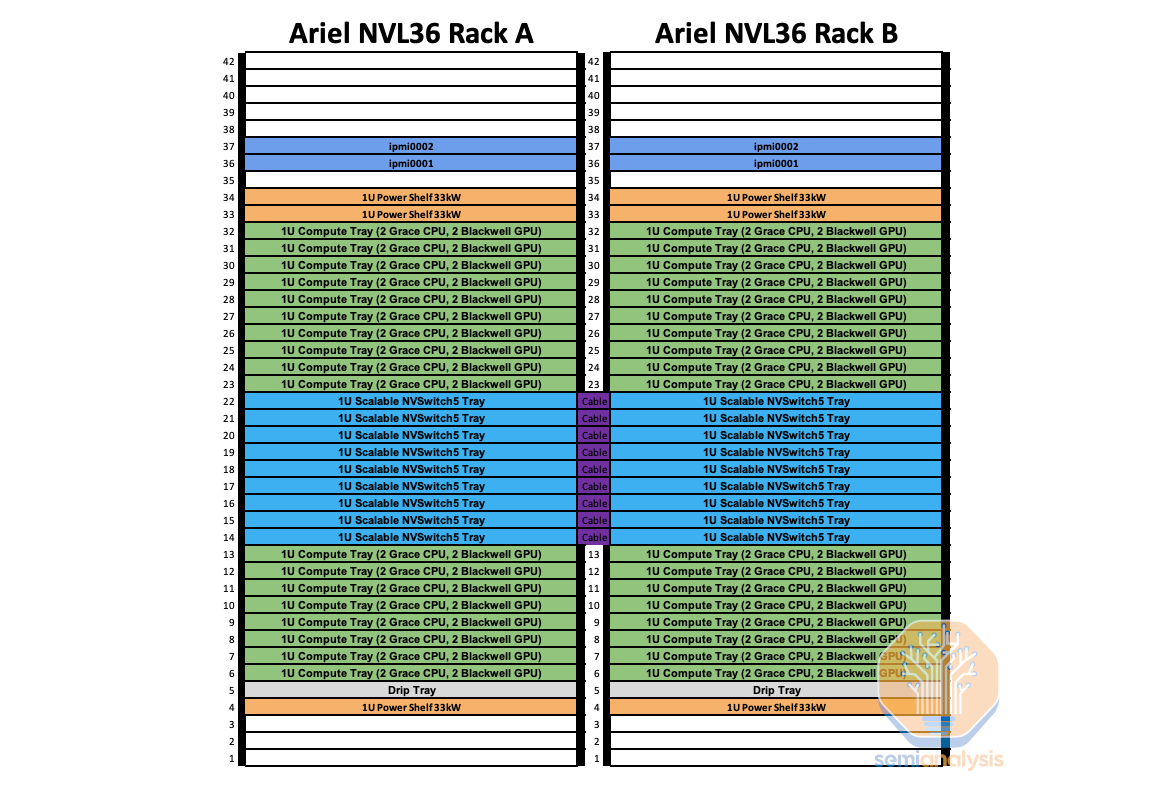
We believe that the majority of Meta’s allocation will be the normal NVL36x2 as that is more geared towards GenAI workloads while the Ariel version will just be for their largest Recommendation System workloads. While there is nothing preventing Ariel from being used for GenAI workloads, the overprovisioning of CPUs means it will be inferior from a TCO standpoint due to higher capital cost and power.
我们相信,Meta 的大部分分配将是正常的 NVL36x2,因为这更适合 GenAI 工作负载,而 Ariel 版本仅用于他们最大的推荐系统工作负载。虽然没有什么阻止 Ariel 用于 GenAI 工作负载,但 CPU 的过度配置意味着从 TCO 的角度来看,由于更高的资本成本和电力,它将处于劣势。
Lastly, in Q2 2025, there will be a B200 NVL72 and NVL36x2 form factor that will use x86 CPUs instead of Nvidia’s in-house grace CPU. This form factor is called Miranda. We believe that the CPU to GPU per compute tray will stay the same at 2 CPUs and 4 GPUs per compute tray.
最后,在 2025 年第二季度,将会有一个 B200 NVL72 和 NVL36x2 的形态,它将使用 x86 CPU,而不是 Nvidia 自家的 Grace CPU。这个形态被称为 Miranda。我们相信,每个计算托盘的 CPU 与 GPU 比例将保持不变,仍为每个计算托盘 2 个 CPU 和 4 个 GPU。
We believe that this variant of NVL72/NVL36x2 will have lower upfront capital cost compared to the Grace CPU version, with less revenue flowing to Nvidia. Since it is using an x86 CPU, there will be much lower CPU to GPU bandwidth compared to Grace C2C which can talk to the GPUs at up to 900GB/s bidirectional (450GB/s). Because of this TCO is questionable. Furthermore as the x86 CPUs will not be able to share power between the CPU and GPUs to optimize for the workload total peak power required is much higher. In our accelerator model, we have broken down which GB200 form factors & the exact volume each of the top 50 buyers will be deploying.
我们相信,这种 NVL72/NVL36x2 的变体与 Grace CPU 版本相比,前期资本成本会更低,流向 Nvidia 的收入也会减少。由于它使用的是 x86 CPU,因此与 Grace C2C 相比,CPU 与 GPU 之间的带宽会低得多,后者可以以高达 900GB/s 的双向速度(450GB/s)与 GPU 通信。因此,整体拥有成本(TCO)是值得怀疑的。此外,由于 x86 CPU 无法在 CPU 和 GPU 之间共享电力以优化工作负载,因此所需的总峰值功率要高得多。在我们的加速器模型中,我们已经详细列出了每种 GB200 形态及前 50 名买家将部署的确切数量。
Power Budget Estimates 电力预算估算
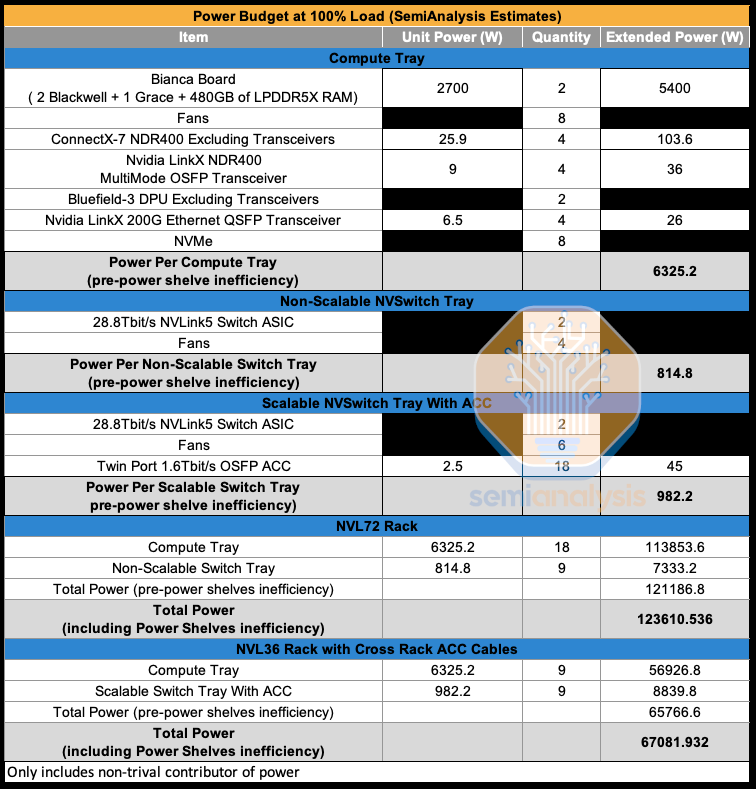
We estimate that the max TDP of each compute tray is 6.3kW. Most of the power draw from the compute tray is from the two Bianca board and 8 fans in each tray. The NVSwitch tray in NVL72 does not need to connect between racks as such has a 170W lower power draw compared to NVL36. With NVL36, there are 18 1.6T ACC cables to connect horizontally to the neighboring rack. We will explain the NVLink topology in further sections. 123.6kW per NVL72 is the total power draw including the inefficiencies from rectifying from AC power from the whip to DC power that the compute tray takes in.
我们估计每个计算托盘的最大热设计功耗(TDP)为 6.3kW。计算托盘的大部分功耗来自两个 Bianca 板和每个托盘中的 8 个风扇。NVL72 中的 NVSwitch 托盘不需要在机架之间连接,因此其功耗比 NVL36 低 170W。在 NVL36 中,有 18 根 1.6T 的 ACC 电缆用于与邻近机架进行水平连接。我们将在后面的章节中解释 NVLink 拓扑。每个 NVL72 的总功耗为 123.6kW,包括从交流电源通过电缆整流到计算托盘所需的直流电源的低效损耗。
来源:SemiAnalysis GB200 组件与供应链模型
While for NVL36*2, each rack has a max TDP of ~67kW while both rack pairs take in ~132kW. This is approximately 10kW more power draw compared to NVL72.
对于 NVL36*2,每个机架的最大热设计功耗(TDP)约为 67kW,而两个机架对的总功耗约为 132kW。这比 NVL72 的功耗多出大约 10kW。
Compute Tray Diagrams & Cabling
计算托盘图和布线
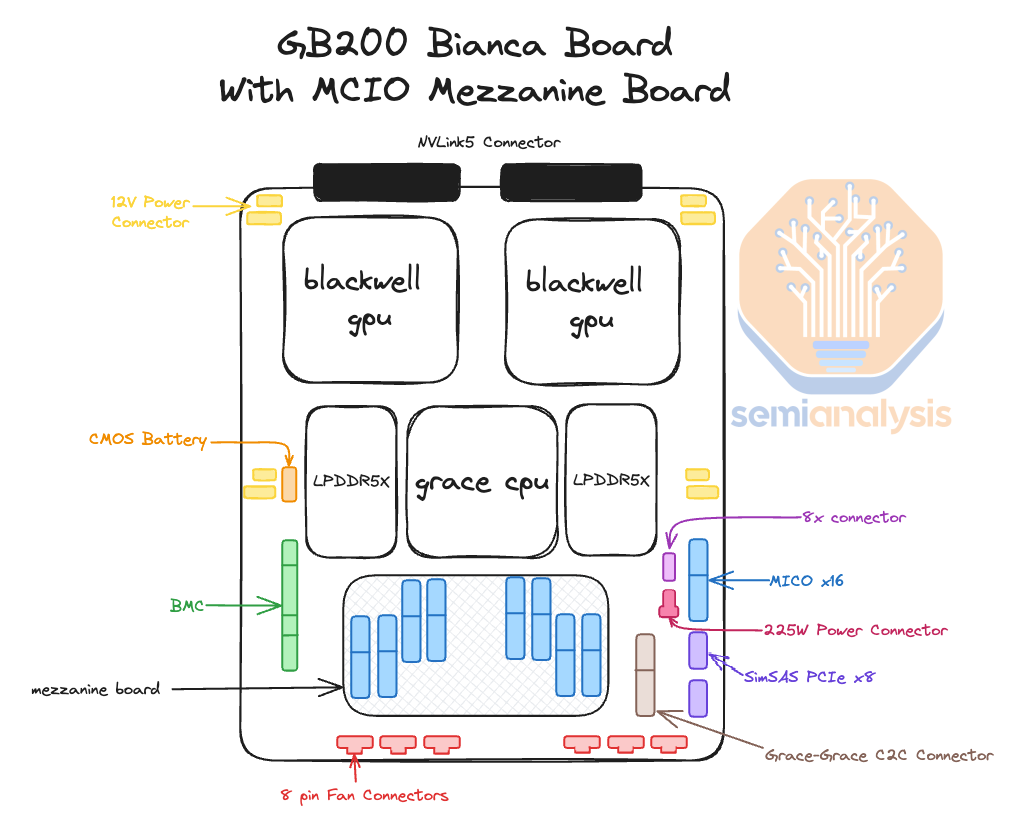
The heart of the GB200 NVL72/NVL36x2 is the Bianca board. The Bianca board contains two Blackwell B200 GPUs and a single Grace CPU. The ratio between CPU and GPU is now 1:2 on a board compared to GH200, which is a 1:1 ratio. Most of the customers that evaluated GH200 have told Nvidia that it was too expensive as 1:1 CPU ratio was too much for their workloads. This is one of the main reasons why GH200 shipped in such low volumes compared to HGX H100 (2 x86 CPUs, 8 H100 GPUs). For Blackwell, GB200 volume is way up relatively and there will be crossover in unit shipments versus HGX Blackwell B100/B200.
GB200 NVL72/NVL36x2 的核心是 Bianca 板。Bianca 板包含两个 Blackwell B200 GPU 和一个 Grace CPU。与 GH200 的 1:1 比例相比,当前板上的 CPU 与 GPU 比例为 1:2。大多数评估 GH200 的客户告诉 Nvidia,由于 1:1 的 CPU 比例对他们的工作负载来说过于昂贵,因此 GH200 的价格太高。这是 GH200 的出货量与 HGX H100(2 个 x86 CPU,8 个 H100 GPU)相比如此低的主要原因之一。对于 Blackwell 来说,GB200 的出货量相对大幅上升,并且与 HGX Blackwell B100/B200 的单位出货量将会有交叉。
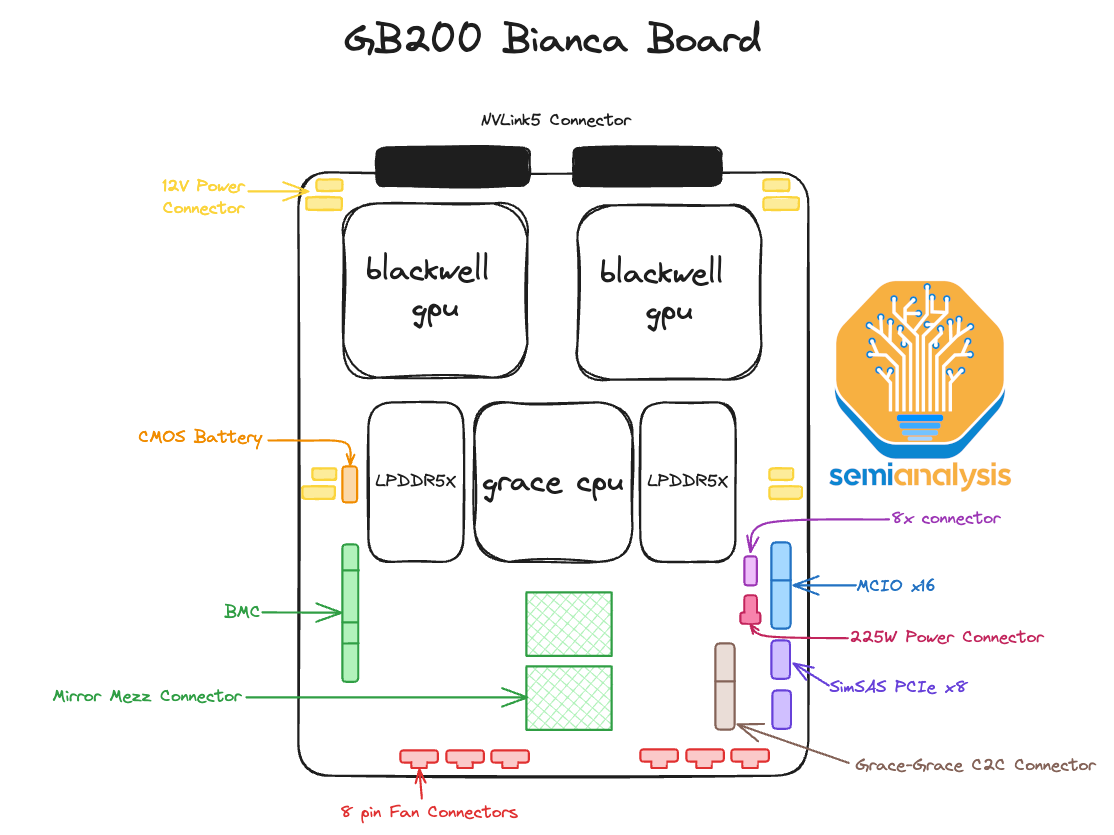
Normally in Hopper & Blackwell HGX servers, there are Broadcom PCIe switches between the CPU and the GPU. For the GB200, the CPU and GPU are both on the same PCB, reducing insertion loss to a point that there is no longer any need for switches or retimers between the CPU and GPU on the reference design. This is on the surface is extremely negative for Astera Labs. It now has ~35% short interest of free float, but that mostly from folks who aren’t following the supply chain deeply and only understand there are no retimers in the reference design. We will share more details below and in the GB200 Component & Supply Chain Model.
在 Hopper & Blackwell HGX 服务器中,CPU 和 GPU 之间通常有 Broadcom PCIe 交换机。对于 GB200,CPU 和 GPU 都在同一块 PCB 上,减少了插入损耗到不再需要在参考设计中使用交换机或重定时器。这在表面上对 Astera Labs 极为不利。它现在的自由流通股短期利息约为 35%,但这主要来自那些没有深入关注供应链的人,他们只知道参考设计中没有重定时器。我们将在下面和 GB200 组件与供应链模型中分享更多细节。
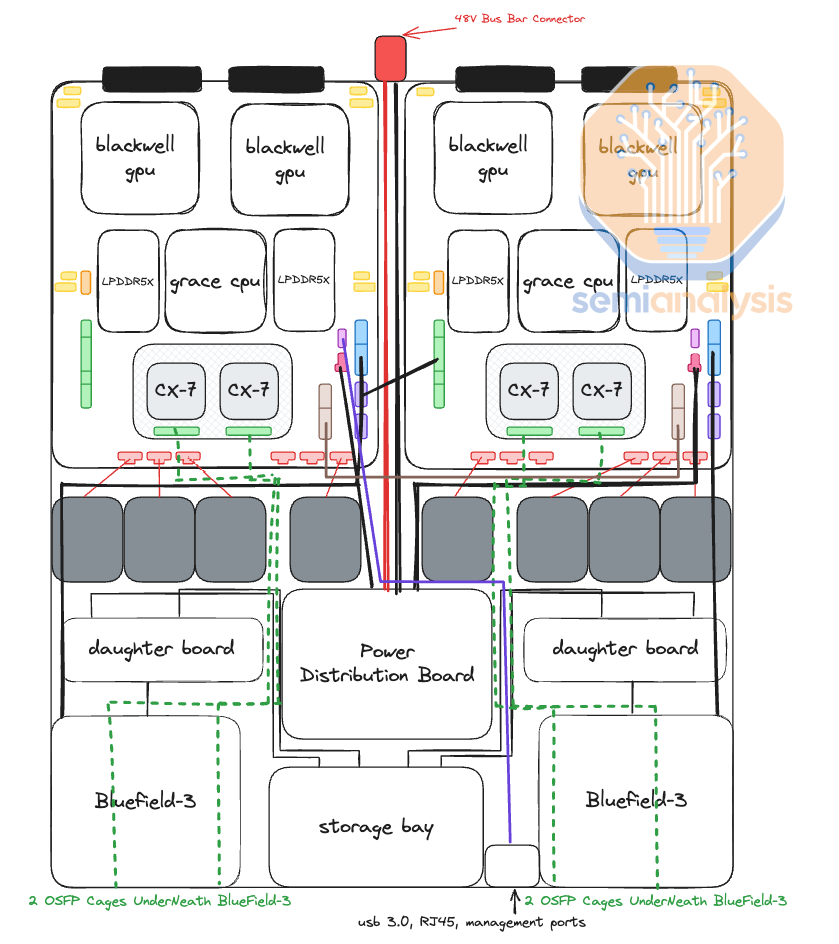
Another interesting thing about the reference design is that instead of using the typical MCIO PCIe x16 connectors to connect the main PCB board to a PCIe form factor ConnectX-7/8, the ConnectX-7/8 ICs now sit directly on top of the Bianca board using a mezzanine board via Mirror Mezz connectors.
另一个关于参考设计有趣的事情是,ConnectX-7/8 IC 现在直接位于 Bianca 板上,通过 Mirror Mezz 连接器使用中间板,而不是使用典型的 MCIO PCIe x16 连接器将主 PCB 板连接到 PCIe 形式因素的 ConnectX-7/8。
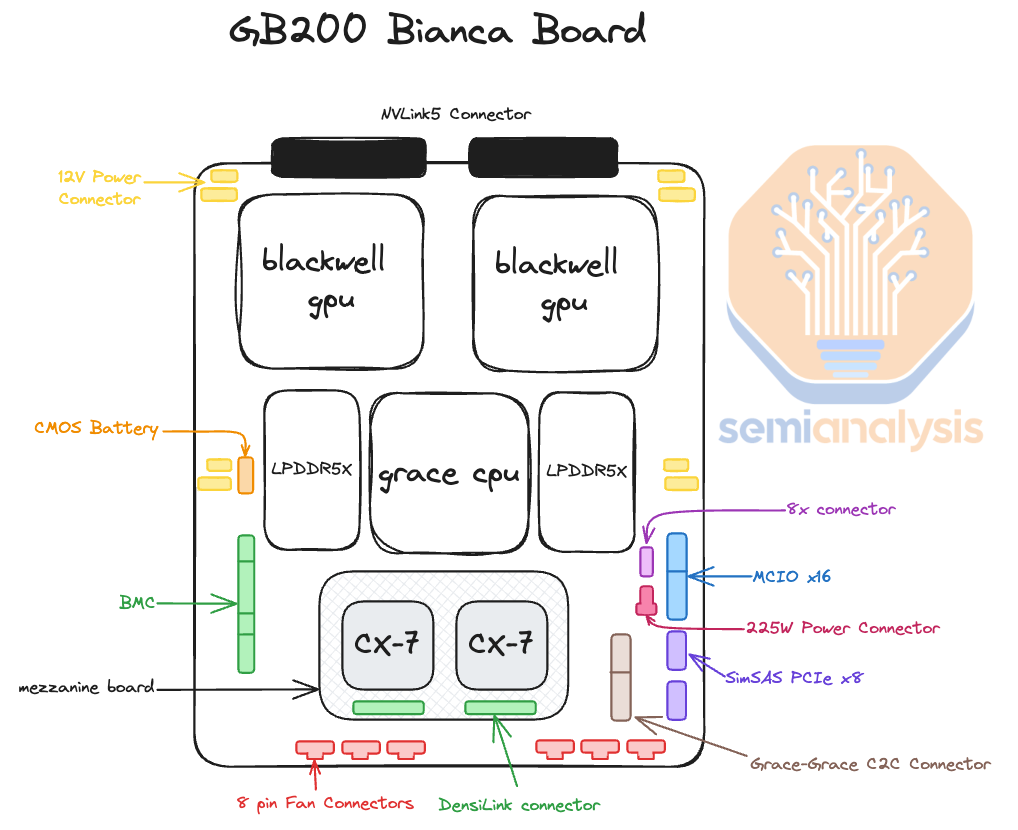
This has the advantage of using the same cold plate to cool both the CPUs, GPUs, and ConnectX-7/8 NICs. The electrical lanes are routed to the OSFP cages at the front of the chassis with DensiLink connectors from the mezzanine board. This is similar to how Nvidia used DensiLink on their gold plated DGX H100 chassis to route from the ConnectX-7 to the OSFP cages.
这具有使用相同冷板来冷却 CPU、GPU 和 ConnectX-7/8 网卡的优点。电气通道通过机箱前面的 OSFP 机箱与来自中间板的 DensiLink 连接器连接。这类似于 Nvidia 在其镀金 DGX H100 机箱中使用 DensiLink 将 ConnectX-7 连接到 OSFP 机箱的方式。
Similar to the Dual GH200, within the same compute tray, there is a high speed Coherent NVLink connection that operates up to 600GB/s bidirectional bandwidth (300GB/s unidirectional). This is an extremely fast connection and allows the CPUs to share resources and memory similar to the HGX H100/B100/B200 servers which have 2 CPUs and have NUMA (Non-Uniform Memory Access) regions.
与双重 GH200 类似,在同一计算托盘内,有一个高速相干 NVLink 连接,支持高达 600GB/s 的双向带宽(300GB/s 单向)。这是一个极快的连接,允许 CPU 共享资源和内存,类似于具有 2 个 CPU 的 HGX H100/B100/B200 服务器,这些服务器具有 NUMA(非统一内存访问)区域。
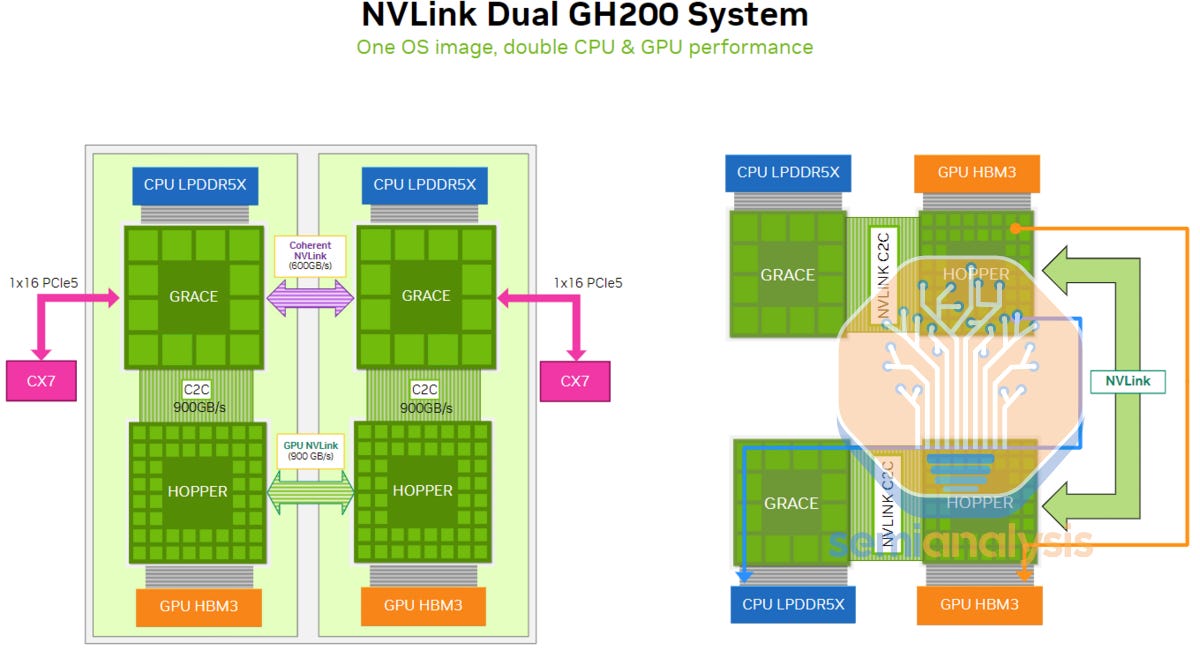
Due to this coherent link that hooks up two Bianca board, you can share memory, storage & resources such as NICs between the CPUs. For this reason, you will be able to depopulate a frontend NICs and only have 1 frontend NIC per compute tray instead of 2 as suggested in the reference design. This is similar to how in x86, even though, you have 2 CPUs per server, you only need 1 frontend NIC since the CPUs are able to share resources. We will discuss this more in the frontend networking section.
由于这个将两个 Bianca 主板连接起来的连贯链接,您可以在 CPU 之间共享内存、存储和资源,例如 NIC。因此,您将能够减少前端 NIC 的数量,每个计算托盘只需 1 个前端 NIC,而不是参考设计中建议的 2 个。这类似于在 x86 架构中,尽管每台服务器有 2 个 CPU,但由于 CPU 能够共享资源,您只需要 1 个前端 NIC。我们将在前端网络部分进一步讨论这一点。
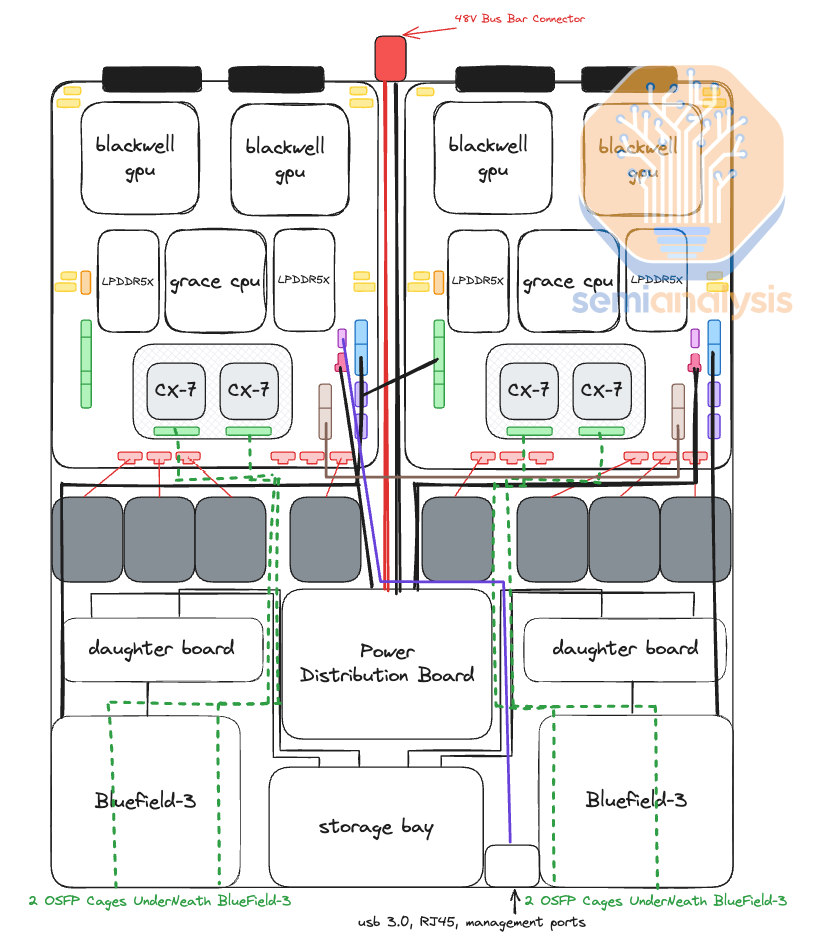
In terms of how the 2700 Watts of power gets to the board, there are 4 RapidLock 12V DC and 4 RapidLock GND (Ground) Power Connectors located around the CPU and GPU’s respective voltage regulator modules (VRM). These 12V and GND power connectors will connect to the compute tray’s power distribution board (PDB). The power distribution board takes 48V DC from the rack level busbar and steps it down to 12V DC for the Bianca board. We will discuss the changes to the power delivery network for the system in the power delivery section later.
在 2700 瓦特的电力如何传输到主板方面,CPU 和 GPU 各自的电压调节模块(VRM)周围有 4 个 RapidLock 12V 直流电源连接器和 4 个 RapidLock 接地(GND)电源连接器。这些 12V 和接地电源连接器将连接到计算托盘的电源分配板(PDB)。电源分配板从机架级母线获取 48V 直流电,并将其降压至 Bianca 主板所需的 12V 直流电。我们将在后面的电源交付部分讨论系统电源交付网络的变化。
In terms of the internal compute tray cables + connectors, most of the cost is dominated by the Mirror mezz connectors that connect the ConnectX-7/8 mezzanine board to the Bianca board & by the DensiLink cables that connect from the ConnectX-7/8 to the OSFP cages on the front of the chassis.
在内部计算托盘电缆 + 连接器方面,大部分成本由连接 ConnectX-7/8 mezzanine 板与 Bianca 板的 Mirror mezz 连接器和从 ConnectX-7/8 连接到机箱前部 OSFP 机架的 DensiLink 电缆主导。
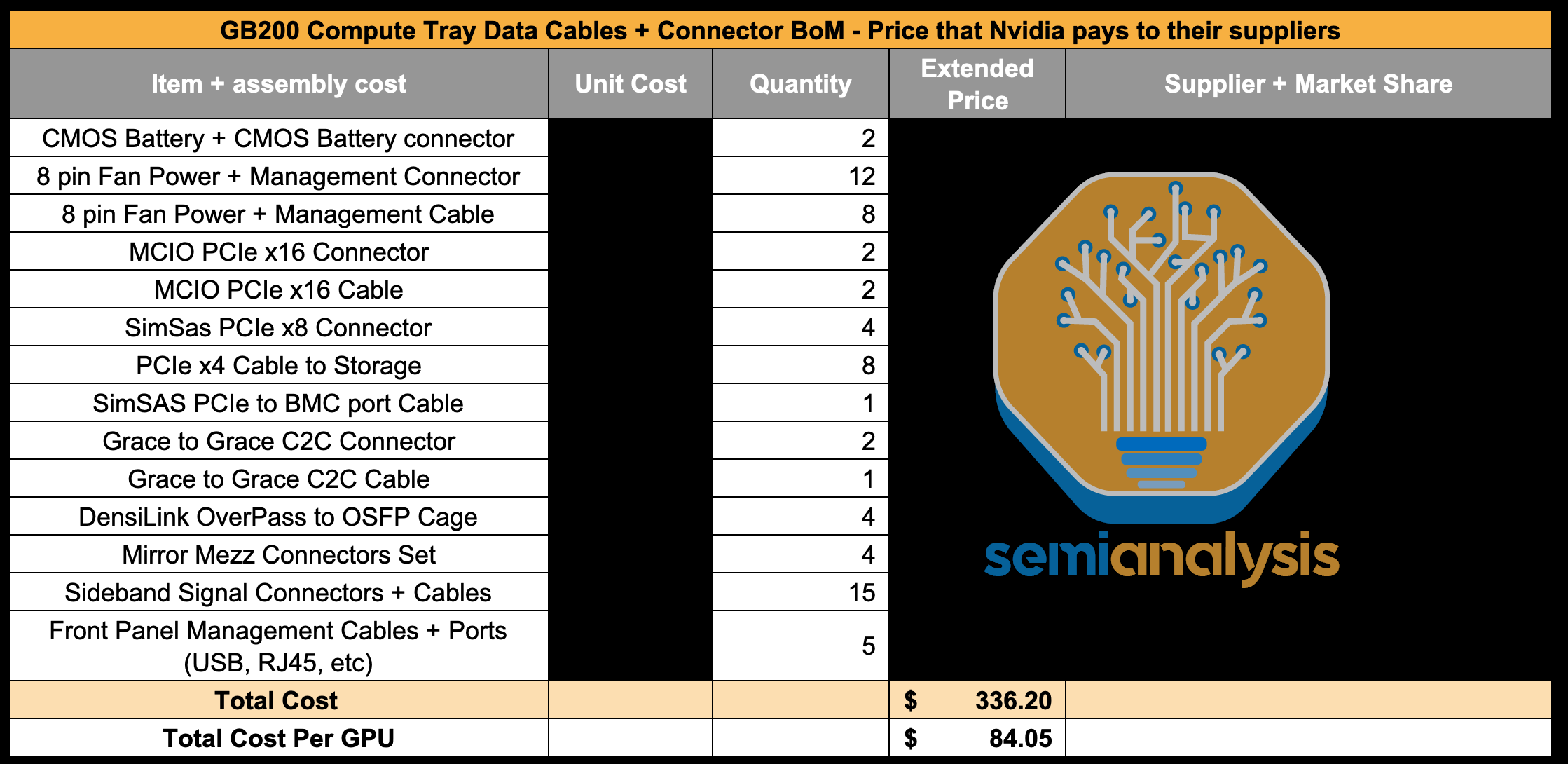
来源:SemiAnalysis GB200 组件与供应链模型
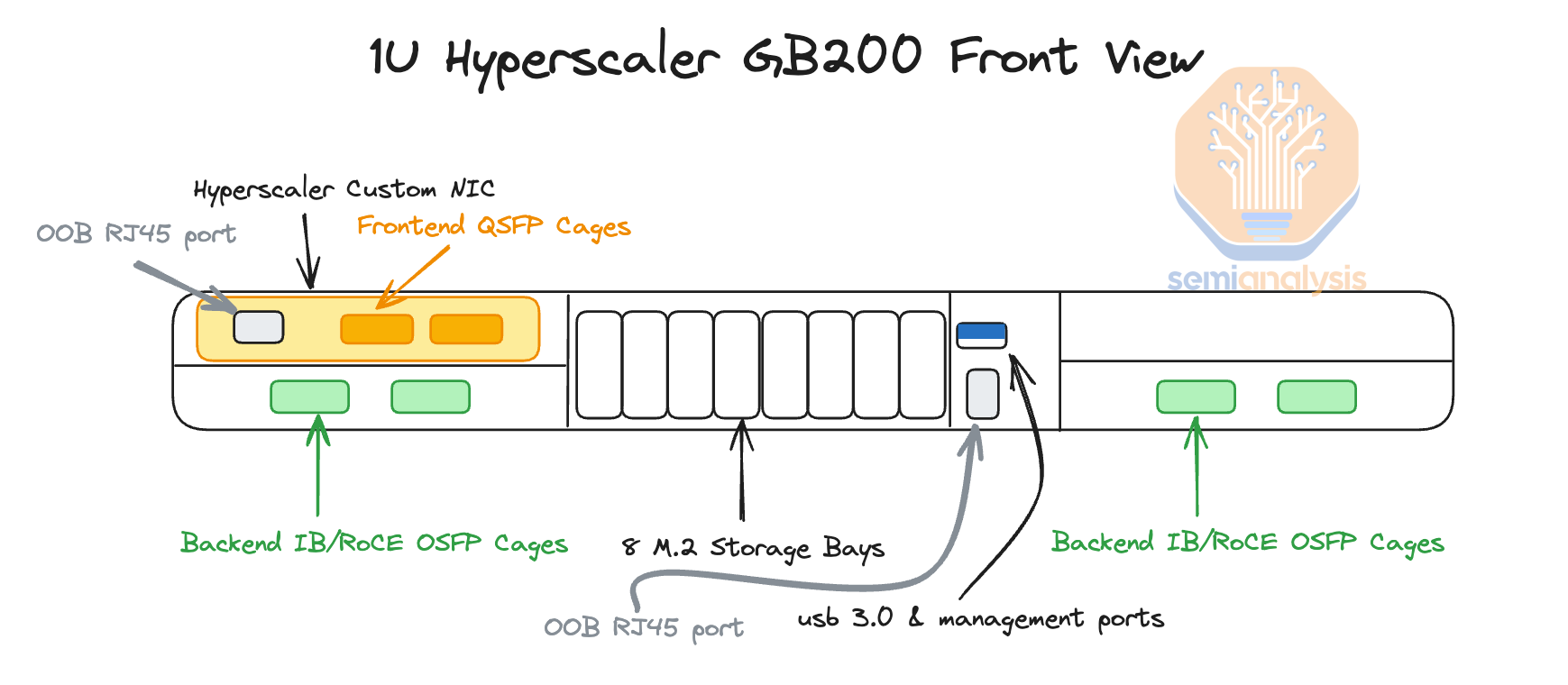
In the Nvidia reference design, there are two Bluefield-3s per compute tray, but as explained in later sections, we believe that most firms will not opt for any Bluefield-3 at all. At the front of the chassis, you can find all your typical server-related management ports, like RJ45, USB, etc. There are also eight NVMe storage bays for local node-level storage, and you can also find your scale-out backend OSFP cages.
在 Nvidia 参考设计中,每个计算托盘有两个 Bluefield-3,但正如后面部分所解释的,我们认为大多数公司根本不会选择任何 Bluefield-3。在机箱前面,您可以找到所有典型的服务器相关管理端口,如 RJ45、USB 等。还有八个 NVMe 存储槽用于本地节点级存储,您还可以找到扩展后端 OSFP 机箱。
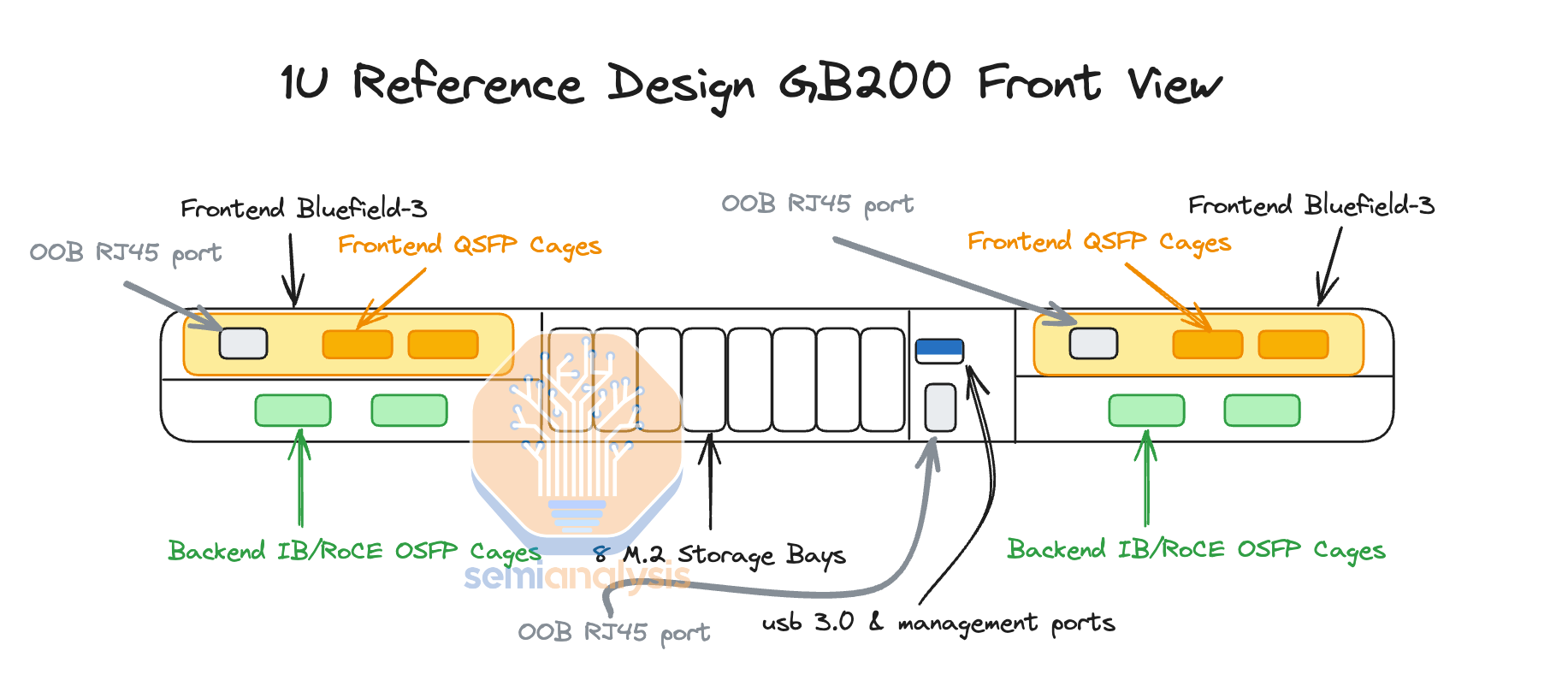
The backend cage leads us to discuss one of the most critical pieces of the GB200: networking.
后端笼子引导我们讨论 GB200 最关键的部分之一:网络。
Networking 网络连接
Similar to the HGX H100, AMD MI300X, Intel Gaudi, AWS Trainium, there are 4 different networks in the GB200 systems:
与 HGX H100、AMD MI300X、Intel Gaudi、AWS Trainium 类似,GB200 系统中有 4 个不同的网络:
Frontend Networking (Normal Ethernet)
前端网络(普通 Ethernet)Backend Networking (InfiniBand/RoCE Ethernet)
后端网络(InfiniBand/RoCE 以太网)Accelerator Interconnect (NVLink)
加速器互连(NVLink)Out of Band Networking 带外网络
As a quick refresher, the frontend networking is just your normal ethernet network that you use to connect to the internet, SLURM/Kubernetes, networked storage, data loading, model checkpoints. This network is typically 25-50Gb/s per GPU, so on a HGX H100 server, it will be 200-400Gb/s per server, while on a GB200 computer tray node, it will be 200-800Gb/s per server depending on the configuration.
作为快速回顾,前端网络就是您用来连接互联网、SLURM/Kubernetes、网络存储、数据加载和模型检查点的普通以太网网络。该网络通常为每个 GPU 提供 25-50Gb/s 的带宽,因此在 HGX H100 服务器上,每台服务器的带宽为 200-400Gb/s,而在 GB200 计算机托盘节点上,根据配置,每台服务器的带宽为 200-800Gb/s。
Your backend network is used to scale out GPU-GPU communications across hundred to thousands of racks. This network could either be Nvidia’s Infiniband or Nvidia Spectrum-X Ethernet or Broadcom Ethernet. With the options from Nvidia being way more expensive compared to the Broadcom Ethernet solutions.
您的后端网络用于在数百到数千个机架之间扩展 GPU-GPU 通信。该网络可以是 Nvidia 的 Infiniband、Nvidia Spectrum-X 以太网或博通以太网。与博通以太网解决方案相比,Nvidia 的选项要昂贵得多。
The scale-up accelerator interconnect (NVLink on Nvidia, Infinity Fabric/UALink on AMD, ICI on Google TPU, NeuronLink on Amazon Trainium 2) is an ultra-high speed network that connects GPUs together within a system. On Hopper, this network connected 8 GPUs together at 450GB/s each while on Blackwell NVL72, it will connect 72 GPUs together at 900GB/ each. There is a variant of Blackwell called NVL576 that will connect 576 GPUs together but basically no customers will opt for it. In general, your accelerator interconnect is 8-10x faster than your backend networking.
扩展加速器互连(Nvidia 的 NVLink,AMD 的 Infinity Fabric/UALink,Google TPU 的 ICI,Amazon Trainium 2 的 NeuronLink)是一种超高速网络,能够在系统内将 GPU 连接在一起。在 Hopper 上,该网络将 8 个 GPU 以每个 450GB/s 的速度连接在一起,而在 Blackwell NVL72 上,它将以每个 900GB/s 的速度连接 72 个 GPU。有一种名为 NVL576 的 Blackwell 变体,可以连接 576 个 GPU,但基本上没有客户会选择它。一般来说,您的加速器互连速度比后端网络快 8-10 倍。
Lastly, there is your out of band management network which is used for re-imaging your operating system, monitor node health such as fan speed, temperatures, power draw, etc. Your baseboard management controller (BMC) on servers, PDUs, switches, CDUs are usually connected to this network to monitor and control these IT equipment.
最后,还有您的带外管理网络,用于重新映像您的操作系统,监控节点健康状况,如风扇速度、温度、电力消耗等。服务器、PDU、交换机、CDU 上的基础板管理控制器(BMC)通常连接到此网络,以监控和控制这些 IT 设备。
NVLink Scale Up Interconnect
NVLink 扩展互连
Compared to HGX H100, the frontend, backend and out of band networking of GB200 are mostly same with the exception of NVLink expanding outside of the chassis. Only hyperscaler customizations are different gen on gen. Previously in HGX H100, the 8 GPUs and 4 NVSwitch4 Switch ASICs are connected together using PCB traces as they are on the same PCB, the HGX baseboard.
与 HGX H100 相比,GB200 的前端、后端和带外网络大部分相同,唯一的例外是 NVLink 扩展到机箱外。只有超大规模定制在不同代之间有所不同。在 HGX H100 中,8 个 GPU 和 4 个 NVSwitch4 交换 ASIC 通过 PCB 走线连接在一起,因为它们位于同一块 PCB 上,即 HGX 主板。
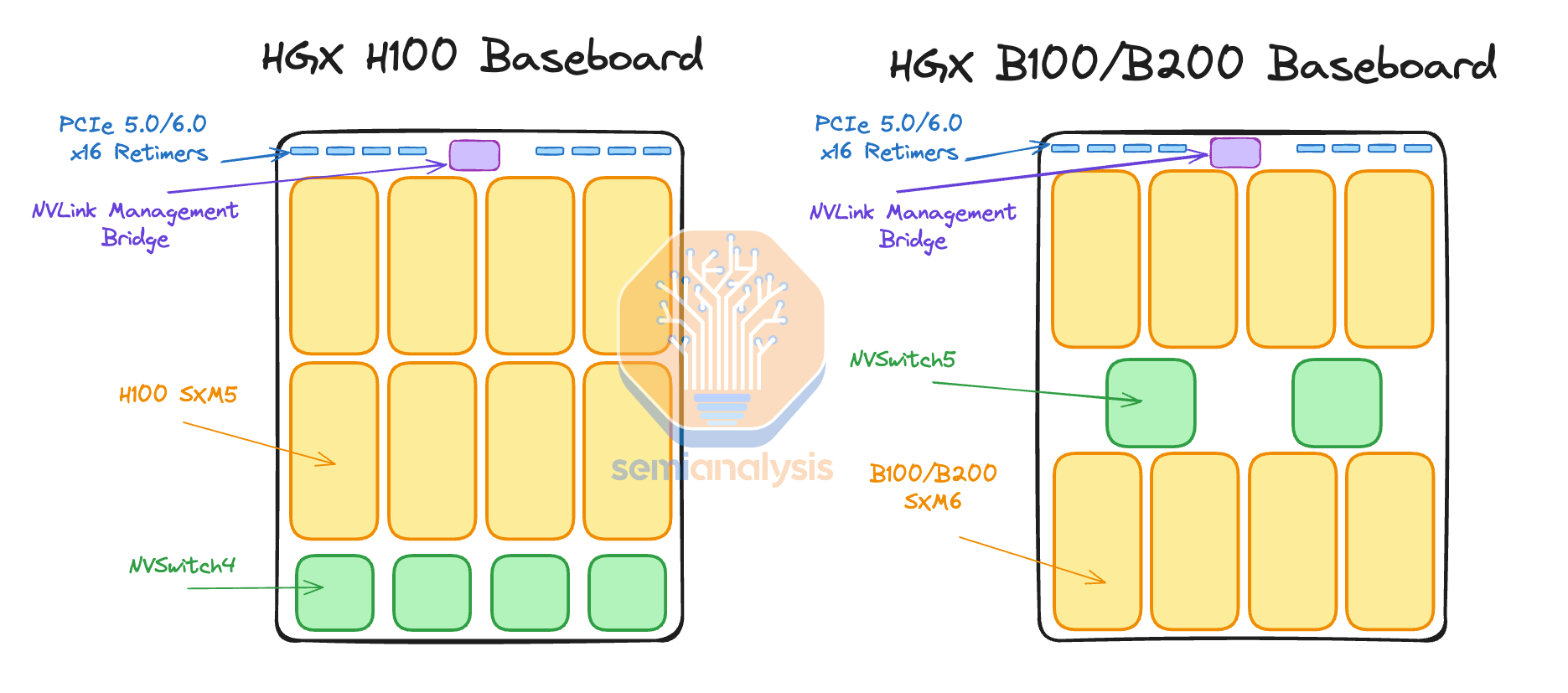
Now on HGX Blackwell, the NVSwitch ASICs are in the middle to reduce the length of the PCB trace given the upgraded 224G SerDes
现在在 HGX Blackwell 上,NVSwitch ASIC 位于中间,以减少 PCB 走线的长度,考虑到升级的 224G SerDes
But on the GB200, the NVSwitches are on a different tray from GPUs and therefore you need to either use Optics or ACCs to connect between them.
但在 GB200 上,NVSwitch 位于与 GPU 不同的托盘上,因此您需要使用光纤或 ACCs 进行连接。

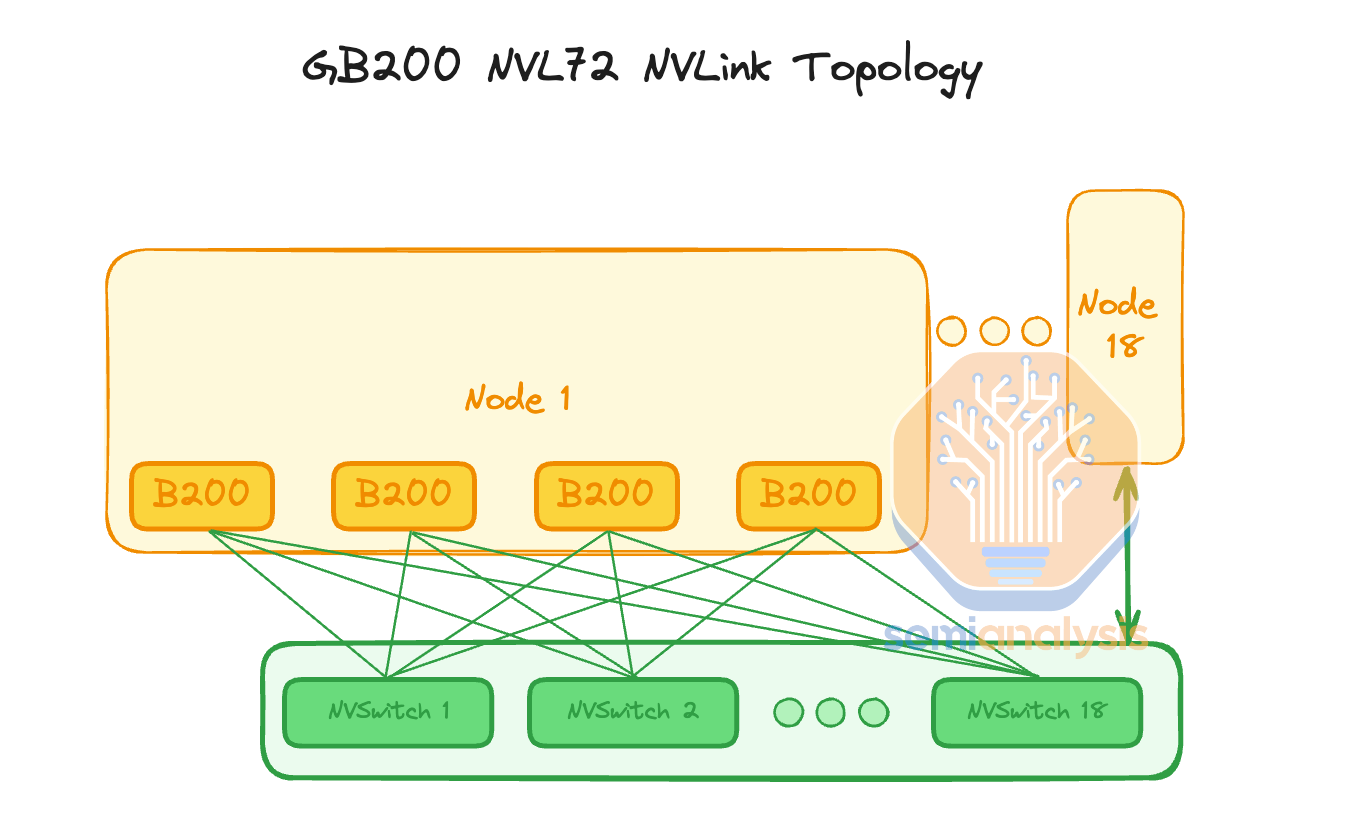
In NVL72, they keep the same flat 1 tier NVLink topology as HGX Hopper/Blackwell such that you can talk to any of the GPUs within the same rack with only 1 hop through an NVSwitch. This is unlike AMD & Intel’s current generation interconnect which connects directly from GPU to GPU without a switch, which leads to reduced Accelerator to Accelerator bandwidth.
在 NVL72 中,他们保持与 HGX Hopper/Blackwell 相同的平面 1 层 NVLink 拓扑,这样您可以通过一个 NVSwitch 与同一机架内的任何 GPU 进行通信,仅需 1 次跳转。这与 AMD 和 Intel 当前一代互连不同,后者直接从 GPU 连接到 GPU 而不使用交换机,这导致加速器之间的带宽降低。
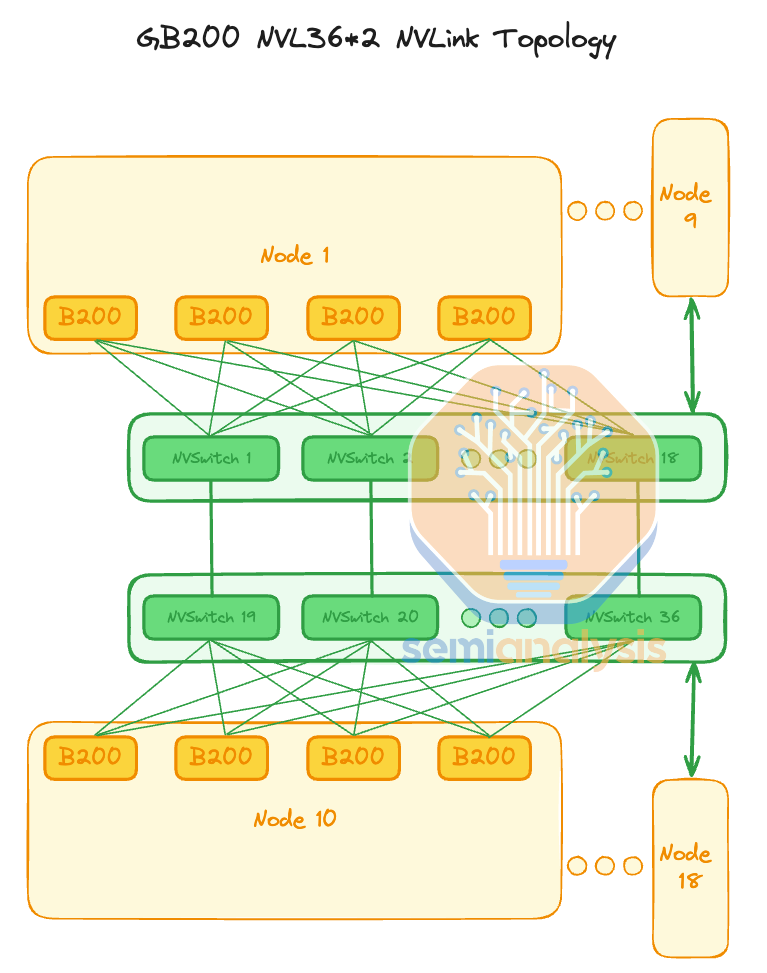
In NVL36x2, it only takes 1 hop to get to any of the 36 GPUs within the same rack but in order to talk to the other 36 GPUs in the rack beside it, it takes 2 NVSwitch hops to get across the racks. Intuitively, one additional hop adds latency but is not noticeable for training. It will slightly impact inference, but not too much unless extremely high interactivity (>500TPS) at batch 1 without speculative decoding is the target. Note that is quite an unrealistic scenario we don’t expect anyone to utilize.
在 NVL36x2 中,只需 1 次跳跃即可到达同一机架内的 36 个 GPU,但要与相邻机架中的其他 36 个 GPU 通信,则需要 2 次 NVSwitch 跳跃。直观上,额外的跳跃会增加延迟,但在训练中并不明显。它会对推理产生轻微影响,但除非目标是在没有预测解码的情况下,在批次 1 时达到极高的交互性(>500TPS),否则影响不大。请注意,这是一种相当不现实的场景,我们不期望有人会利用。
Nvidia claims that if they used optics with transceivers, they would have needed to add 20kW per NVL72 rack. We did the math and calculated that it would need to use 648 1.6T twin port transceivers with each transceiver consuming approximately 30Watts so the math works out to be 19.4kW/rack which is basically the same as Nvidia’s claim. At about $850 per 1.6T transceiver, this works out to be $550,800 per rack in just transceiver costs alone. When you mark that up by Nvidia’s 75% gross margin, that would mean $2,203,200 per rack of NVLink transceivers that the end customer would need to pay. This is one of the main reasons why DGX H100 NVL256 never shipped due to the massive cost of transceivers. Furthermore, bleeding edge transceivers like the 1.6T NVLink transceivers have way worse reliability compared to copper cables or even prior generation optics.
Nvidia 声称,如果他们使用带有收发器的光学设备,他们将需要为每个 NVL72 机架增加 20kW。我们进行了计算,得出需要使用 648 个 1.6T 双端口收发器,每个收发器消耗约 30 瓦特,因此计算结果为 19.4kW/机架,这基本上与 Nvidia 的说法一致。每个 1.6T 收发器约为 850 美元,这仅收发器成本就达到了每个机架 550,800 美元。当按 Nvidia 的 75%毛利率加价时,最终客户需要支付每个 NVLink 收发器机架 2,203,200 美元。这是 DGX H100 NVL256 从未发货的主要原因之一,因为收发器的成本巨大。此外,像 1.6T NVLink 收发器这样的尖端收发器与铜缆甚至前一代光学设备相比,可靠性要差得多。
As such, this is the reason Nvidia chose to use 5184 copper cables, which is a much cheaper, less power hungry, and more reliable option. Each GPU has 900GB/s unidirectional bandwidth. Each differential pair (DP) is capable of transmitting 200Gb/s in 1 direction thus it will take 72 DP per GPU for both directions. Since there are 72 GPUs per NVL72 rack, that would mean there is 5184 differential pairs. Each NVLink cable contains 1 differential pair thus there are 5184 cables.
因此,这就是 Nvidia 选择使用 5184 根铜缆的原因,这是一种更便宜、功耗更低且更可靠的选择。每个 GPU 具有 900GB/s 的单向带宽。每对差分信号对(DP)能够在一个方向上传输 200Gb/s,因此每个 GPU 需要 72 对 DP 来支持双向传输。由于每个 NVL72 机架有 72 个 GPU,这意味着总共有 5184 对差分信号对。每根 NVLink 电缆包含 1 对差分信号对,因此总共有 5184 根电缆。
This is a massive increase in copper content generation on generation. In a bit of a whiplash, we have seen some investors estimate that there is around $3k of NVLink interconnect content per GPU bringing the total to $216k/NVL72 rack but this is completely wrong.
这是一个铜含量代际之间的巨大增加。在一些反转中,我们看到一些投资者估计每个 GPU 大约有 3000 美元的 NVLink 互连内容,使得 NVL72 机架的总额达到 216,000 美元,但这是完全错误的。

First of all, how did people even get to ridiculous numbers such as $3k per GPU? We believe that they took the 900GB/s (7200Gb/s) of unidirectional bandwidth per GPU and looked at the retail price of a 400Gb/s copper cable at $162. Since it takes 18 400Gb/s full duplex cables per GPU, that would bring the price per GPU to $3k. This figure is wrong by a massive margin.
首先,人们是如何得出每个 GPU 高达$3k 的荒谬数字的?我们认为他们考虑了每个 GPU 的 900GB/s(7200Gb/s)单向带宽,并查看了 400Gb/s 铜缆的零售价格为$162。由于每个 GPU 需要 18 根 400Gb/s 全双工电缆,这将使每个 GPU 的价格达到$3k。这个数字的误差非常巨大。
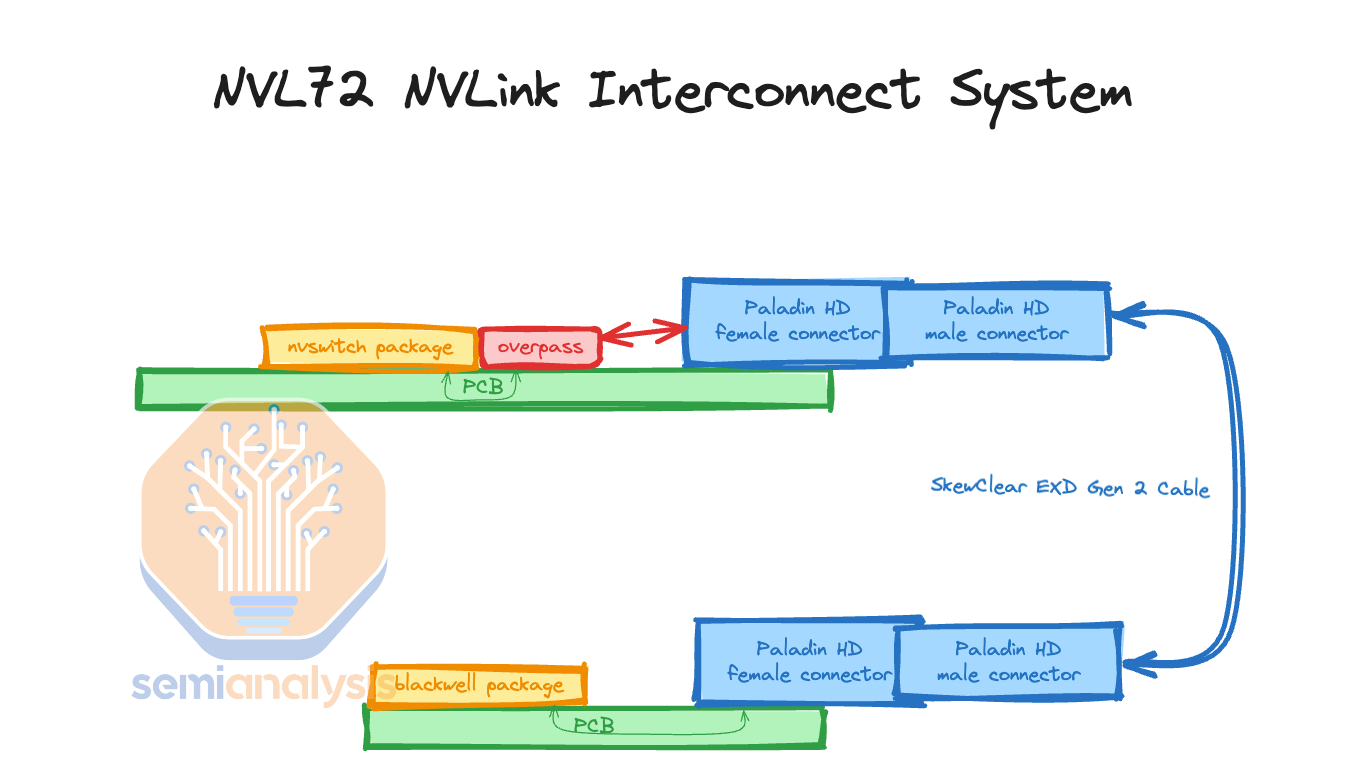
Furthermore, there is a misconception that the cables are expensive. Most of the cost is not from the cables itself but instead in termination of the cables & the connectors. The connectors are expensive as they need to prevent crosstalk between different differential pairs. Crosstalk is extremely bad as it blurs out other signals and causes errors where the de-serializers can’t read the correct bits. Nvidia has chosen to use the Ultrapass Paladin backplane product from Amphenol for their NVLink backplane interconnect as the primary initial source.
此外,有一种误解认为电缆很昂贵。大部分成本并不来自电缆本身,而是来自电缆的终端和连接器。连接器价格昂贵,因为它们需要防止不同差分对之间的串扰。串扰极其糟糕,因为它会模糊其他信号并导致解串器无法读取正确的位。Nvidia 选择使用 Amphenol 的 Ultrapass Paladin 背板产品作为其 NVLink 背板互连的主要初始来源。
We will use the primary source’s name for each connector and cable in the article, but the there are 3 sources with varying share over time, details of which we share in the full GB200 Component & Supply Chain Model
我们将在文章中使用每个连接器和电缆的主要来源名称,但有 3 个来源的市场份额随时间变化,具体细节我们在完整的 GB200 组件和供应链模型中分享

Each Blackwell GPU is connected to an Amphenol Paladin HD 224G/s connector, each with 72 differential pairs. Then, that connector attaches to the backplane Paladin connector. Next, it will connect using SkewClear EXD Gen 2 Cable to the NVSwitch tray Paladin HD connector with 144 differential pairs per connector. From the NVSwitch Paladin connector to the NVSwitch ASIC chip, OverPass flyover cables are needed since there are 4 144 DP connectors (576 DPs) per switch tray and there would be way too much crosstalk to do PCB traces in such a small area. Furthermore loss over the PCB is worse than over the flyover cables.
每个 Blackwell GPU 都连接到一个 Amphenol Paladin HD 224G/s 连接器,每个连接器有 72 对差分信号对。然后,该连接器连接到背板 Paladin 连接器。接下来,它将使用 SkewClear EXD Gen 2 电缆连接到 NVSwitch 托盘 Paladin HD 连接器,每个连接器有 144 对差分信号对。从 NVSwitch Paladin 连接器到 NVSwitch ASIC 芯片,需要使用 OverPass 飞越电缆,因为每个开关托盘有 4 个 144 DP 连接器(576 DP),在如此小的区域内进行 PCB 布线会产生过多的串扰。此外,PCB 上的损耗比飞越电缆上的损耗更严重。
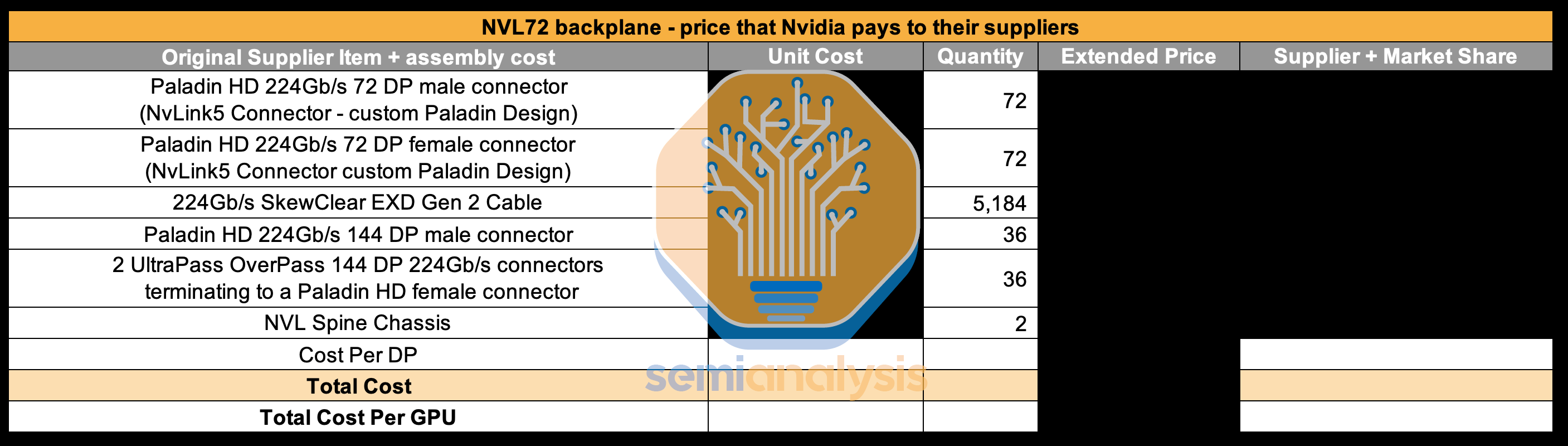
来源:SemiAnalysis GB200 组件与供应链模型
With NVL36x2, each system will require an additional 162 1.6T twin-port horizontal ACC cables which are extremely pricey to connect the NVSwitch trays between Rack A and Rack B. We break down the ACC cable and chip market here. There are multiple players with significant share. Furthermore, an additional 324 DensiLink flyover cables will be required for the OSFP cages. These DensiLink flyover cables alone are more than $10,000 of additional cost per NVL36x2.
使用 NVL36x2,每个系统将需要额外的 162 条 1.6T 双端口水平 ACC 电缆,这些电缆非常昂贵,用于连接机架 A 和机架 B 之间的 NVSwitch 托盘。我们在这里分析 ACC 电缆和芯片市场。市场上有多个占有 significant 份额的参与者。此外,OSFP 机箱还需要额外的 324 条 DensiLink 飞越电缆。这些 DensiLink 飞越电缆的额外成本每个 NVL36x2 超过 10,000 美元。
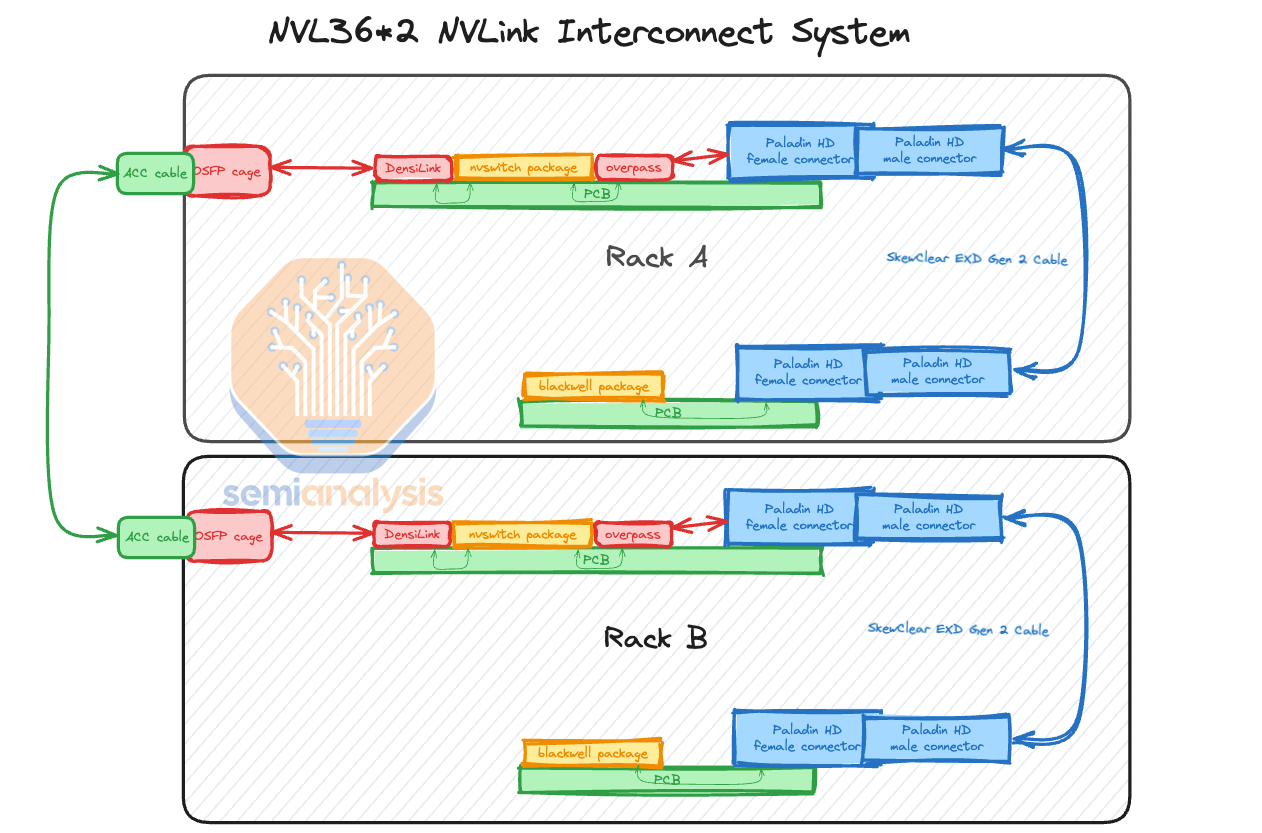
Moreover, it will require twice as many NVSwitch5 ASICs to enable the connection between Rack A and Rack B. This will bring the total NVLink copper cabling costs up by more than double versus NVL72.
此外,连接机架 A 和机架 B 将需要两倍数量的 NVSwitch5 ASIC。这将使 NVLink 铜缆的总成本比 NVL72 增加超过两倍。
Even though the NVLink backplane content is more than twice as expensive for NVL36x2 vs NVL72, most customers will opt for the NVL36x2 design due to power and cooling constraints which we will discuss below. To be clear while it is very pricey, both NVL36x2 and NVL72 have lower copper costs than the investor community thinks.
尽管 NVLink 背板的内容对于 NVL36x2 的成本是 NVL72 的两倍多,但大多数客户将选择 NVL36x2 设计,因为我们将在下面讨论的电源和冷却限制。需要明确的是,尽管价格非常高,但 NVL36x2 和 NVL72 的铜成本都低于投资者社区的预期。
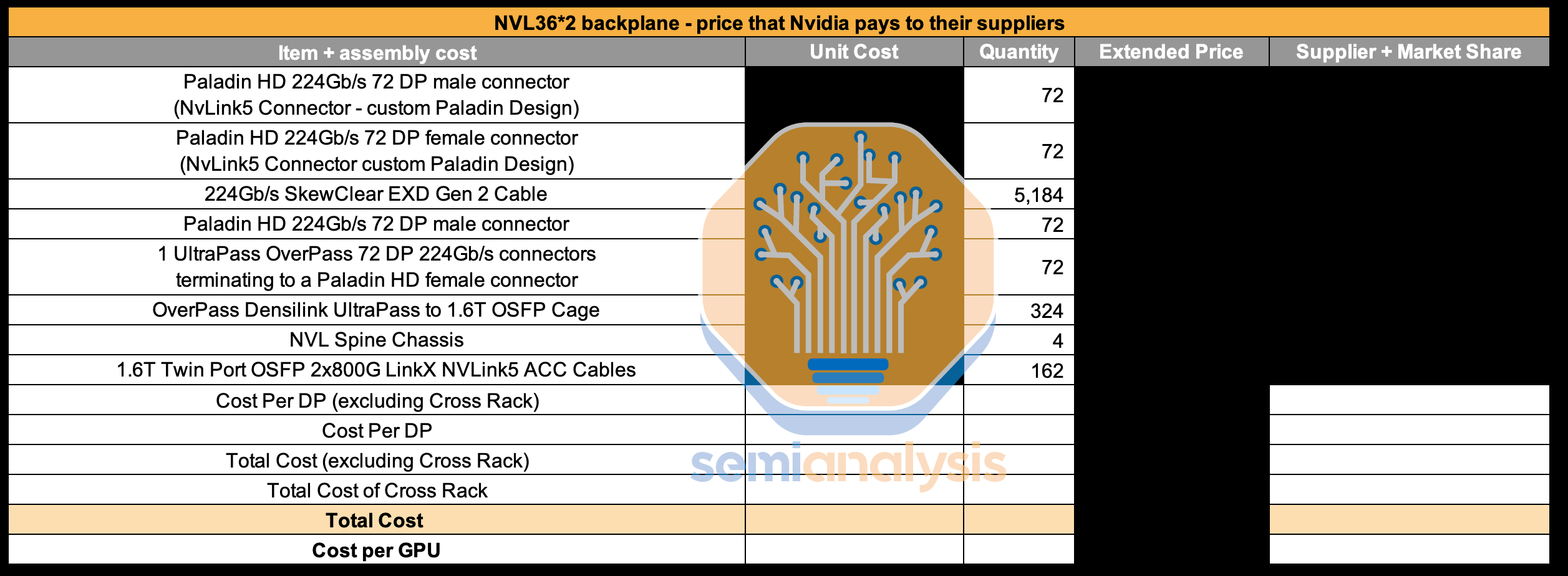
来源:SemiAnalysis GB200 组件与供应链模型
The real winner is the cabling vendors and active copper chip vendors in the supply chain who have a massive increase in volumes for leading edge 1.6T due to the prevalence of NVL36x2.
真正的赢家是供应链中的电缆供应商和活跃的铜芯片供应商,由于 NVL36x2 的普及,领先边缘 1.6T 的销量大幅增加。
GB200 NVL576
As Jensen mentioned on stage, GB200 NVLink can connect to 576 Blackwell GPUs together. We believe this is done using a 2 tier fat tree topology with 18 planes. This is similar to what they planned for DGX H100 NVL256 to connect 16 NVL36 racks. It will use 288 L1 NVSwitch5 ASICs (144 1U switch trays) located in the compute racks like NVL36x2, and it will use 144 L2 NVSwitch ASICs (72 2U switch trays) located on dedicated NV Switch trays. Like NVL36x2, the connection between the GPUs and the L1 NVSwitch will use the same copper backplane since it is over a short distance.
正如詹森在台上提到的,GB200 NVLink 可以将 576 个 Blackwell GPU 连接在一起。我们相信这是通过 18 个平面的 2 层胖树拓扑实现的。这与他们为 DGX H100 NVL256 计划连接 16 个 NVL36 机架的方案类似。它将使用 288 个 L1 NVSwitch5 ASIC(144 个 1U 交换机托盘),位于像 NVL36x2 这样的计算机机架中,并将使用 144 个 L2 NVSwitch ASIC(72 个 2U 交换机托盘),位于专用的 NV 交换机托盘上。与 NVL36x2 一样,GPU 与 L1 NVSwitch 之间的连接将使用相同的铜背板,因为距离较短。
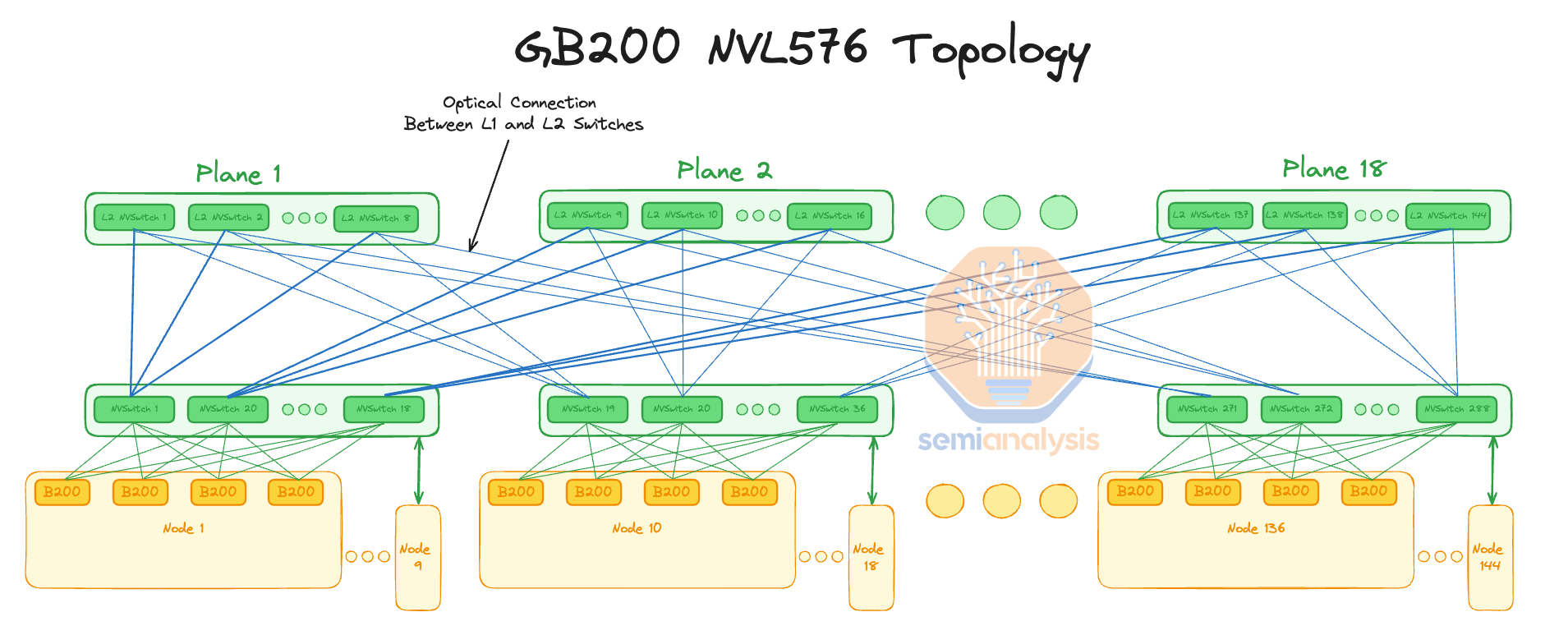
Unfortunately, between the L1 NVSwitch and the L2 NVSwitch, the distance is greater than what copper can achieve; thus, optical connections must be used. Furthermore, the L2 NVSwitches use Flyover cables to go to the OSFP cages on the front of the chassis. The additional BOM cost for NVL576 is astronomical at over $5.6 million dollars (9.7k per GPU) that Nvidia would need to pay to their suppliers.
不幸的是,L1 NVSwitch 和 L2 NVSwitch 之间的距离超过了铜缆所能达到的范围;因此,必须使用光连接。此外,L2 NVSwitch 使用 Flyover 电缆连接到机箱前面的 OSFP 笼。NVL576 的额外 BOM 成本高达超过 560 万美元(每个 GPU 9.7k),这是 Nvidia 需要支付给其供应商的费用。
Applying a blanket 75% gross margin means customers would need to pay an additional 38.8k per GPU for NVL576 copper + optical connections. While Nvidia can cut back on margins, even at 0% for the scale out NVLink solution, it’s basically untenable. This is the exact same reason to why DGX H100 NVL256 never shipped due to the massive cost of transceivers. Optics is far too expensive for the accelerator interconnect as the accelerator interconnect needs to be extremely high bandwidth.
应用 75%的毛利率意味着客户需要为 NVL576 铜+光学连接支付额外的 38.8k 每个 GPU。虽然 Nvidia 可以降低利润率,即使在 NVLink 解决方案的规模扩展中为 0%,这基本上是不可行的。这正是 DGX H100 NVL256 从未发货的原因,因为收发器的成本巨大。光学连接对于加速器互连来说过于昂贵,因为加速器互连需要极高的带宽。

来源:SemiAnalysis GB200 组件与供应链模型
Backend Networking 后端网络
The backend networking of GB200 is where most of the options crop up. Nvidia generally releases GPUs with the new generation of NIC and Switch ready to go, but this generation, due to Nvidia’s aggressive timelines, especially with 224G SerDes, the new networking comes halfway through the Blackwell generation. As such, all initial shipments of GB200 will utilize the same ConnectX-7 that shipped in the majority of H100 servers.
GB200 的后端网络是大多数选项出现的地方。Nvidia 通常会发布与新一代 NIC 和交换机准备好的 GPU,但由于 Nvidia 的激进时间表,特别是 224G SerDes,这一代的新网络在 Blackwell 世代的中途推出。因此,所有 GB200 的初始发货将使用在大多数 H100 服务器中发货的相同 ConnectX-7。
For the Backend Networking there a handful of different types of switches that customers will use depending on which NIC they utilize.
对于后端网络,客户将根据他们使用的网络接口卡(NIC)使用几种不同类型的交换机。
Quantum-2 QM9700 Infiniband NDR
量子-2 QM9700 Infiniband NDRQuantum-X800 QM3400 Infiniband XDR
量子-X800 QM3400 Infiniband XDRQuantum-X800 QM3200 Infiniband NDR/XDR
量子-X800 QM3200 Infiniband NDR/XDRSpectrum-X SN5600
Spectrum-X Ultra 光谱-X 超级
Broadcom Tomahawk 5 博通汤姆霍克 5
Broadcom Tomahawk 6 博通汤姆霍克 6
In terms of the backend networking, the time to market shipments will all be the QM9700 Quantum-2 switch or Broadcom Tomahawk 5 just like H100 geneartion. Despite it being the same backend networking hardware, there is a big challenge with utilizing rail optimized designs. This due to the port mismatch between the switch and how many ports there are on a rack. With NVL72, there are 4 GPUs per compute tray, which means in a 4 rail optimized design, each Quantum-2 switch should have 18 downlink ports.
在后端网络方面,市场出货时间将全部使用 QM9700 Quantum-2 交换机或 Broadcom Tomahawk 5,就像 H100 代一样。尽管后端网络硬件相同,但在利用轨道优化设计时面临着很大挑战。这是由于交换机与机架上端口数量之间的不匹配。使用 NVL72 时,每个计算托盘有 4 个 GPU,这意味着在 4 轨道优化设计中,每个 Quantum-2 交换机应该有 18 个下行端口。
Since each switch has the same number of uplink ports in a fat tree, that means only 36 out of the 64 ports will be used. In effect, each switch will have many idle ports. If 2 rails went to each switch, then that would be 72 ports which will be over what the QM9700 Quantum-2 switch offers. In order to utilize all ports within each Quantum-2 switch, there will be 9 non-rail optimized leaf switches for every 4 NVL72 rack.
由于每个交换机在胖树中具有相同数量的上行端口,这意味着只有 64 个端口中的 36 个将被使用。实际上,每个交换机将有许多闲置端口。如果每个交换机连接 2 条轨道,那么将会有 72 个端口,这将超过 QM9700 Quantum-2 交换机所提供的端口数量。为了充分利用每个 Quantum-2 交换机中的所有端口,每 4 个 NVL72 机架将有 9 个非轨道优化的叶子交换机。

For ConnectX-7, you can also use the Q3200 Quantum-3 switch tray which contains 2 independent switches, each with 36 400Gb/s ports. This does not have a port mismatch and can use 4-rail optimized with 4 Q3200 Quantum-X800 Switch per NVL72.
对于 ConnectX-7,您还可以使用 Q3200 Quantum-3 交换机托盘,该托盘包含 2 个独立的交换机,每个交换机具有 36 个 400Gb/s 端口。这没有端口不匹配,并且可以使用 4 轨优化,每个 NVL72 配备 4 个 Q3200 Quantum-X800 交换机。
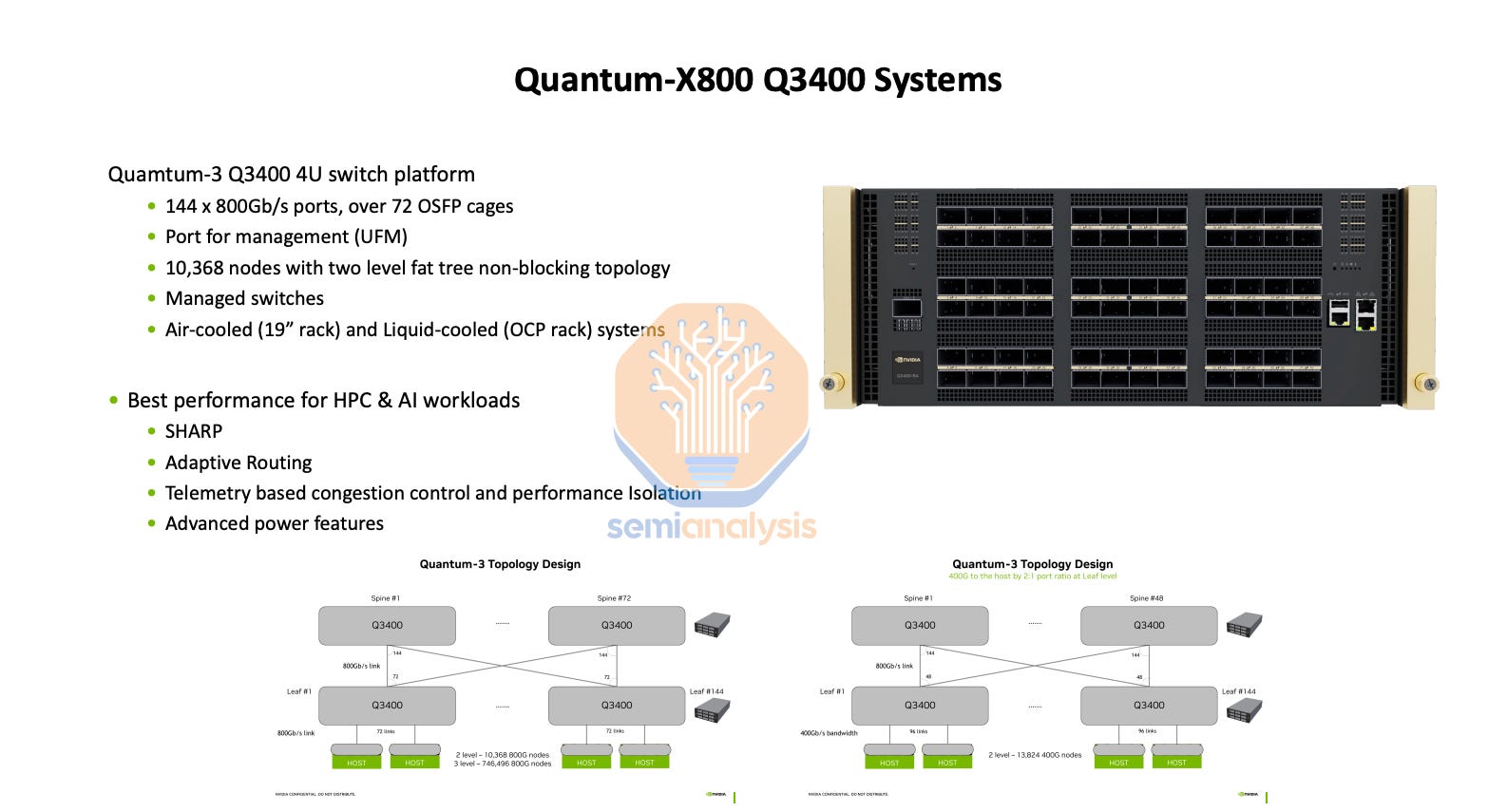
For the upgraded 800Gb/s ConnectX-8, which will ship starting Q2 2025 with Quantum-X800 Q3400 which has 144 800Gb/s ports distributed across 72 twin port OSFP ports. Since there is no port mismatch, most customers will choose the Nvidia recommended design of 4-rail optimized with the switch rack being end of rack (EoR).
对于升级版的 800Gb/s ConnectX-8,将于 2025 年第二季度开始发货,搭配 Quantum-X800 Q3400,该设备拥有 144 个 800Gb/s 端口,分布在 72 个双端口 OSFP 端口上。由于没有端口不匹配,大多数客户将选择 Nvidia 推荐的设计,即 4 轨优化,交换机机架为机架末端(EoR)。
With CX-8, you can also use Spectrum-X Ultra 800G, forgoing the costly and expensive Bluefield option that was required in the prior generation. We discuss the Quantum-X800 switch option here and how it will affect the optical transceiver market. Broadcom based Tomahawk 6 deployment variants will also arrive in the 2nd half of next year.
使用 CX-8,您还可以使用 Spectrum-X Ultra 800G,放弃之前一代所需的昂贵 Bluefield 选项。我们在这里讨论 Quantum-X800 交换机选项及其对光收发器市场的影响。基于 Broadcom 的 Tomahawk 6 部署变体也将在明年下半年到来。
The transition from CX-7 to CX-8 will be the main impetus for the shift from 400G (4x100G) SR4 optical transceivers to 800G (4x200G) DR4 optical transceivers. With CX-7 on the GB200 NVL72, each GPU has 400G of bandwidth and is connected to one OSFP cage with the multimode 400G Single-Port SR4 transceiver with four optical lanes each powered by a multimode 100G VCSEL. With a CX-7 based network, the switch side usually employs the 800G twin-port SR8 or DR8 transceiver.
从 CX-7 到 CX-8 的过渡将是从 400G(4x100G)SR4 光收发器转向 800G(4x200G)DR4 光收发器的主要动力。在 GB200 NVL72 上,CX-7 的每个 GPU 具有 400G 的带宽,并连接到一个 OSFP 机箱,配备四个光通道的多模 400G 单端口 SR4 光收发器,每个通道由一个多模 100G VCSEL 供电。在基于 CX-7 的网络中,交换机端通常使用 800G 双端口 SR8 或 DR8 光收发器。
For CX-8, all the speeds double, 800G (4x200G) DR4 per GPU and 1.6T(8x200G) DR8 per OSFP cage on the switch end. Because development work on the 200G multimode VCSEL will not complete for another 9 to 18 months for the 1.6T ramp, the industry has instead turned to the single mode 200G EML instead.
对于 CX-8,所有速度翻倍,每个 GPU 为 800G(4x200G)DR4,每个 OSFP 机箱在交换机端为 1.6T(8x200G)DR8。由于 200G 多模 VCSEL 的开发工作将在 1.6T 扩展的 9 到 18 个月内完成,行业因此转向了单模 200G EML。
Similar to DGX H100, Cedar-8 will be available where both CX-8 NIC ICs from each Bianca board goes into a single OSFP224 cage. The advantages of requiring two 1.6T (8x200G lanes) twin port transceivers instead of four 800G(4x200G lanes) single port transceivers. Since a single port 4x200G transceiver is approximately 35% less expensive than an 8x200G twin port transceiver, by using Cedar-8 instead of two 4x200G transceivers, the cost will be 30% lower. Due to the cooling challenges of having 2x as much bandwidth in a single OSFP cage on the compute tray, we expect that most firms will not be using the Cedar-8.
类似于 DGX H100,Cedar-8 将在每个 Bianca 板上的两个 CX-8 NIC IC 进入一个单一的 OSFP224 机箱中可用。需要两个 1.6T(8x200G 通道)双端口收发器而不是四个 800G(4x200G 通道)单端口收发器的优势。由于单端口 4x200G 收发器的成本大约比 8x200G 双端口收发器低 35%,通过使用 Cedar-8 而不是两个 4x200G 收发器,成本将降低 30%。由于在计算托盘的单个 OSFP 机箱中拥有 2 倍带宽的冷却挑战,我们预计大多数公司将不会使用 Cedar-8。
Most firms will be sticking to ConnectX-7/ConnectX-8 at launch. Even firms such as Google, that have historically used custom backend NICs from the likes of Intel, will be switching back to the Nvidia ConnectX-8 NICs.
大多数公司在发布时将坚持使用 ConnectX-7/ConnectX-8。即使是像谷歌这样的公司,历史上曾使用来自英特尔等公司的定制后端网卡,也将转回使用 Nvidia ConnectX-8 网卡。
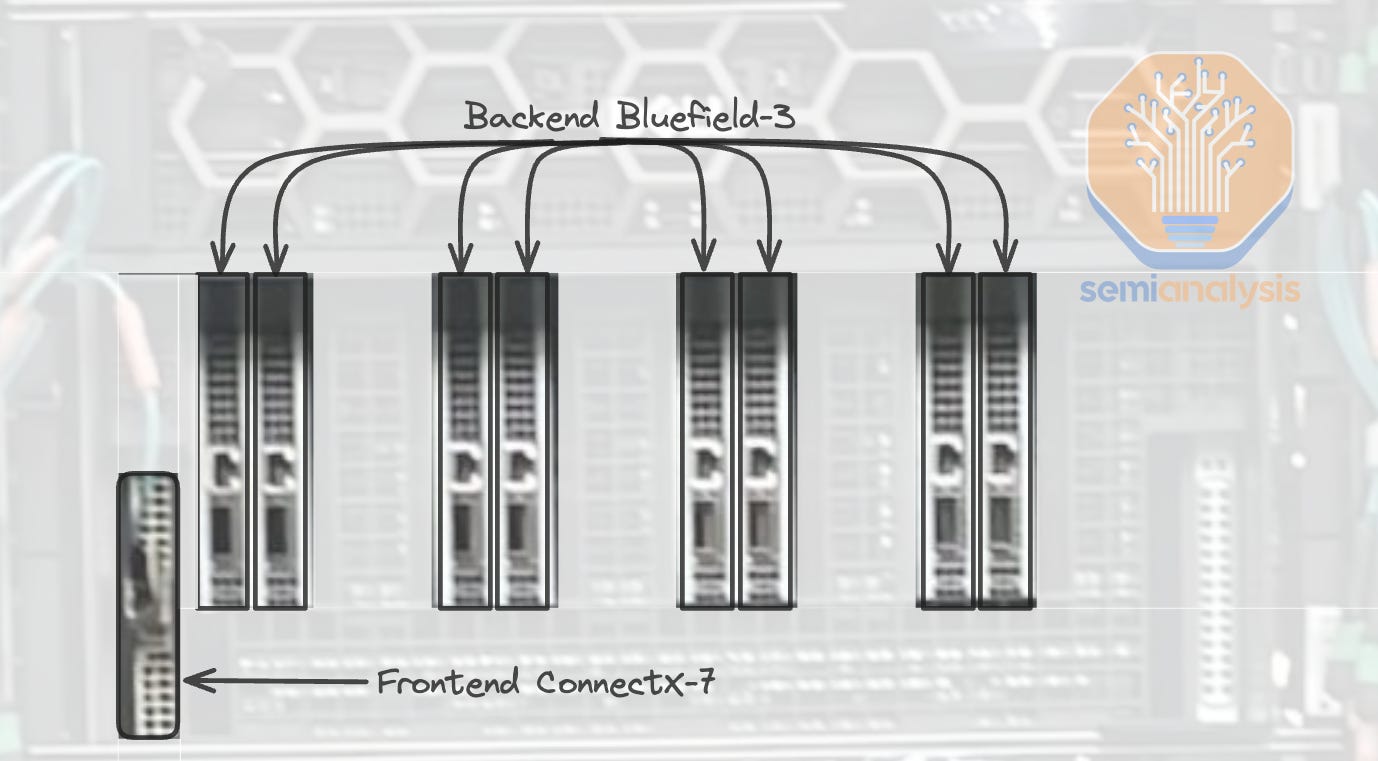
The only exception that will integrate their own backend NIC will be Amazon. We believe they will use their custom backend 400G (4x100G) NIC. This networking card will be different from their standard Nitro NICs as it will mostly be performance oriented.
唯一的例外是亚马逊将集成他们自己的后端 NIC。我们相信他们将使用自定义的后端 400G(4x100G)NIC。该网络卡将与他们的标准 Nitro NIC 不同,因为它主要以性能为导向。
In order to use custom backend NICs on the Bianca board instead of using ConnectX ICs on the mezzanine board, they will need to use an adapter mezzanine board that splits from the mirror mezz connectors into 8 MCIO PCIe connectors that go to the front of the chassis.
为了在比安卡主板上使用自定义后端网卡,而不是在中间板上使用 ConnectX 集成电路,他们需要使用一个适配器中间板,该板将镜像连接器分成 8 个 MCIO PCIe 连接器,连接到机箱前面。

Since there will be no ConnectX-7/8 or Bluefield-3, which both have integrated PCIe switches, a dedicated PCIe switch from Broadcom / Astera Labs will be required to connect the backend NICs to both the CPU and GPU. In SemiAnalysis GB200 Component & Supply Chain Model, we breakdown the PCIe switch supplier, volume, and ASP. There are still hyperscaler custom design that includes PCIe Switches for between the CPU and NICs. Nvidia’s Miranda design is also quite different than GB200 on PCIe Lane Handling. Furthermore Amazon Trainium 2 deployments have large amounts of Astera Labs retimer content.
由于将不会有集成 PCIe 交换机的 ConnectX-7/8 或 Bluefield-3,因此需要来自 Broadcom / Astera Labs 的专用 PCIe 交换机将后端 NIC 连接到 CPU 和 GPU。在 SemiAnalysis GB200 组件和供应链模型中,我们分析了 PCIe 交换机供应商、数量和 ASP。仍然有超大规模定制设计,包括 CPU 和 NIC 之间的 PCIe 交换机。Nvidia 的 Miranda 设计在 PCIe 通道处理方面也与 GB200 有很大不同。此外,亚马逊的 Trainium 2 部署中包含大量 Astera Labs 的重定时器内容。
Using a custom NIC brings extra engineering work to firms as they can’t use the default water cooling block which is engineered to cool the ConnectX ICs too. They would also need to run fresh thermal simulations to ensure that custom NICs in the front of the chassis have enough cooling capacity to not cause overheating problems. Moreover, they will not be able to use the 1U compute tray version used in NVL72.
使用定制的网络接口卡(NIC)会给公司带来额外的工程工作,因为他们无法使用默认的水冷却块,该块也被设计用于冷却 ConnectX 集成电路(IC)。他们还需要进行新的热模拟,以确保机箱前面的定制 NIC 具有足够的冷却能力,以避免过热问题。此外,他们将无法使用在 NVL72 中使用的 1U 计算托盘版本。
They can only opt for the 2U NVL36 version which has enough air-cooling capacity at the front of the tray. All of this extra engineering work will delay the time to market for Amazon and anybody else attempting to use custom backend NICs. These challenges are why Google opted to use ConnectX-8 instead of continuing to use Intel’s IPUs for their GB200 servers.
他们只能选择具有足够前置气冷能力的 2U NVL36 版本。所有这些额外的工程工作将延迟亚马逊和其他任何试图使用定制后端 NIC 的公司的上市时间。这些挑战是谷歌选择使用 ConnectX-8 而不是继续使用英特尔的 IPU 来为其 GB200 服务器服务的原因。
Frontend Networking 前端网络
In the reference design, there are two 400Gb/s Bluefield-3 per compute tray. Since there are 4 GPUs per compute tray, that would mean that each GPU gets 200Gb/s of frontend bandwidth. The most advanced HGX H100 server deployed today has a single 200-400Gb/s ConnectX-7 NIC for their frontend traffic. That is for 8 GPUs, meaning 25-50Gb/s per GPU. 200Gb/s of frontend bandwidth per GPU is an extreme amount and most customers will not opt for this additional cost. In general, the Nvidia reference design is overprovisioned for the absolute worst-case situation for them to sell you more content.
在参考设计中,每个计算托盘有两个 400Gb/s 的 Bluefield-3。由于每个计算托盘有 4 个 GPU,这意味着每个 GPU 获得 200Gb/s 的前端带宽。目前部署的最先进的 HGX H100 服务器为其前端流量配备了单个 200-400Gb/s 的 ConnectX-7 网卡。这是针对 8 个 GPU,意味着每个 GPU 为 25-50Gb/s。每个 GPU 的 200Gb/s 前端带宽是一个极大的数量,大多数客户不会选择这个额外的成本。一般来说,Nvidia 的参考设计在绝对最坏情况下过度配置,以便向您销售更多内容。
We believe that the only major customer that will use Bluefield-3 as a frontend NIC will be Oracle. They run a cloud service that needs frontend network virtualization but have deployed a custom NIC solution, unlike the other hyperscalers. Amazon, Google, & Microsoft all have custom frontend NICs that are present in all their general-purpose CPU servers and accelerated computing servers already. They intend to continue to use these solutions as they offer a great TCO advantage and are already vertically integrated into their networking/cloud software stack.
我们相信,唯一会将 Bluefield-3 作为前端 NIC 使用的主要客户将是 Oracle。他们运营的云服务需要前端网络虚拟化,但与其他超大规模云服务商不同,他们部署了定制的 NIC 解决方案。亚马逊、谷歌和微软都在其所有通用 CPU 服务器和加速计算服务器中使用定制的前端 NIC。他们打算继续使用这些解决方案,因为它们提供了很大的 TCO 优势,并且已经垂直集成到他们的网络/云软件堆栈中。
Ironically, the only firm (xAI) that has widely used Bluefield-3 for the AI cluster is not even using it for its intended DPU purpose. xAI is using their Bluefield-3 in NIC mode instead of DPU mode since first-generation Nvidia Spectrum-X Ethernet requires Bluefield-3 for backend NICs as a bandage solution. Spectrum-X800 Ultra will work with CX-8 backend NICs and will not require Bluefield-3/4s to operate properly.
具有讽刺意味的是,唯一一家广泛使用 Bluefield-3 的公司(xAI)甚至没有将其用于预期的 DPU 目的。xAI 自第一代 Nvidia Spectrum-X 以太网以来,一直将其 Bluefield-3 以 NIC 模式而非 DPU 模式使用,因为这是一种临时解决方案。Spectrum-X800 Ultra 将与 CX-8 后端 NIC 一起工作,并且不需要 Bluefield-3/4 才能正常运行。
来源:SemiAnalysis,迈克尔·戴尔
Networking Cables + Transceivers Bill of Materials
网络电缆 + 收发器物料清单
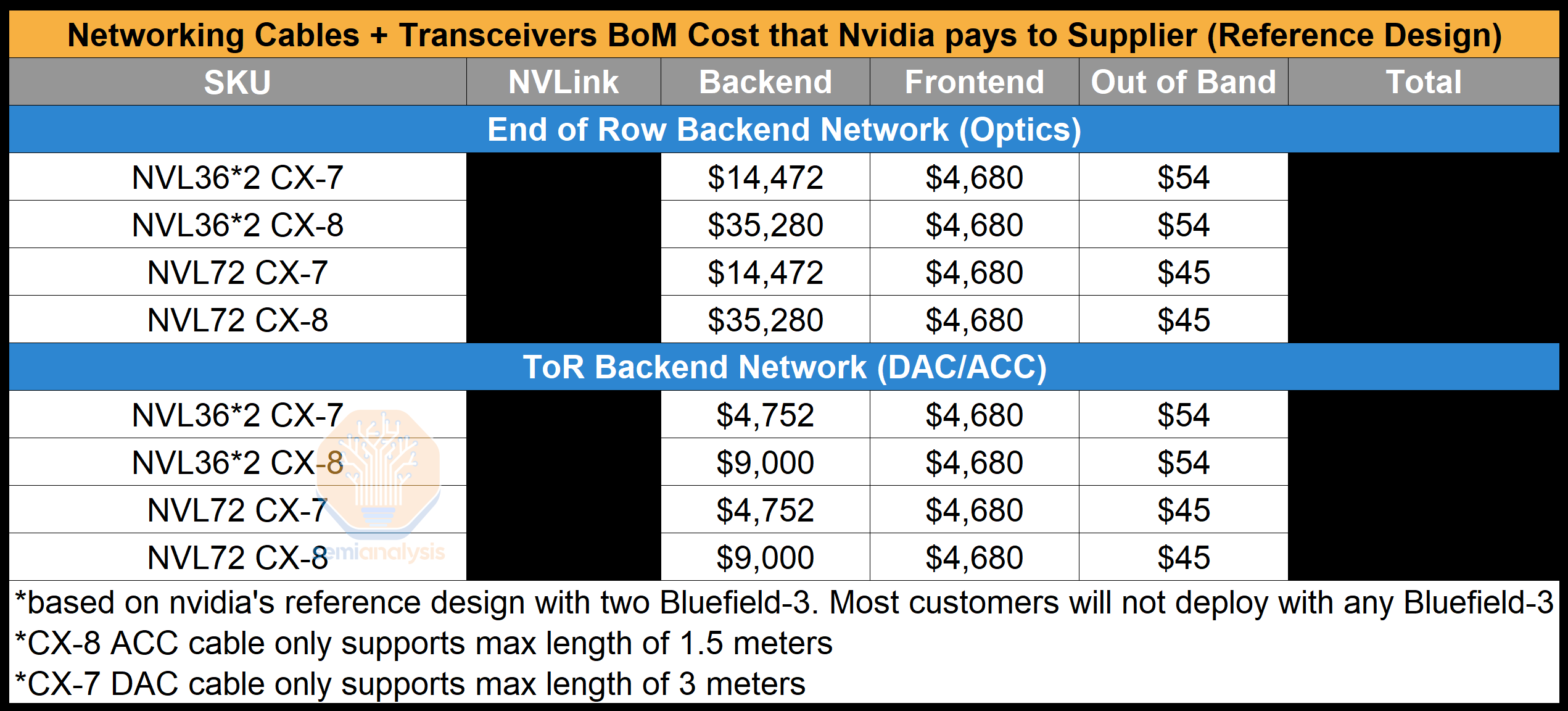
Below, we have calculated the Bill of Material costs Nvidia pays their contract manufacturers. We will be only calculating the cost of the transceivers on the compute/NVSwitch tray end as the calculations get complex if you include switches, as clusters can be tier 2 or tier 3, or even 4 tiers in giant clusters.
以下,我们计算了 Nvidia 支付给其合同制造商的物料清单成本。我们将仅计算计算/NVSwitch 托盘端的收发器成本,因为如果包括交换机,计算会变得复杂,因为集群可以是二级、三级,甚至在大型集群中是四级。
来源:SemiAnalysis GB200 组件与供应链模型
You can see that with ConnectX-8, by using a Top of Rack design with DAC/ACC copper instead of a 4-rail optimized backend design; there are savings of ~$32k for just the backend network alone. Unfortunately, due to the tight power requirements of the compute racks, we believe that most people will have to put their backend switches in a different service rack and use optics to connect between them.
您可以看到,使用 ConnectX-8,通过采用 DAC/ACC 铜缆的机架顶部设计,而不是 4 轨优化的后端设计,仅后端网络就节省了约 32,000 美元。不幸的是,由于计算机机架的严格电力要求,我们认为大多数人将不得不将后端交换机放在不同的服务机架中,并使用光纤进行连接。
For the out of band management, this is all cheap copper RJ45 cables that cost less than a dollar each to connect from the compute/switch trays to the top of the rack out of band management switch. As mentioned above, the reference design is overkill for how much frontend NICs and bandwidth they have. We believe that most firms will have 200G of frontend bandwidth instead of having 2 BF-3 which is 800Gb/s of bandwidth in total per compute tray. This will lead to a saving of $3.5k per system just in transceiver costs alone.
对于带外管理,这些都是便宜的铜 RJ45 电缆,每条成本不到一美元,用于将计算/交换机托盘连接到机架顶部的带外管理交换机。如上所述,参考设计对于前端 NIC 和带宽的需求来说过于复杂。我们相信,大多数公司将拥有 200G 的前端带宽,而不是每个计算托盘有 2 个 BF-3,总带宽为 800Gb/s。这将仅在收发器成本上为每个系统节省 3500 美元。
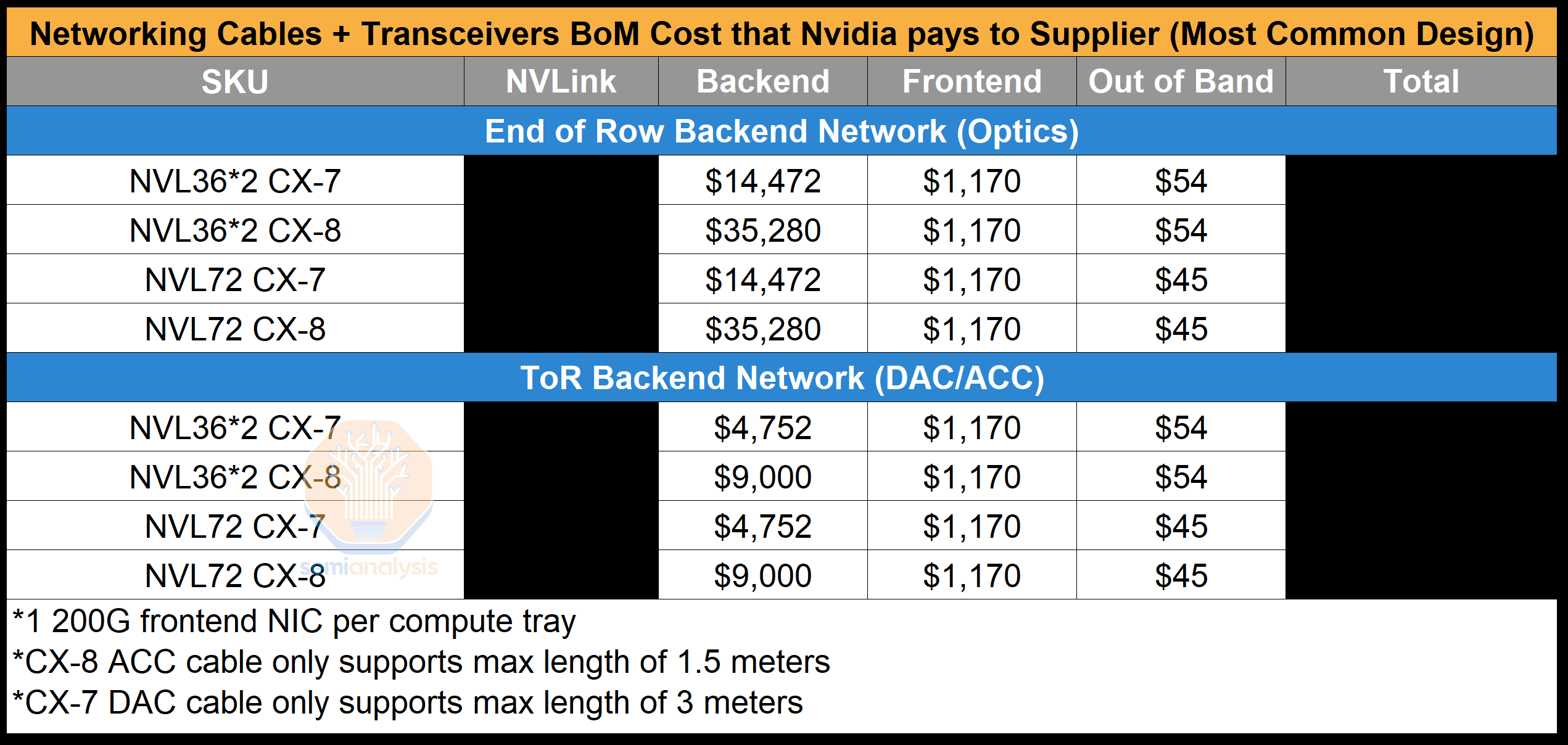
来源:SemiAnalysis GB200 组件与供应链模型
On the optics and DSPs, Nvidia is expanding the supply chain greatly to Eoptolink from just Fabrinet and Innolight who were the vast majority. Eoptolink is focusing on 800G LPO and 1.6T with DSP.
在光学和数字信号处理器方面,英伟达正在大幅扩展供应链,从主要的 Fabrinet 和 Innolight 扩展到 Eoptolink。Eoptolink 专注于 800G LPO 和 1.6T 与 DSP。
The DSP game also changes massively. While Marvell was 100% share on Nvidia last generation with H100. This generation, Broadcom comes in a big way. We see both Innolight and Eoptolink looking to be adding Broadcom in volume for the DSP.
DSP 游戏也发生了巨大的变化。上一代中,Marvell 在 Nvidia 的 H100 上占据了 100%的市场份额。这一代,Broadcom 大举进入。我们看到 Innolight 和 Eoptolink 都在寻求大规模增加 Broadcom 的份额用于 DSP。
Furthermore, Nvidia has hired a number of DSP engineers and taped out a 1.6T DSP. We do not believe this will ramp in the near term, but if it does, it will be on the Fabrinet transceivers. The biggest challenge to ramping up the internal DSP is that Nvidia has used primarily the same long reach high power SerDes on each side of the DSP. Typically, DSPs have differently optimized SerDes on the optics facing vs NIC/Switch facing sides. Both sets of SerDes are optimized for power more than reach alone which was Nvidia’s main optimization point when they designed their 224G SerDes. Nvidia’s internal DSP guzzle too much power, and as such their in-house DSP is too difficult to ramp production of due to cooling challenges in the already toasty 1.6T transceivers. Nvidia’s DSP can also function as a retimer if needed, but the ACCs are enough.
此外,英伟达雇佣了多名 DSP 工程师,并完成了 1.6T DSP 的流片。我们认为这在短期内不会迅速增长,但如果增长,将会在 Fabrinet 的收发器上。内部 DSP 快速增长的最大挑战是,英伟达在 DSP 的每一侧主要使用了相同的长距离高功率 SerDes。通常,DSP 在光学面和 NIC/交换机面上使用不同优化的 SerDes。这两组 SerDes 的优化重点更多在于功耗而非仅仅是距离,这也是英伟达在设计其 224G SerDes 时的主要优化点。英伟达的内部 DSP 消耗的功率过大,因此由于在已经相当炎热的 1.6T 收发器中面临的冷却挑战,其内部 DSP 的生产扩张非常困难。英伟达的 DSP 在需要时也可以作为重定时器,但 ACCs 已经足够。
We have market share and ASP of Optics provider and DSPs in the SemiAnalysis GB200 Component & Supply Chain Model.
我们在 SemiAnalysis GB200 组件和供应链模型中拥有光学供应商和 DSP 的市场份额和平均销售价格(ASP)。
The above only covered the high level and basics, but below, we will dive into all the subcomponents and BOM on the GB200 including substrate, PCB, CCL, Substrate, liquid cooling, Sidecars, CDUs, UQDs, Manifolds, Vapor Chambers, Cold Plates, BMCs, and Power Delivery below. We will also cover more on the hyperscale customization. We will also cover all the complexities and decision matrices for liquid cooling supply chain selections.
上述内容仅涵盖了高层次和基础知识,下面我们将深入探讨 GB200 的所有子组件和物料清单,包括基板、PCB、CCL、基板、液冷、侧车、CDU、UQD、歧管、蒸汽室、冷板、BMC 和电源传输。我们还将进一步讨论超大规模定制。我们还将涵盖液冷供应链选择的所有复杂性和决策矩阵。
Substrate, PCB, and CCL 基板、PCB 和 CCL
Due to the system architecture changes and higher IO / power density, the organic package substrate, CCL (copper clad laminate), glass fiber, and PCB all have big complexity increases from Blackwell HGX and GB200.
由于系统架构的变化以及更高的 IO/功率密度,有机封装基板、CCL(铜覆层板)、玻璃纤维和 PCB 的复杂性均较 Blackwell HGX 和 GB200 有了大幅增加。
The substrate which the Blackwell GPU sits on is larger and also has 2 more layers. In the prior generation, Ibiden dominated with 100% share. This generation, Unimicron becomes a second source of ABF substrates to Ibiden for Blackwell GPU. Moreover, Unimicron is the main supplier of ABF for Grace CPU with Ibiden as second. Unimicron is moving up their capacity expansion dedicated to Nvidia dramatically from 1Q25 to 3Q24 due to big increases in GB200 demand vs B100/B200. Ibiden will still grow, but Unimicron is taking a lot of the slack up.
Blackwell GPU 所在的基板更大,并且有 2 层额外的层。在上一代中,Ibiden 占据了 100% 的市场份额。在这一代中,Unimicron 成为 Ibiden 的第二个 ABF 基板供应商,为 Blackwell GPU 提供支持。此外,Unimicron 是 Grace CPU 的主要 ABF 供应商,而 Ibiden 则是第二供应商。由于 GB200 的需求大幅增加,相比于 B100/B200,Unimicron 正在将其专门用于 Nvidia 的产能扩张从 2025 年第一季度提前到 2024 年第三季度。Ibiden 仍将增长,但 Unimicron 正在承担大量的需求。
We should note there have been significant problems with CoWoS-L ramps for Nvidia, and all the other issues people keep murmuring about are minor in comparison.
我们应该注意到,Nvidia 的 CoWoS-L 坡道存在重大问题,而人们不断低声议论的其他问题相比之下都是次要的。
For the HGX architecture, there are two main boards, the SXM board, the UBB (universal baseboard). One GPU is attached to each SXM board, then 8 SXMs are placed onto one UBB.
对于 HGX 架构,有两个主要板,SXM 板和 UBB(通用底板)。每个 SXM 板上连接一个 GPU,然后将 8 个 SXM 放置在一个 UBB 上。
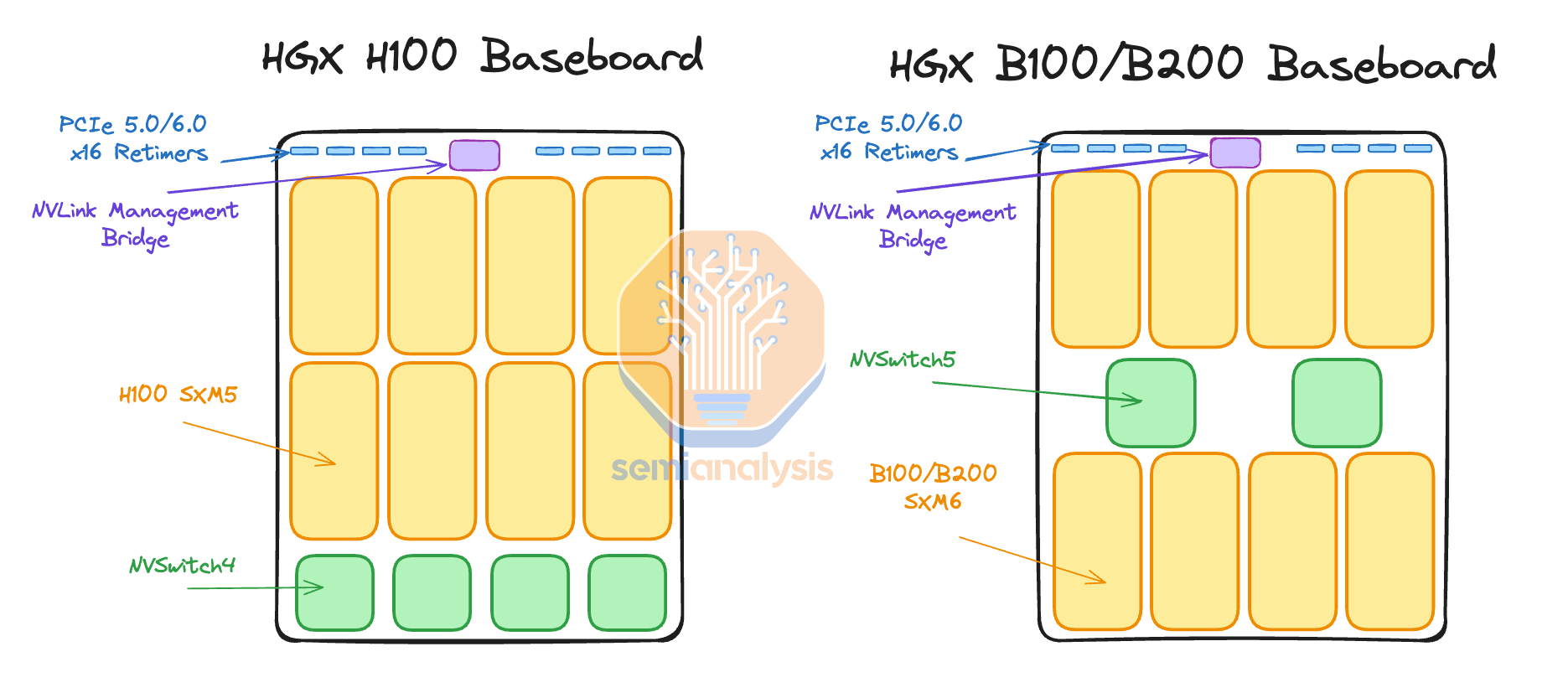
For GB200 architecture, this completely changes as described above. The primary Bianca board is significantly more complex per GPU due to the addition of the CPU, collapse to higher density board with higher power / more IO density. Furthermore, there are a variety of complex daughterboards that demand high grade CCL (M7+) such as the mezzanine ConnectX-7/8. This is because it runs in switch mode connecting the CPU and GPU to each NIC. The NVSwitch board also requires high grade M7 CCL.
对于 GB200 架构,如上所述,这完全改变了。由于增加了 CPU,主要的 Bianca 板每个 GPU 的复杂性显著增加,导致更高密度的板,具有更高的功率/更多的 IO 密度。此外,还有多种复杂的子板需要高等级的 CCL(M7+),例如中间件 ConnectX-7/8。这是因为它以交换模式运行,将 CPU 和 GPU 连接到每个 NIC。NVSwitch 板也需要高等级的 M7 CCL。
The copper clad laminate for Hopper SXM was sole source from EMC and they were the majority supplier on the UBB board as well. With Blackwell, they are losing share on Blackwell SXM and Bianca boards to Doosan. This is likely due to price competition from Doosan, in which EMC chooses not to engage with as EMC will achieve full utilization rates in 3Q24 with other high margin projects like ASICs and LEO Satellites. Lastly, NVSwitch board CCL is M7 grade HDI and is sole supplied by EMC.
Hopper SXM 的铜覆层板由 EMC 独家供应,他们也是 UBB 板的主要供应商。与 Blackwell 相比,他们在 Blackwell SXM 和 Bianca 板上的市场份额正在被斗山夺走。这可能是由于斗山的价格竞争,EMC 选择不参与,因为 EMC 将在 2024 年第三季度通过其他高利润项目如 ASIC 和 LEO 卫星实现满负荷利用率。最后,NVSwitch 板的 CCL 为 M7 级 HDI,独家由 EMC 供应。
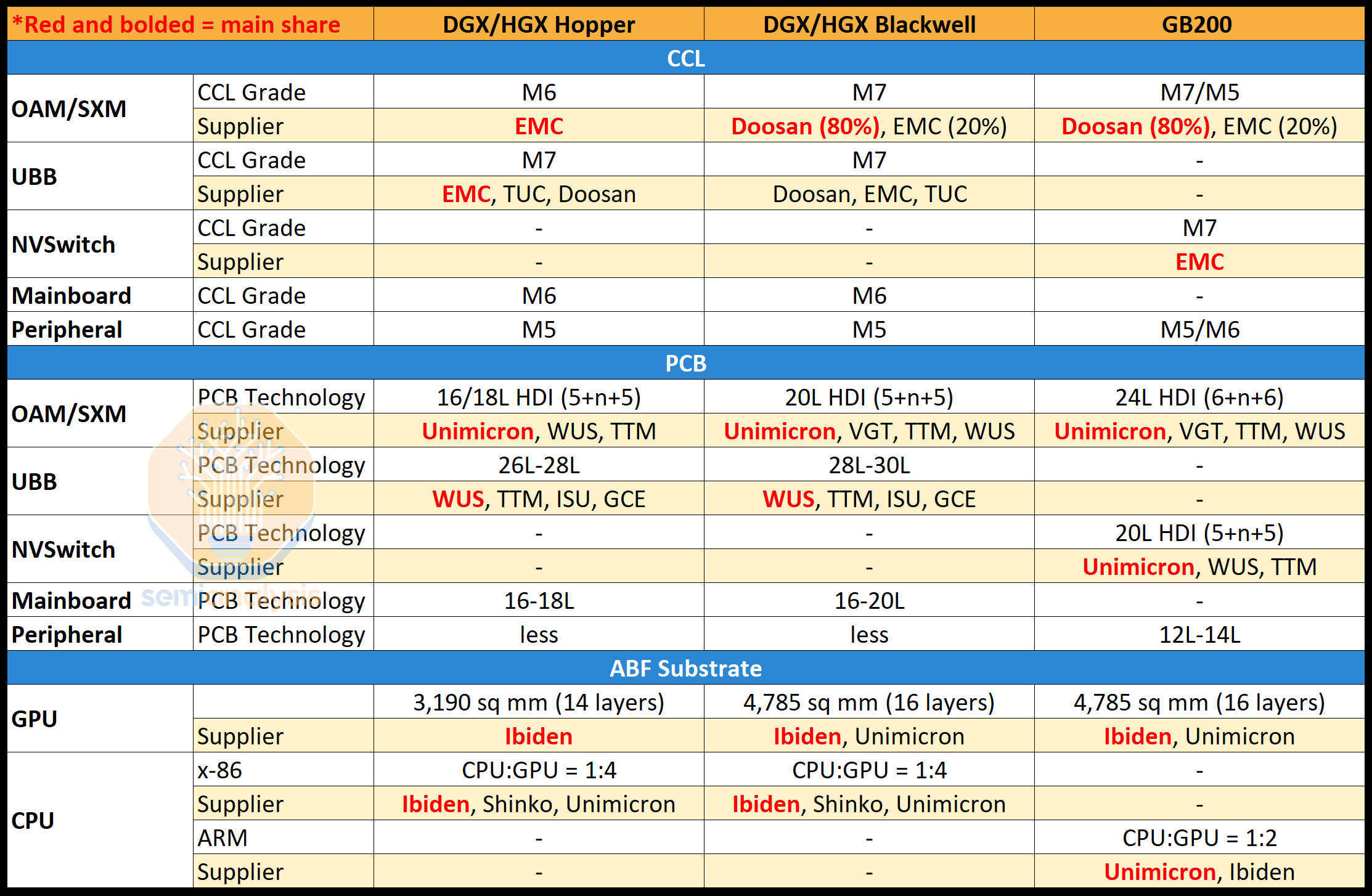
来源:SemiAnalysis GB200 组件与供应链模型
Despite the big win, Doosan does not have enough capacity. We estimate nearly 1.9 million sheets a month are required to meet Nvidia’s demand based on our house view split between GB200 and HGX shipment for Blackwell. EMC has more than double of Doosan’s capacity at 4.3mn sheets/month in 3Q24. EMC planned to expand capacity in 2025 by 1.2mn sheets/month to meet the extra demand that Nvidia has and Doosan cannot fulfill. There will be a consistent trend of requiring higher grade CCL (M7+) and higher layer count PCBs that will drive PCB materials businesses stronger.
尽管获得了重大胜利,斗山的产能仍然不足。根据我们的内部观点,满足 Nvidia 的需求需要每月近 190 万片,分为 GB200 和 HGX 的 Blackwell 出货量。EMC 在 2024 年第三季度的产能超过斗山的两倍,达到 430 万片/月。EMC 计划在 2025 年将产能扩大 120 万片/月,以满足 Nvidia 的额外需求,而斗山无法满足。对更高等级的 CCL(M7+)和更高层数的 PCB 的需求将持续增长,这将推动 PCB 材料业务的强劲发展。
Doosan’s CCL business unit contributed only 4.1% of its revenue in 1Q24, but this will soar. Interestingly, Doosan is not only exposed to the AI theme through its CCL business. Doosan also has a subsidiary – Doosan Enerbility which has meme stock potential given its partnership with NuScale and supplies them with the small modular nuclear reactors which some want to power datacenters with.
斗山的 CCL 业务部门在 2024 年第一季度仅贡献了 4.1%的收入,但这一比例将大幅上升。有趣的是,斗山不仅通过其 CCL 业务暴露于人工智能主题。斗山还有一家子公司——斗山能源能力,由于与 NuScale 的合作,具有潜在的“迷因股”特性,并向其供应小型模块化核反应堆,部分人希望用这些反应堆为数据中心供电。
Glass fiber cloth is a key raw material of CCL. Currently, the glass fiber cloth market (NE grade) required for AI server application is dominated by Japanese suppliers, notably Nitto Boseki and Asahi Kasei. Nitto Boseki has about 60% market share of NE grade glass fiber cloth and is currently supplied constraint. The difference between Nitto Boseki and Asahi Kasei is the glass fiber yarn manufacturing capacity which is the upstream material to make glass fiber cloth. Nitto Boseki has glass fiber yarn capacity which they can use internally and sell externally. Naturally, Nitto Boseki will prioritize the glass fiber yarn supply for themselves. Asahi Kasei, on the other hand, probably needs to source from AGY who supplies the glass fiber yarn.
玻璃纤维布是 CCL 的关键原材料。目前,AI 服务器应用所需的玻璃纤维布(NE 级)市场由日本供应商主导,特别是日东纺织和旭化成。日东纺织在 NE 级玻璃纤维布市场的份额约为 60%,目前供应受到限制。日东纺织与旭化成之间的区别在于玻璃纤维纱的生产能力,玻璃纤维纱是制造玻璃纤维布的上游材料。日东纺织拥有可以内部使用和外部销售的玻璃纤维纱产能。自然,日东纺织会优先考虑自身的玻璃纤维纱供应。另一方面,旭化成可能需要从 AGY 采购玻璃纤维纱。
Keeping It Cool: Liquid Cooling Analysis
保持冷静:液体冷却分析
As thermal design power (TDP) increases from 700W for H100 to 1000W/1,200W for B200/GB200, the second biggest shift from Hopper to Blackwell hardware besides connectivity/networking is the adoption of direct-to-chip liquid cooling (DLC) to increase compute density on the rack level. This translates to an 7-20 times increase in cooling content per GPU compared to DGX H100 depending on the GB200 SKU as well as the split between liquid to air (L2A) and liquid to liquid (L2L) solutions.
随着热设计功率(TDP)从 H100 的 700W 增加到 B200/GB200 的 1000W/1200W,除了连接性/网络之外,从 Hopper 到 Blackwell 硬件的第二大变化是采用直接到芯片的液体冷却(DLC),以提高机架级别的计算密度。这意味着与 DGX H100 相比,每个 GPU 的冷却内容增加了 7-20 倍,具体取决于 GB200 SKU 以及液体到空气(L2A)和液体到液体(L2L)解决方案之间的分配。
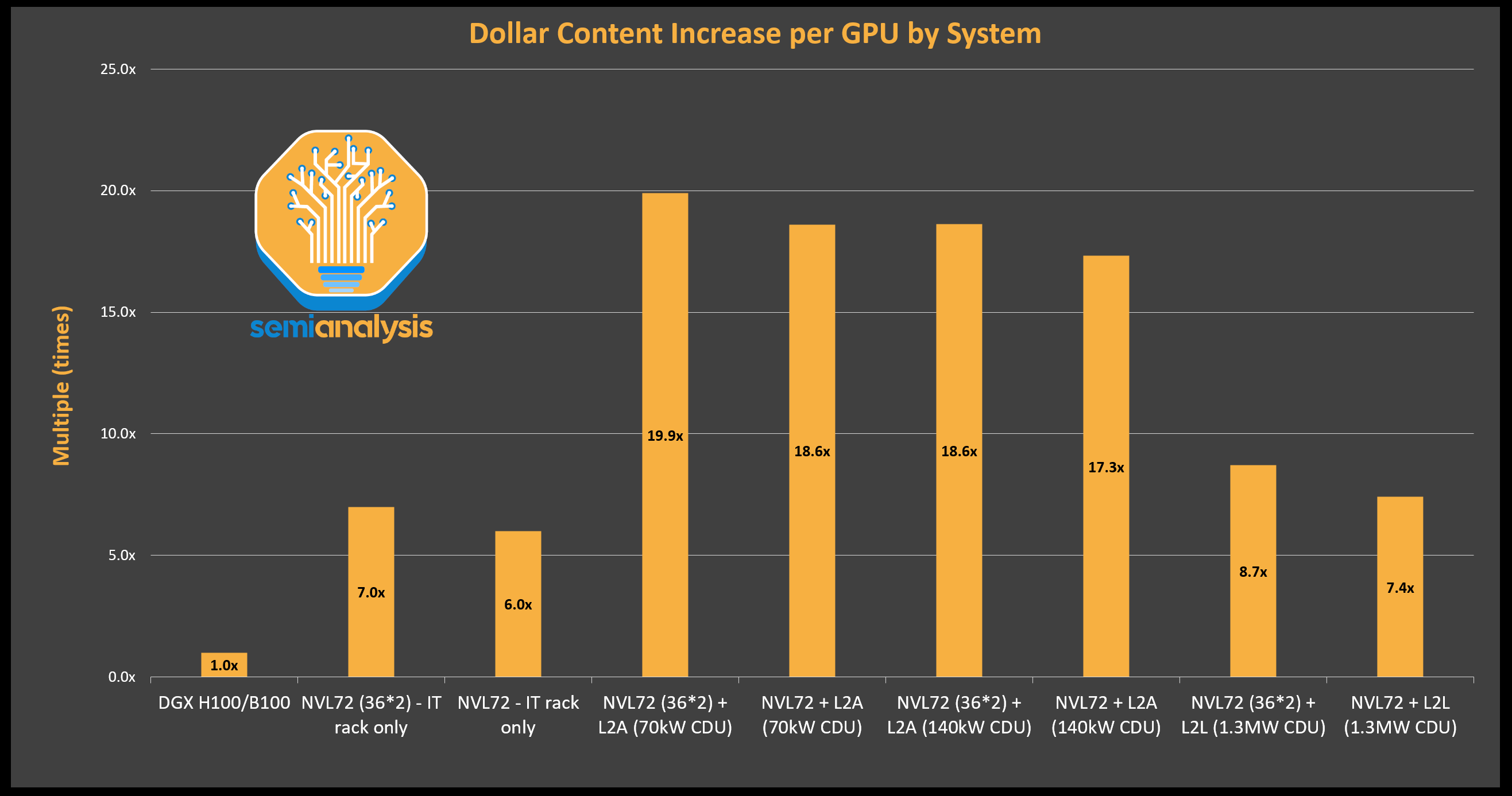
来源:SemiAnalysis GB200 组件与供应链模型
Air cooling is widely adopted for H100 HGX servers using 3DVC (3D vapor chamber) and fans. However, this comes with a sacrifice, at up to 10.2kW TDP per server, sufficient rack space is required to accommodate 4 rack unit tall (1 rack unit = 1.75in) 3DVC to dissipate heat effectively. 8xH100 HGXX servers are generally around 5-8RU tall. Each rack usually has 2-4 H100 HGX nodes, so the TDP for each rack is around 20-40kW.
空气冷却在使用 3DVC(3D 蒸汽腔)和风扇的 H100 HGX 服务器中被广泛采用。然而,这需要牺牲,每台服务器的 TDP 高达 10.2kW,需要足够的机架空间来容纳 4U 高(1U = 1.75 英寸)的 3DVC 以有效散热。8 台 H100 HGXX 服务器通常高约 5-8RU。每个机架通常有 2-4 个 H100 HGX 节点,因此每个机架的 TDP 约为 20-40kW。
For Blackwell, the B100’s and B200’s TDP are at 700W and 1000W/1200W respectively, which requires even taller 3DVC or cold plates for direct liquid cooling (DLC). With the 2700W GB200 Bianca board, DLC is the only option. The chassis height per compute tray to drop to 1-2 RU for GB200, compared to the 9-10RU chassis height of an air-cooled B200 HGX server.
对于 Blackwell,B100 和 B200 的 TDP 分别为 700W 和 1000W/1200W,这需要更高的 3DVC 或冷板以实现直接液体冷却(DLC)。对于 2700W 的 GB200 Bianca 板,DLC 是唯一的选择。与气冷 B200 HGX 服务器的 9-10RU 机箱高度相比,GB200 的每个计算托盘的机箱高度降至 1-2RU。
Besides the increase compute density, another motivation to adopt DLC is the gain on energy efficiency as total data center power lowers by more than 10.2% for DLC L2L solution. In this section we will talk about the implication of this architectural shift of cooling solution on DLC hardware supply chain, data center architecture, different DLC form factors, and CSP/end customers procurement dynamic.
除了计算密度的增加,采用 DLC 的另一个动机是能效的提升,因为 DLC L2L 解决方案使数据中心的总功耗降低了超过 10.2%。在本节中,我们将讨论这种冷却解决方案架构转变对 DLC 硬件供应链、数据中心架构、不同 DLC 形态以及 CSP/最终客户采购动态的影响。
Redesigning Rack Architecture for DLC
重新设计 DLC 的机架架构
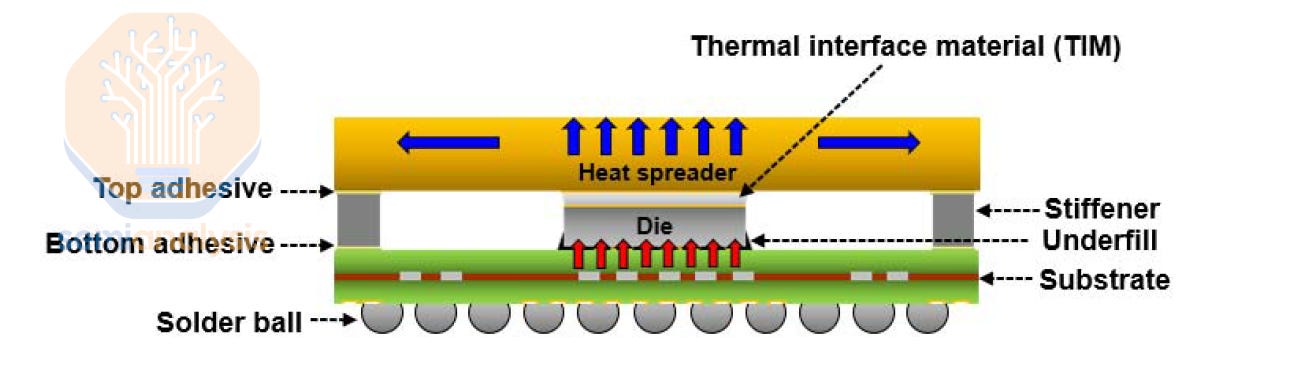
DLC requires more components than air cooling to deploy. While air cooling solution hardware consists of Thermal Interface Material (TIM), Integrated Heat Spreader (IHS) (100% supplied by Jentech), 3DVC, and fans. liquid cooling solutions replace the 3DVC and the fans with these following components:
DLC 需要比空气冷却更多的组件来部署。空气冷却解决方案的硬件包括热界面材料(TIM)、集成散热器(IHS)(100%由 Jentech 提供)、3DVC 和风扇。液体冷却解决方案用以下组件替代 3DVC 和风扇:
Cold Plate - dissipates and spreads heat within a copper plate and transfers heat through a liquid loop.
冷板 - 在铜板内散发和传播热量,并通过液体循环转移热量。Quick Disconnects (QD) - allow the connection and disconnection of fluid lines in a fast and convenient way, without loss of fluids.
快速断开装置(QD) - 允许以快速便捷的方式连接和断开流体管线,而不会造成流体损失。Coolant Distribution Manifolds (CDM) - supplies cold coolant to each server and returns warm coolant back to the CDU.
冷却剂分配管道(CDM)- 向每台服务器供应冷却剂,并将温暖的冷却剂返回至冷却设备(CDU)。Liquid to Air Coolant Distribution Units (L2A CDU), also known as sidecar, which includes:
液体到空气冷却分配单元(L2A CDU),也称为侧车,包括:Reservoir and Pump Unit (RPU), which includes:
储水池和泵单元(RPU),包括:Pump – pushes and circulates the coolant throughout the liquid cooling system (2N design for redundancy).
泵 – 在液体冷却系统中推动和循环冷却液(2N 设计以实现冗余)。Water Tank (Reservoir) - facilitates easy filling and expansion to avoid pressure build up and helps in removing air bubbles.
水箱(储水池)- 便于轻松加水和扩展,以避免压力积聚,并有助于去除气泡。
Radiators - releases the heat absorbed into the air
散热器 - 将吸收的热量释放到空气中Fans – blow the air away form the radiator
风扇 - 将空气从散热器吹走
Liquid to Liquid Coolant Distribution Units (L2L CDU), which includes:
液体到液体冷却剂分配单元(L2L CDU),包括:RPU
Brazed Plate Heat Exchanger (BPHE) - creates flowing channels between plates, with one fluid in odd number channels and the other in the even number channels, thus reaching the purpose of heat exchanging.
钎焊板式热交换器(BPHE) - 在板之间形成流动通道,奇数通道中流动一种流体,偶数通道中流动另一种流体,从而实现热交换的目的。
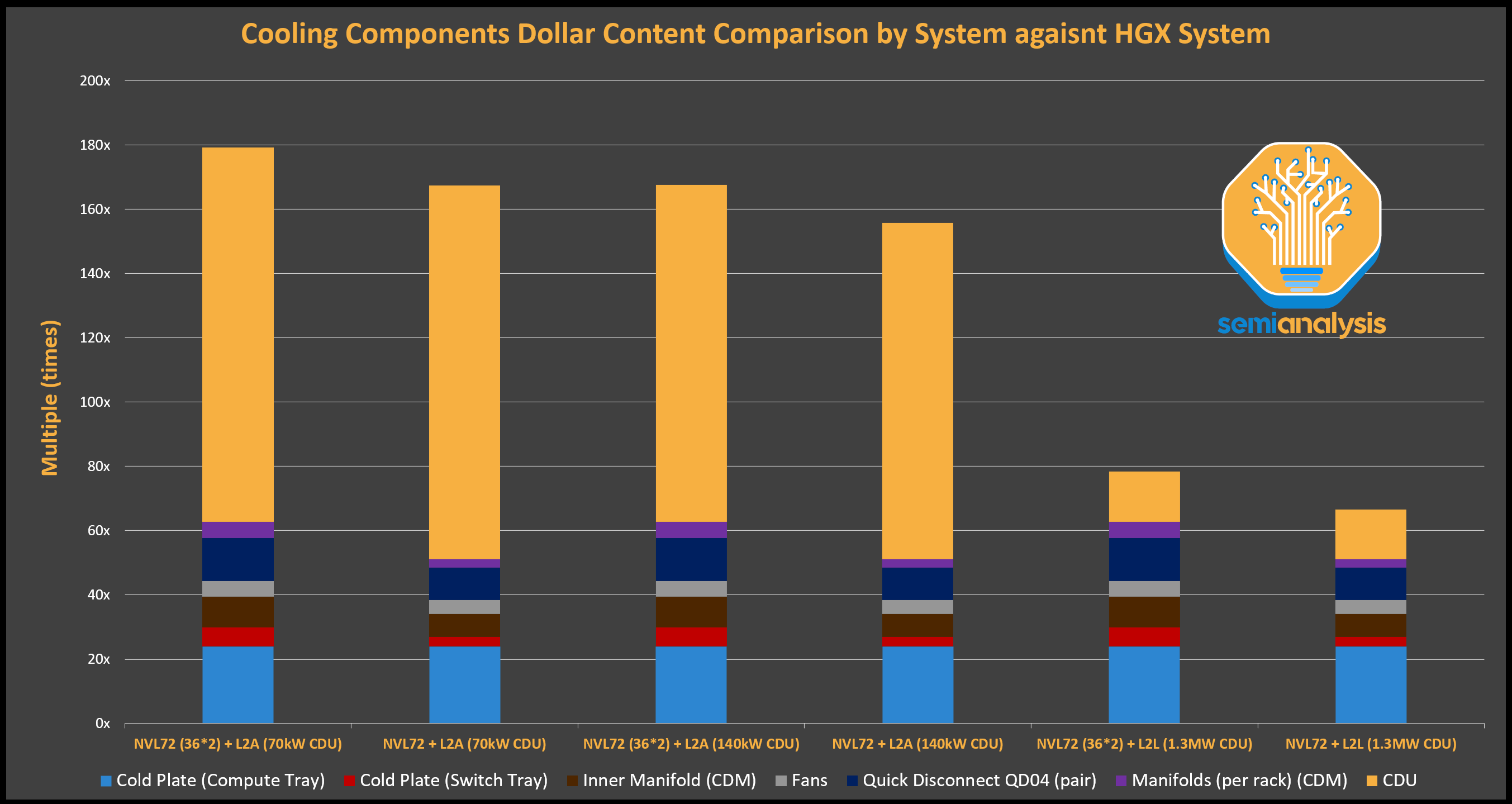
来源:SemiAnalysis GB200 组件与供应链模型
We estimated the liquid cooling components dollar content by the NVL72 and the NVL72 (36*2) system and by different CDU form factor. The graph shows that adopting L2L CDU is much more economical than adopting L2A form factor, given the much higher price per W ratio for L2A CDU.
我们通过 NVL72 和 NVL72 (36*2)系统以及不同的 CDU 形状因素估算了液冷组件的美元含量。图表显示,采用 L2L CDU 比采用 L2A 形状因素更具经济性,因为 L2A CDU 的每瓦特价格比率要高得多。
Heat Transfer Flow from the Chip
芯片的热传导流动
For air cooling: Heat from the chip is conducted through the TIM (thermal interface material) to be evenly distributed among the area of the heat spreader.
对于空气冷却:芯片产生的热量通过热界面材料(TIM)传导,均匀分布在散热器的表面。
Then, the heat goes to the 3DVC, where the heat enters the vapor chamber and travels up the heat pipe into the heat sink. Then, air flow from the fan carries the heat away from the heat sink away from the chassis.
然后,热量进入 3DVC,热量进入蒸汽室并沿着热管上升到散热器。然后,风扇的气流将热量从散热器带走,远离机箱。
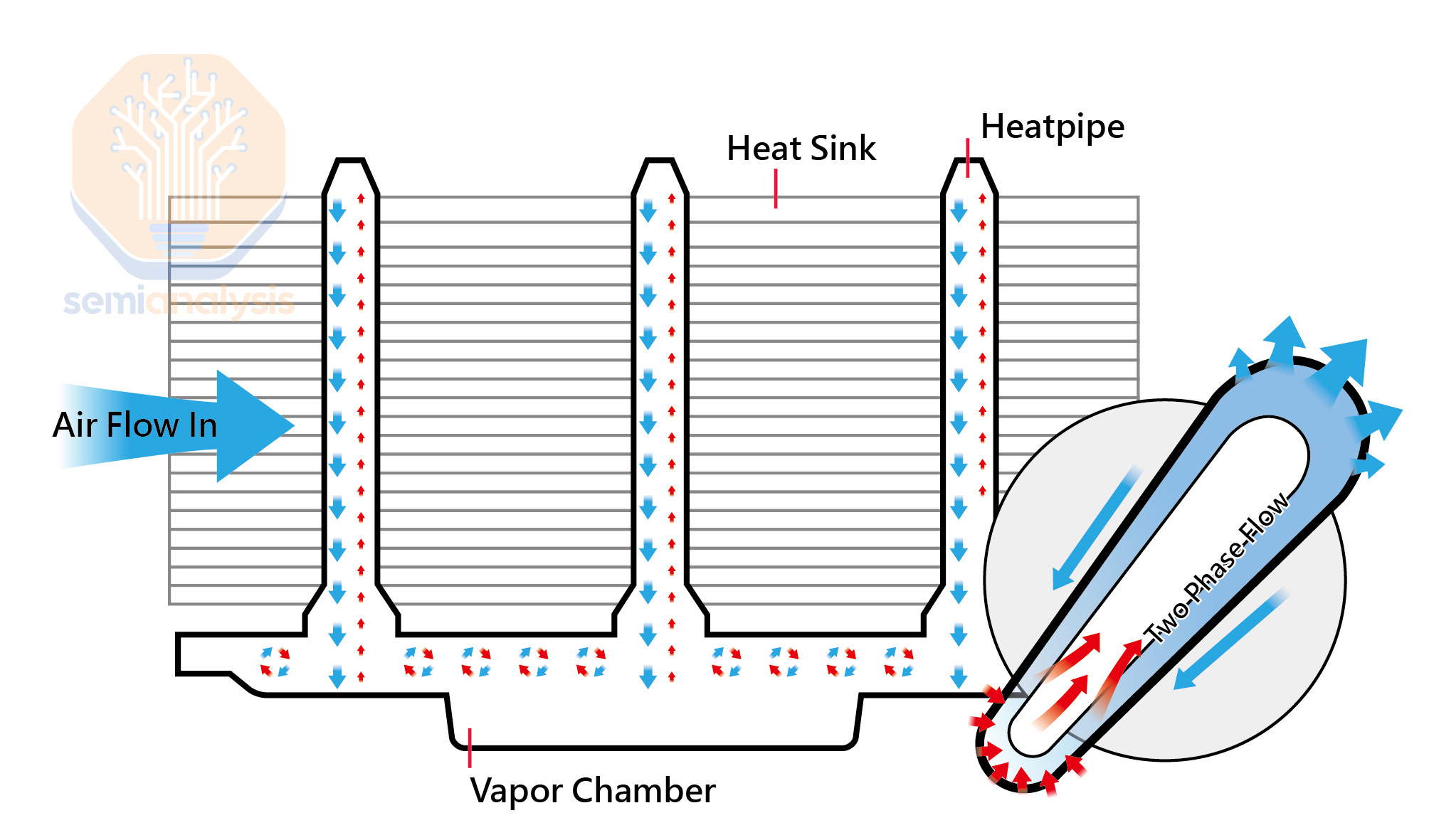
For DLC solution: the heat transfer from IHS to the cold plate and the coolant inside the coldplate absorbs the heat and carries it away to the cooling distribution manifold (CDM). Then, the CDM collects all the coolant from each tray and it goes to the CDU where the coolant exchanges heat with the surrounding air/water through the radiator/BPHE depending on whether it is L2L or L2A. The cooled coolant returns to the CDM, where the coolant is distributed back to each tray. Finally, the coolant enters the cold plate again repeating the process.
对于 DLC 解决方案:热量从 IHS 传递到冷板,冷板内部的冷却液吸收热量并将其带走到冷却分配歧管(CDM)。然后,CDM 收集来自每个托盘的所有冷却液,并送往 CDU,在那里冷却液通过散热器/BPHE 与周围的空气/水进行热交换,具体取决于是 L2L 还是 L2A。冷却后的冷却液返回 CDM,冷却液被分配回每个托盘。最后,冷却液再次进入冷板,重复该过程。
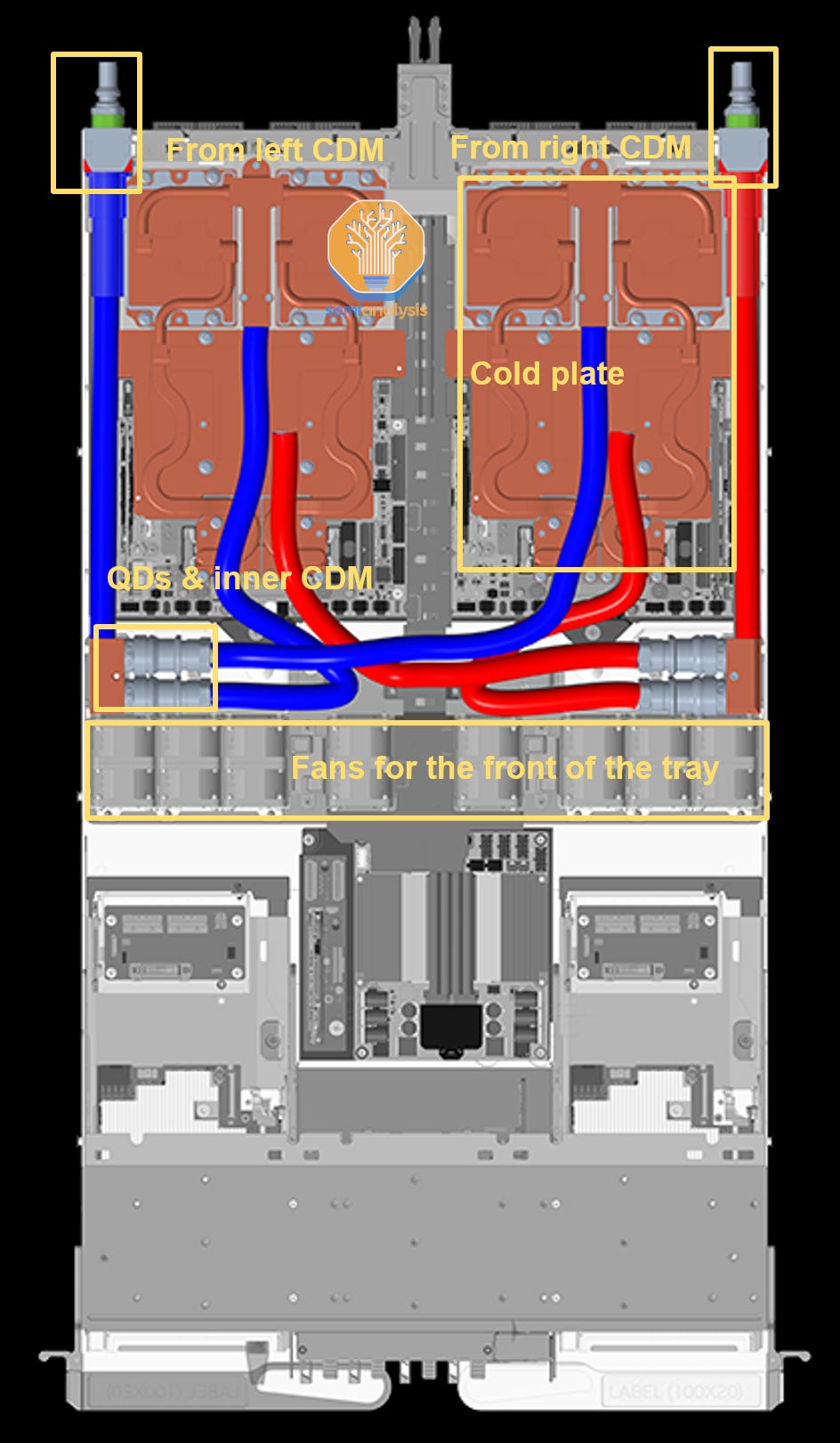
Despite the Bianca board, including two B200 GPUs, one Grace CPU, and two Connect-X NICs, will be liquid cooled, the front half of the GB200 compute tray and NVSwitch tray, where the custom NICs/DPU, PDU, and the management board sit, are air-cooled. Hence, the compute tray will be ~85% liquid cooled and ~15% air-cooled.
尽管 Bianca 板包括两个 B200 GPU、一个 Grace CPU 和两个 Connect-X NIC 将采用液冷,但 GB200 计算托盘和 NVSwitch 托盘的前半部分,定制的 NIC/DPU、PDU 和管理板所在的位置则采用风冷。因此,计算托盘将约 85%采用液冷,约 15%采用风冷。
来源:华硕,SemiAnalysis
Moreover, there will be a separate version of the cold plate for the Bianca board to support hyperscale custom NICs for backend networking as mentioned earlier. This is because custom NICs replaces the Connect-X NIC and move them to the front of the tray away from the Bianca board.
此外,将为比安卡板提供一个单独版本的冷板,以支持如前所述的超大规模定制 NIC 用于后端网络。这是因为定制 NIC 替代了 Connect-X NIC,并将其移至托盘前部,远离比安卡板。
There has been a rumor floating around that there is a major heating issue on Bianca. This is mostly overblown. The issue is much smaller than described, and the solution has already been found.
关于比安卡存在重大加热问题的传闻已经流传开来。这主要是被夸大了。问题远比描述的要小,解决方案已经找到。
Liquid Cooling Form Factors: L2A vs L2L
液体冷却形态:L2A 与 L2L
There are 3 main liquid cooling form factors:
有三种主要的液体冷却形式:
DLC liquid to air (L2A)
DLC 液体到空气 (L2A)DLC liquid to liquid (L2L)
DLC 液体对液体 (L2L)Immersion Cooling 浸没冷却
The two DLC form factors will be ubiquitous for GB200 deployment. While immersion cooling technology exists, it is not mature enough for mass deployment, and lacks serviceability. Nvidia only recognizes air cooling and DLC as the approved cooling technologies, meaning customers don’t get warranty from Nvidia with immersion cooling. As for now, we have only heard about a few non-GB200 immersion cooling projects in progress in Taiwan, Singapore, and the Middle East (Omniva). These immersion cooling projects must use lower performance / TCO versions of Blackwell.
这两种 DLC 形态将在 GB200 部署中无处不在。虽然浸没冷却技术存在,但尚不够成熟以进行大规模部署,并且缺乏可维护性。Nvidia 仅认可空气冷却和 DLC 作为批准的冷却技术,这意味着客户在使用浸没冷却时无法获得 Nvidia 的保修。目前,我们只听说在台湾、新加坡和中东(Omniva)有几个非 GB200 的浸没冷却项目正在进行。这些浸没冷却项目必须使用性能较低/总拥有成本版本的 Blackwell。
The architecture of the rack between L2A and L2L form factors are mostly similar. As explained before, each IT rack for both L2A and L2L includes cold plates, CDMs, and QDs. The cooling rack/ in-rack CDU is where L2A differs from L2L. In other words, L2A utilizes air as the medium to reject heat from the technology cooling system (TCS), while L2L utilizes facility water as the medium to reject heat from the TCS. TCS represents the cooling system between the IT equipment and the CDU.
L2A 和 L2L 形态之间的机架架构大致相似。如前所述,L2A 和 L2L 的每个 IT 机架都包括冷板、CDM 和 QD。冷却机架/机架内 CDU 是 L2A 与 L2L 的不同之处。换句话说,L2A 利用空气作为介质从技术冷却系统(TCS)中排放热量,而 L2L 则利用设施水作为介质从 TCS 中排放热量。TCS 代表 IT 设备与 CDU 之间的冷却系统。
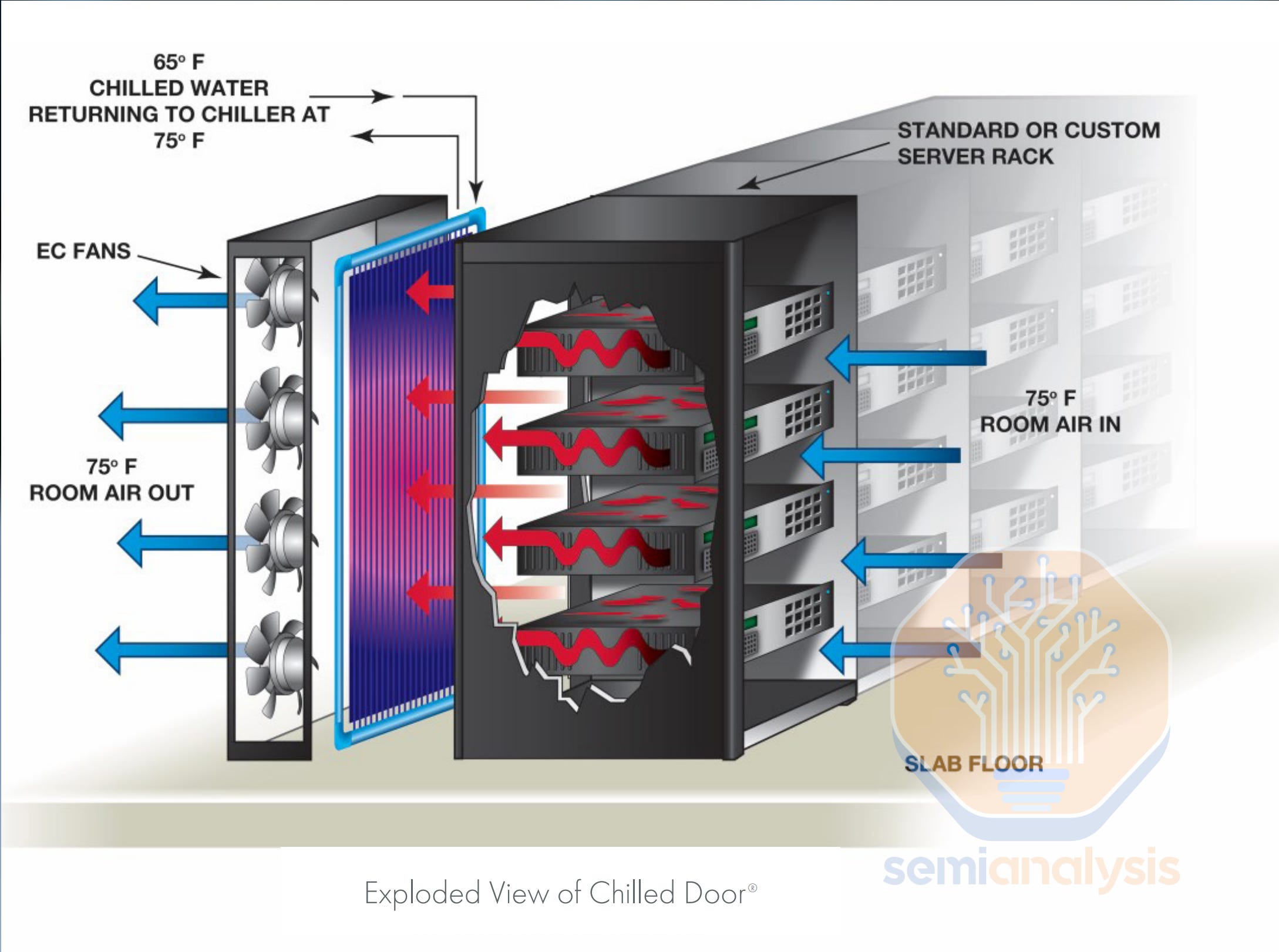
L2A has two form factors. The first L2A form factor is the “Rear Door Heat Exchanger” (RDHx), which is an in-rack solution. The second L2A form factor involves a cooling rack, also known as the sidecar.
L2A 有两种形式因素。第一种 L2A 形式因素是“后门热交换器”(RDHx),这是一种机架内解决方案。第二种 L2A 形式因素涉及一个冷却机架,也称为侧车。
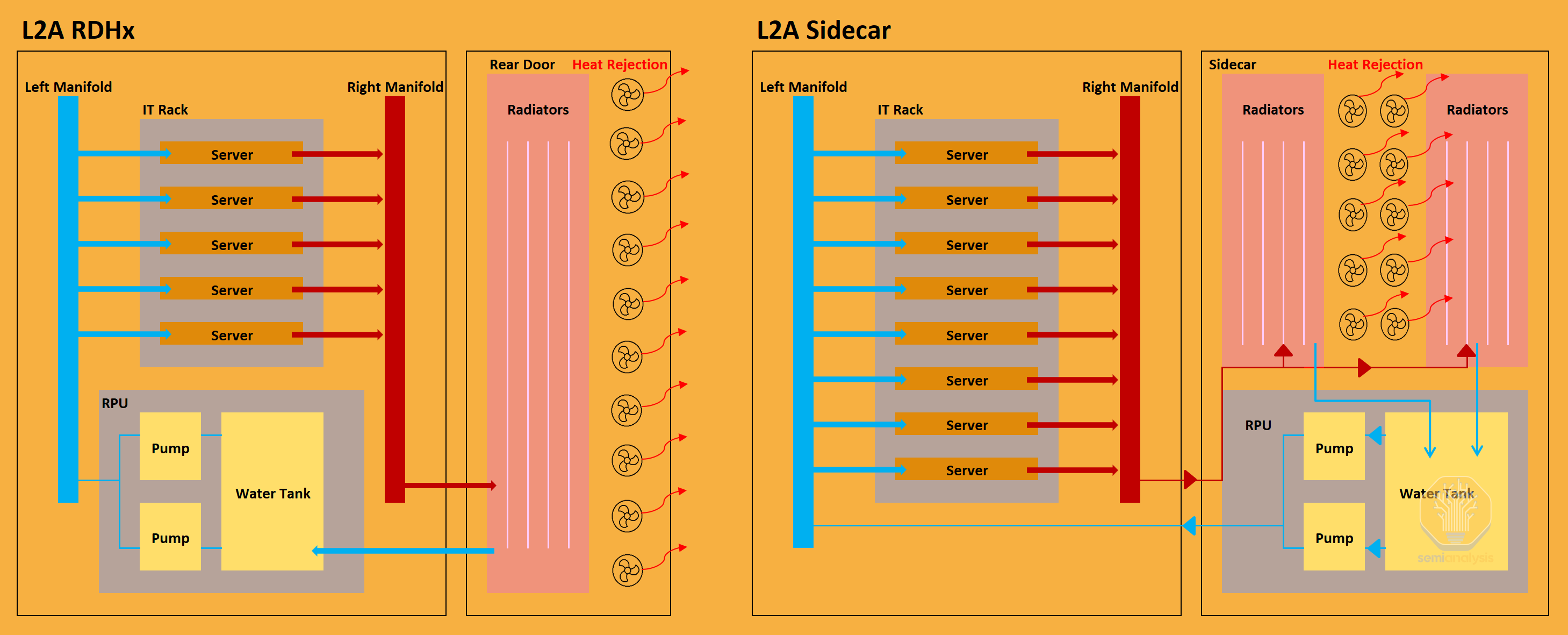
In both L2A systems, hot coolant passes through the radiator (heat exchanger), the heat dissipates into the ambient air and gets blown away by the fans, cooling down the coolant. The cooled coolant enters the reservoir and pump units (RPU) and goes back to the cold plate.
在两个 L2A 系统中,热冷却液通过散热器(热交换器),热量散发到周围空气中,并被风扇吹走,从而冷却冷却液。冷却后的冷却液进入储液罐和泵单元(RPU),然后返回冷板。
RDHx solution has the fans and the radiators attached to the back and the RPU placed at the bottom of the IT rack, while the sidecar solution has these components in a separate cooling rack. Essentially, the side car allows for more radiator space compared to the back of a rack. This reflects the difference between each cooling capacity. RDHx’s cooling capacity is around 30kW-40kw, while Sidecar CDU’s cooling capacity ranges from 70kW to 140kW. We don’t see many uses cases for RDHx as its cooling capacity is way too low to even handle the TDP of one NVL36 rack (66kw). On the other hand, sidecars are designed with capacity at 70kW and 140kW to solve for one NVL36 rack (66kW) and one NVL72 rack (120kW) respectively.
RDHx 解决方案将风扇和散热器安装在后面,而 RPU 放置在 IT 机架的底部,而侧车解决方案则将这些组件放在一个单独的冷却机架中。实际上,侧车相比机架后部提供了更多的散热器空间。这反映了每种冷却能力之间的差异。RDHx 的冷却能力约为 30kW-40kW,而侧车 CDU 的冷却能力范围为 70kW 到 140kW。我们没有看到 RDHx 的许多使用案例,因为其冷却能力远低于一个 NVL36 机架的 TDP(66kW)。另一方面,侧车的设计容量为 70kW 和 140kW,分别用于解决一个 NVL36 机架(66kW)和一个 NVL72 机架(120kW)。
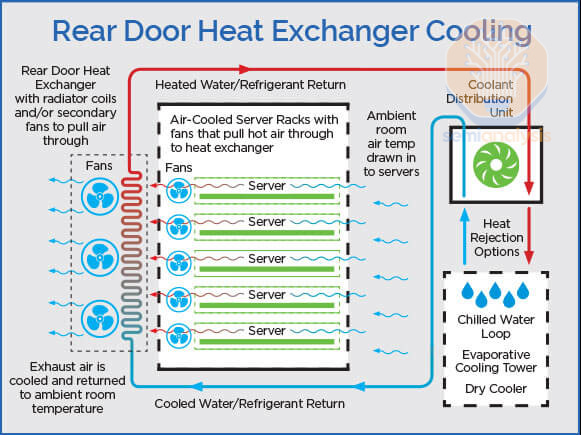
Speaking of rear door heat exchanger (RDHx) liquid cooling solution, some may be confused with another form of air cooling oriented RDHx. From our check, half of the H100 100K cluster shipped to X.ai from Dell adopt this air-cooling enabled RDHx technology, which Elon claimed to be liquid cooling. In fact, Dell shipped what is known as the air to liquid (A2L) RDHx solution. Within the computer tray, it works the same as normal air cooling with 3DVC and fans.
谈到后门热交换器(RDHx)液体冷却解决方案,有些人可能会与另一种以空气冷却为导向的 RDHx 混淆。根据我们的检查,德尔公司向 X.ai 发运的 H100 100K 集群中有一半采用了这种支持空气冷却的 RDHx 技术,而埃隆声称这是液体冷却。实际上,德尔公司发运的是被称为空气到液体(A2L)RDHx 解决方案。在计算机托盘内,它的工作原理与普通空气冷却相同,使用 3DVC 和风扇。
Then, the heat is pulled through the chassis arriving at the heat exchanger (radiator coils) attached to the rear door. Chilled coolant from the CDU gets pumped through the heat exchanger and exchange heat with the hot air. Finally, the warm coolant carries part of the heat toward the CDU to reject heat from the TCS. Usually, the A2L RDHx alone does not have enough cooling capacity to handle all the heat. Hence, the rest of the heat will enter the ambience to be processed by datahall’s air conditioning (CRAC).
然后,热量通过底盘被引导到附在后门上的热交换器(散热器线圈)。来自 CDU 的冷却液被泵送通过热交换器,与热空气进行热交换。最后,温暖的冷却液将部分热量带回 CDU,以排放来自 TCS 的热量。通常,单靠 A2L RDHx 的冷却能力不足以处理所有热量。因此,其余的热量将进入环境,由数据中心的空调(CRAC)处理。
For L2L, there are two form factors, which are with in-rack CDU and in-row CDU. Unlike L2A, L2L coolant does not exchange heat through a radiator; instead, coolant enters the brazed plate heat exchanger (BPHE) in the CDU to exchange heat with facility water. After coolant returns to the RPU from the BPHE.
对于 L2L,有两种形式因素,即机架内 CDU 和行内 CDU。与 L2A 不同,L2L 冷却剂不通过散热器交换热量;相反,冷却剂进入 CDU 中的焊接板式换热器(BPHE)与设施水交换热量。冷却剂从 BPHE 返回 RPU 后。
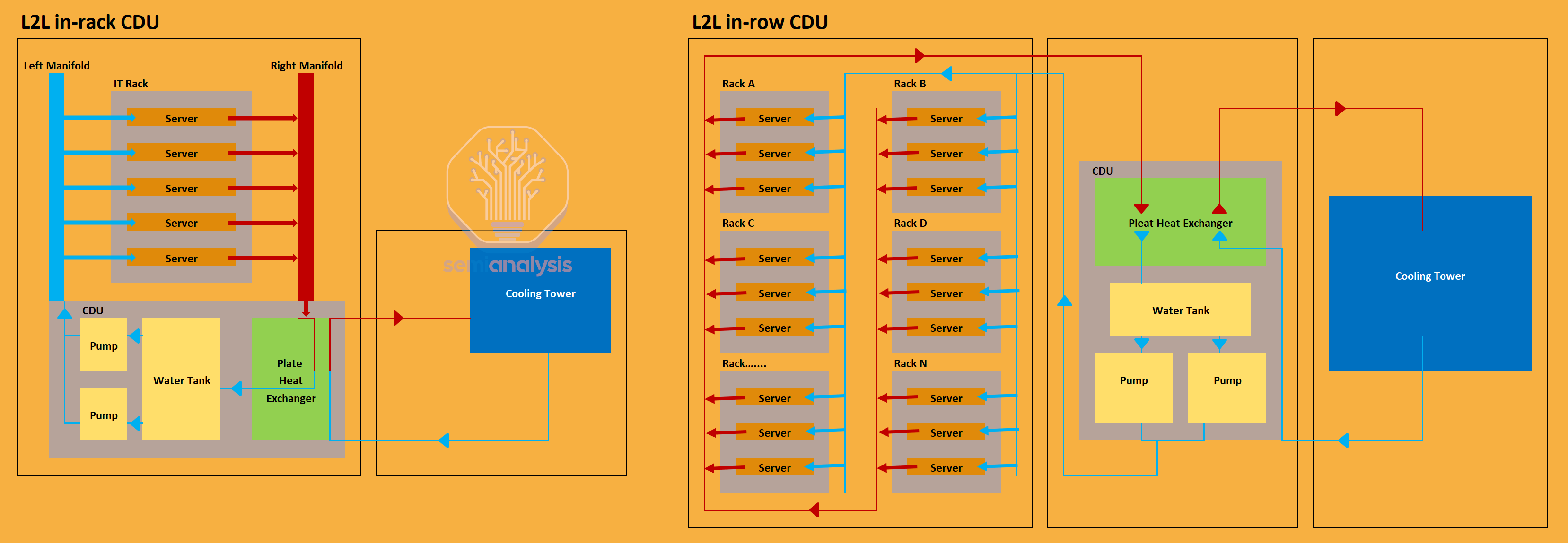
The difference between in-rack and in-row CDU is that in-rack CDU is placed at the bottom of each rack usually taking up ~4RU of rack space, while in-row CDU situates at the end of a rack row. The in-row CDU is connected to all the racks within the row through buried pipelines and has the cooling capacity to reject heat for all the racks. In-rack CDU typically has cooling capacity around 80kW, while in-row CDU has cooling capacity that ranges from 800kW to 2000kW.
在架内冷却单元(CDU)和行内冷却单元(CDU)之间的区别在于,架内 CDU 通常放置在每个机架的底部,占用约 4RU 的机架空间,而行内 CDU 位于机架行的末端。行内 CDU 通过埋藏的管道连接到行内的所有机架,并具有为所有机架排放热量的冷却能力。架内 CDU 的冷却能力通常在 80kW 左右,而行内 CDU 的冷却能力范围从 800kW 到 2000kW。
Redesigning Data Center Infrastructure for DLC
重新设计数据中心基础设施以支持 DLC
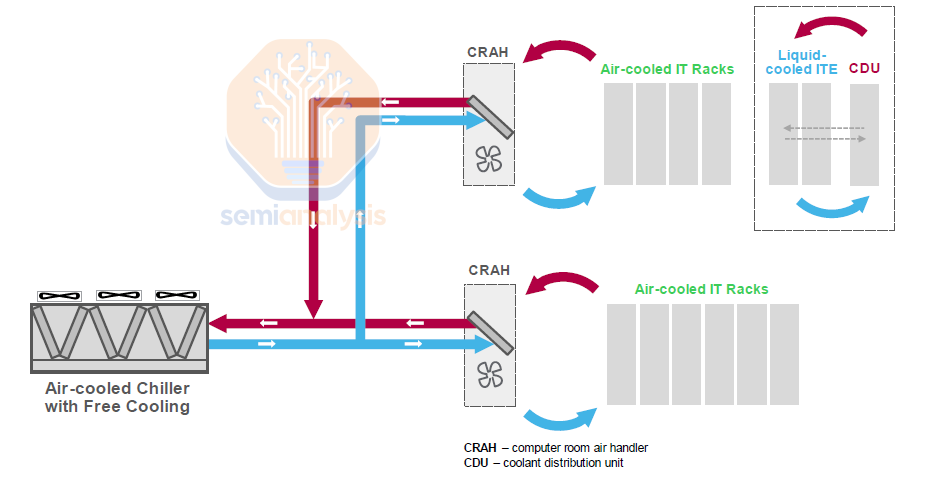
L2A solution does not require redesigning of data center infrastructure, as heat is dumped into the data center air like traditional air-cooling. The traditional data hall air conditioner/handler (CRAC/CRAH) will remove the heat out of the data hall.
L2A 解决方案不需要重新设计数据中心基础设施,因为热量像传统空气冷却一样被排放到数据中心空气中。传统的数据大厅空调/处理器(CRAC/CRAH)将热量从数据大厅中移除。
L2L solution, on the contrary, requires more site installation of piping to connect the server racks to the CDU and the CDU to the facility water system. Keep in mind that CRAC/CRAH are still required for L2L as only 85% of heat is removed by liquid, meaning that 15% of heat will enter the data center air. Total data center power consumption can decrease by more than 10.2% when using liquid cooling compared to 100% air-cooling.
L2L 解决方案,恰恰相反,需要更多的现场管道安装,以将服务器机架连接到 CDU,并将 CDU 连接到设施水系统。请记住,L2L 仍然需要 CRAC/CRAH,因为只有 85%的热量通过液体去除,这意味着 15%的热量将进入数据中心空气。与 100%空气冷却相比,使用液体冷却时,数据中心的总电力消耗可以减少超过 10.2%。
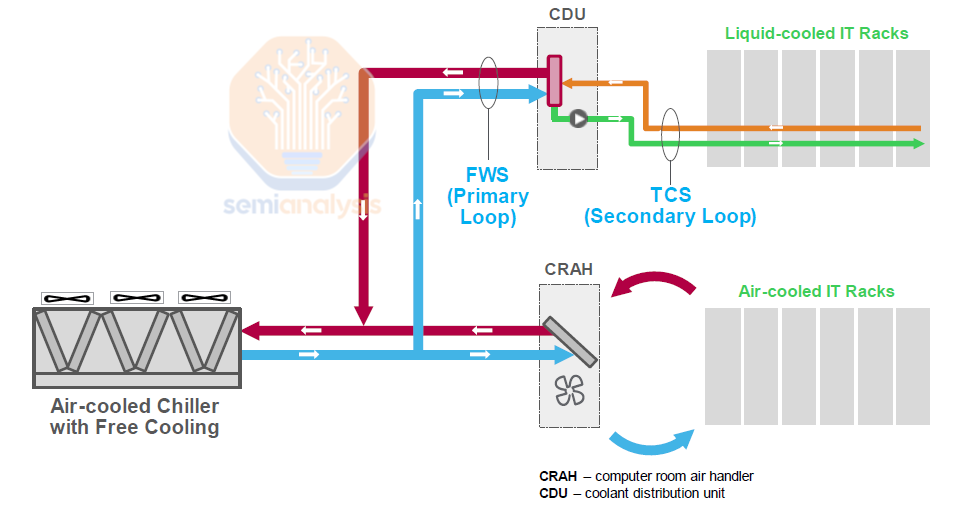
Moreover, total usage effectiveness (TUE), a more insightful energy efficiency comparative metric between liquid and air cooling, decreases by more than 15%. The TUE for air cooling should be around 1.4 for hyperscalers (~1.55 for neoclouds), while the TUE drops to 1.15 for DLC L2L. With less fans required compared to air cooling and uninterrupted airflow into the data center air, the TUE for DLC L2A should still less than 1.4 of air cooling, which is much higher than 1.15 of DLC L2L as 100% of the heat must be removed by CRAC/CRAH.
此外,总使用效率(TUE),作为液冷和空气冷却之间更具洞察力的能效比较指标,下降超过 15%。空气冷却的 TUE 应在超大规模数据中心约为 1.4(新云约为 1.55),而 DLC L2L 的 TUE 降至 1.15。与空气冷却相比,DLC L2A 所需的风扇更少,数据中心的气流不间断,因此 DLC L2A 的 TUE 仍应低于空气冷却的 1.4,这远高于 DLC L2L 的 1.15,因为 100%的热量必须由 CRAC/CRAH 移除。
It is obvious that L2L will be the long-term mainstream DLC solution given its energy efficiency and price per W advantage over L2A. However, L2L deployment faces 2 significant delaying factors and bottlenecks now. Firstly, CSPs are prioritizing speed of deployment over TUE gain. Secondly, permitting, which could take time to secure, is required to source water for the facility water system even though the site installation of piping to support L2L is already complete. As a result, the hyperscalers are adopting L2A as the short-term contingency solution to ensure the quick deployment of the GB200 systems. We believe the majority of the GB200 volume will be in L2A form factor before 3Q25.
显然,考虑到其能源效率和每瓦特价格优势,L2L 将成为长期主流的 DLC 解决方案。然而,L2L 的部署目前面临两个显著的延迟因素和瓶颈。首先,CSP 优先考虑部署速度而非 TUE 收益。其次,尽管支持 L2L 的管道现场安装已经完成,但仍需获得许可,这可能需要时间,以便为设施水系统提供水源。因此,超大规模企业正在采用 L2A 作为短期应急解决方案,以确保 GB200 系统的快速部署。我们相信,在 2025 年第三季度之前,绝大多数 GB200 的数量将以 L2A 形式存在。
Liquid Cooling Components Procurement Decision Chain
液冷组件采购决策链
For liquid cooling components supplier, Nvidia only provides reference design partner for the IT rack listed on a reference vendor list (RVL). They do provide recommended vendors for the cooling rack (CDU), but they are not the same as reference design partners.
对于液冷组件供应商,Nvidia 仅为参考供应商列表(RVL)中列出的 IT 机架提供参考设计合作伙伴。他们确实提供了冷却机架(CDU)的推荐供应商,但这些与参考设计合作伙伴并不相同。
Just like many other components, end customers are not obligated to use Nvidia reference design liquid cooling components. Even with their extremely capable R&D teams, some hyperscalers are relatively unfamiliar with liquid cooling supply chain. Therefore, ODMs or system integrators (SI) have more voice to recommend suppliers for liquid cooling components before the hyperscalers become familiar with the supply chain. There are two working models with unfamiliar liquid cooling components for hyperscalers:
就像许多其他组件一样,最终客户并不一定要使用 Nvidia 参考设计的液冷组件。即使拥有极其强大的研发团队,一些超大规模云服务商对液冷供应链仍然相对不熟悉。因此,在超大规模云服务商熟悉供应链之前,ODM 或系统集成商(SI)在推荐液冷组件供应商方面有更大的发言权。对于不熟悉的液冷组件,超大规模云服务商有两种工作模式:
ODM suggests suppliers to hyperscalers for qualification.
ODM 建议供应商向超大规模客户进行资格认证。Hyperscalers authorize ODM to take responsibility and oversee qualification.
超大规模云服务商授权 ODM 负责并监督资格认证。

On the other hand, Tier 2 CSP and Neocloud may not have procurement team and R&D capability as adequate as the hyperscalers do. Especially, Neoclouds will rely on OEM like Supermicro, Dell, Lenovo, and HPE that offer no customization. They have two options:
另一方面,Tier 2 CSP 和 Neocloud 可能没有像超大规模云服务商那样充足的采购团队和研发能力。特别是,Neocloud 将依赖于像 Supermicro、Dell、Lenovo 和 HPE 这样的 OEM,这些 OEM 不提供定制服务。他们有两个选择:
Tier 2 CSP can procure from Nvidia’s reference design partners as they have already been qualified by Nvidia.
二级云服务提供商可以从 Nvidia 的参考设计合作伙伴处采购,因为他们已经获得 Nvidia 的认证。OEMs offer integrated solutions including DLC components that have been qualified and integrated by the OEMs.
OEM 提供集成解决方案,包括已由 OEM 认证和集成的 DLC 组件。
Moreover, the procurement for cooling rack or CDU follows different processes to the IT rack components.
此外,冷却架或 CDU 的采购流程与 IT 机架组件的流程不同。
There are 3 working models for the sidecar (L2A CDU):
侧车(L2A CDU)有三种工作模型:
System integrator assembles + system integrator qualified components.
系统集成商组装 + 系统集成商合格组件。System integrator assembles + end customer qualified components.
系统集成商组装 + 终端客户合格组件。Cooling solution suppliers integrated solution + ensuring sidecar integrates well with the IT rack.
冷却解决方案供应商集成解决方案 + 确保侧车与 IT 机架良好集成。
L2L CDU are delivered fully integrated from supplier:
L2L CDU 完全由供应商集成交付:
Cooling solution provider integrated solution (Vertiv, Motivair, etc.)
冷却解决方案提供商集成解决方案(Vertiv, Motivair 等)OEM integrated solution (Supermicro, etc)
OEM 集成解决方案(超微等)System integrator integrated solution (Ingrasys, etc)
系统集成商集成解决方案(英华达等)
DLC Components Competitive Landscape Analysis
DLC 组件竞争格局分析
As the above analysis of the procurement decision indicates, being on the reference vendor list (RVL) doesn’t translate into orders for suppliers. Unless customers are purchasing DGX system, Nvidia doesn’t dictate on components procurement. Ultimately, the decision on suppliers is made by end customers or OEMs based on their procurement strategies. For example, Tier-1 CSPs aim to procure from 1 or 2 suppliers for each liquid cooling component.
如上述采购决策分析所示,成为参考供应商名单(RVL)上的供应商并不意味着会获得订单。除非客户购买 DGX 系统,否则 Nvidia 不会对组件采购施加影响。最终,供应商的决策由最终客户或 OEM 根据其采购策略做出。例如,一级云服务提供商(CSP)旨在为每个液冷组件从 1 或 2 个供应商处采购。
At COMPUTEX 2024, over 80 liquid cooling suppliers showcased their liquid cooling solutions as well as production capacity. 5 of us from SemiAnalysis were there and had conversations with every firm.
在 2024 年台北电脑展上,超过 80 家液冷供应商展示了他们的液冷解决方案和生产能力。我们 SemiAnalysis 的 5 位成员在场,并与每家公司进行了交谈。
With some simple math on capacity number, this raised an oversupply concerns before the party even got going. From our supply chain checks, many suppliers claim they have capacity, but very few have been listed on the reference vendor list let alone winning any significant orders. On top of this, quality and track record of the supplier is considered the most important determinant in the procurement decision chain. Hence, each component has varying competitive landscape and qualification entry barrier depending on different level of reliability requirements and customers procurement strategies.
通过对产能数字进行简单的数学计算,这在派对开始之前就引发了过剩供应的担忧。根据我们的供应链检查,许多供应商声称他们有产能,但很少有被列入参考供应商名单,更不用说赢得任何重要订单。此外,供应商的质量和业绩记录被认为是采购决策链中最重要的决定因素。因此,每个组件的竞争格局和资格准入门槛因不同的可靠性要求和客户的采购策略而有所不同。
Among the liquid cooling components, cold plate and QDs are where most of the leakage happens, so the hyperscalers are more likely to adopt solution from suppliers on the RVL. As end customers value quality and wish to avoid system failure over prices for components which are an insignificant percentage of GB200 BOM. We believe there will be less competition and pricing pressure on these components. In other words, there are very little incentives for end customers to replace incumbent suppliers at the risk of leakage. The supplier landscape of cold plate will be similar to that of 3DVC, but with some expansion: AVC, Cooler Masters, Delta, and Auras.
在液冷组件中,冷板和 QD 是泄漏发生最多的地方,因此超大规模数据中心更可能采用 RVL 供应商的解决方案。由于最终客户重视质量,并希望避免系统故障,而不是关注占 GB200 BOM 微不足道比例的组件价格。我们认为这些组件的竞争和价格压力会较小。换句话说,最终客户几乎没有动力在泄漏风险下更换现有供应商。冷板的供应商格局将与 3DVC 相似,但会有所扩展:AVC、Cooler Masters、Delta 和 Auras。
Suppliers of QD are mostly US/Europe based and the referenced vendors are currently CPC, Parker Hannifin, Danfoss, and Staubli. CPC had purposed built a factory with a clean room for the liquid cooling QDs. Besides the clean room requirement, the QDs have several mechanical IP, including latches and valves to ensure easy access and drip free servicing of the server. At the moment, there is supply tightness of QDs which could become a bottleneck of GB200 shipment.
QD 的供应商主要位于美国/欧洲,参考的供应商目前包括 CPC、帕克汉尼芬、丹佛斯和斯图布利。CPC 已计划建造一座配有洁净室的液冷 QD 工厂。除了洁净室的要求,QD 还具有多个机械知识产权,包括锁扣和阀门,以确保服务器的便捷访问和无滴漏维护。目前,QD 的供应紧张,可能成为 GB200 出货的瓶颈。
CDM and CDU are the components that we believe will be more competitive than the cold plate and the quick disconnects. The most important part of the manufacturing process of the CDM is to solder the QDs onto the manifolds properly to prevent leakage. Soldering the QDs is not a difficult process hence the barrier to enter is low. As for the CDU, the components within a L2L CDU, BPHE, and RPU etc, are not difficult for any given supplier to make. However, we believe more established suppliers who provide complete integration of operation with telemetry/monitoring of the system and competent servicing/maintenance capacity will constitute a significant share of the L2L and L2A CDU market.
CDM 和 CDU 是我们认为将比冷板和快速断开装置更具竞争力的组件。CDM 制造过程最重要的部分是将 QD 正确焊接到歧管上,以防止泄漏。焊接 QD 并不是一个困难的过程,因此进入门槛较低。至于 CDU,L2L CDU、BPHE 和 RPU 等内部组件对于任何供应商来说都不难制造。然而,我们认为,提供与系统遥测/监控和有能力的服务/维护能力的完整操作集成的更成熟的供应商将占据 L2L 和 L2A CDU 市场的显著份额。
Power Delivery Network 电力传输网络
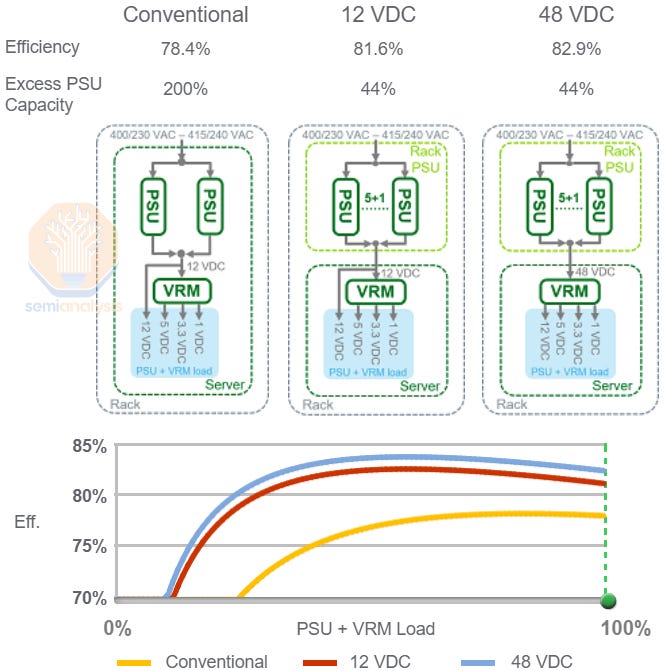
As TDP per rack increases from 40kW for H100 4 nodes rack to 120kW GB200 NVL72 rack, power delivery network is centralized on the rack level. Conventionally, high voltage AC is stepped down and converted to 12VDC at node level power supply unit (PSU). For GB200, voltage step down AC to DC conversion happens at the rack level PSUs. The centralized design of GB200 increases power efficiency by 2% compared to conventional design with best-in-class grade PSU.
随着每个机架的 TDP 从 H100 4 节点机架的 40kW 增加到 GB200 NVL72 机架的 120kW,电力传输网络在机架级别上实现了集中化。传统上,高压交流电在节点级电源单元(PSU)处被降压并转换为 12V 直流电。对于 GB200,交流电到直流电的降压转换发生在机架级 PSU 处。GB200 的集中设计相比于传统设计,使用最佳级别的 PSU 提高了 2%的电力效率。
The gain in efficiency is due to the reduction in oversizing and redundancy factor (excess PSU capacity) on the rack level PSUs compared to node level PSUs. Then by replacing the 12VDC architecture with the 48VDC architecture sending higher voltage into the compute tray, the efficiency is increased by another percent.
效率的提升是由于机架级电源单元(PSU)相比节点级电源单元(PSU)在过度配置和冗余因素(多余的电源容量)上的减少。然后通过用 48VDC 架构替代 12VDC 架构,将更高的电压送入计算托盘,效率又提高了一个百分点。

This is because of the shorter trace length leading to lower resistance loss as discussed in the negative Vicor pieces before. Note after we were negative, the stock fell to more than 50% in just a few months.
这是因为较短的走线长度导致较低的阻抗损失,正如之前在负面 Vicor 文章中讨论的那样。请注意,在我们持负面观点后,股票在短短几个月内下跌了超过 50%。

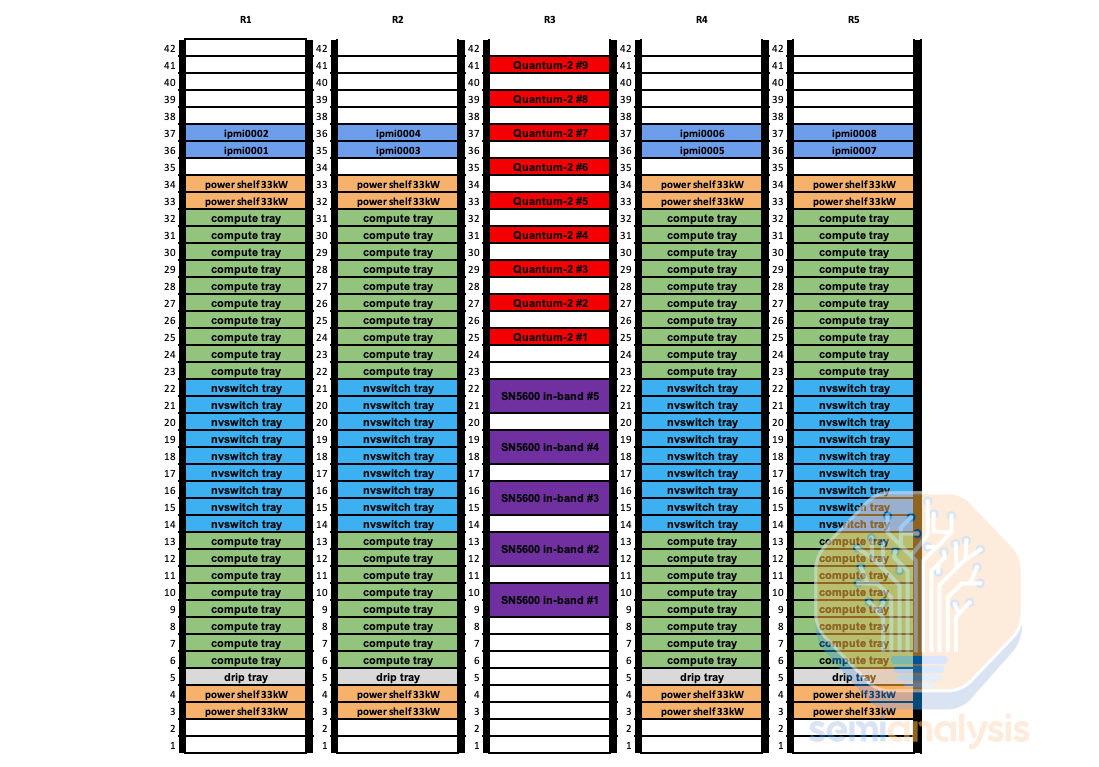
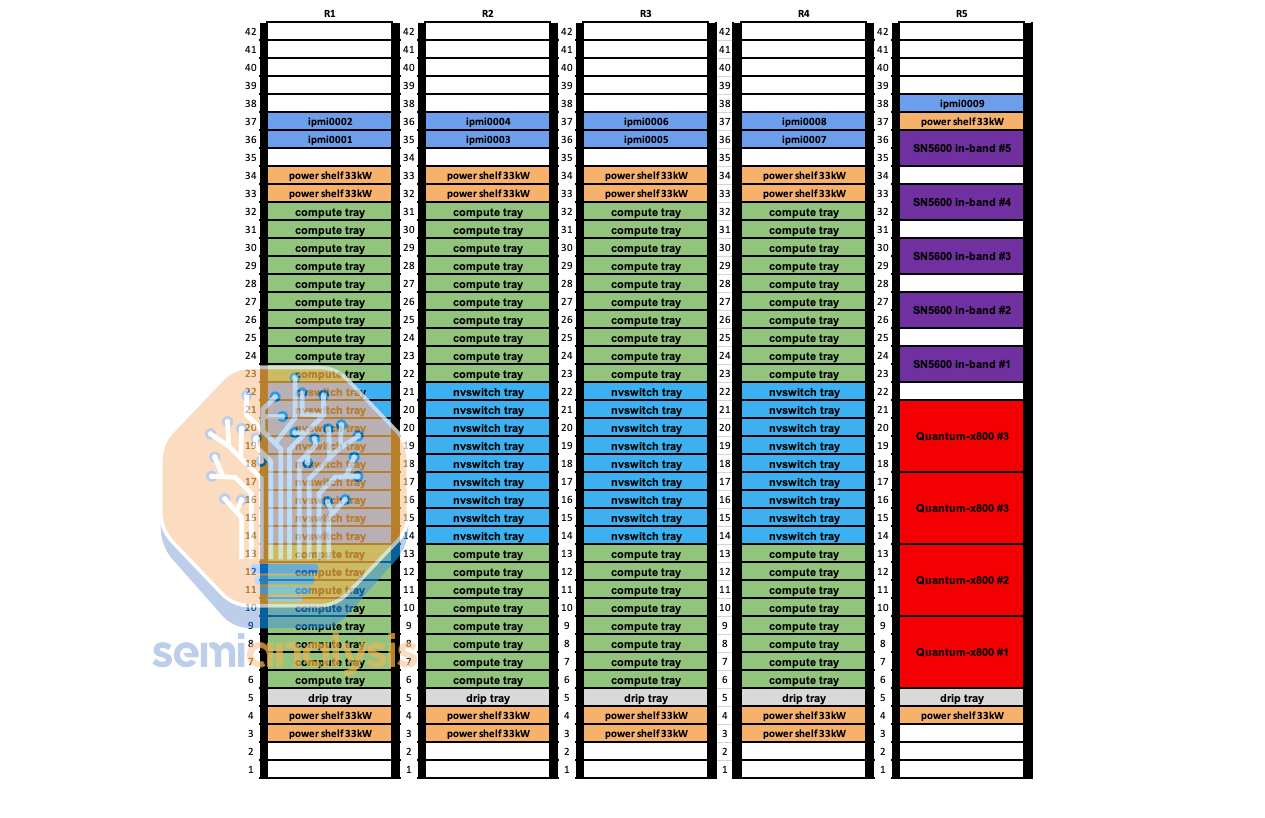
Power shelves are symmetrically placed at the top and the bottom of the rack for GB200 rack.
电源架对称地放置在 GB200 机架的顶部和底部。

来源:伊顿,半导体分析
Each power shelf consists of 6 PSUs of 5.5kW, which equals to 33kW per power shelf. The power shelf accepts 346-480V AC from the power whip and outputs 48/50V DC, with a maximum current of 600A per power shelf.
每个电源架由 6 个 5.5kW 的电源单元组成,等于每个电源架 33kW。电源架接受来自电源线的 346-480V 交流电,并输出 48/50V 直流电,每个电源架的最大电流为 600A。

GB200 NVL36 rack will have 2 power shelves per rack supplying 66kW of power, and NVL72 will have 4 power shelves supplying 132kW of power.
GB200 NVL36 机架将每个机架配备 2 个电源架,提供 66kW 的电力,而 NVL72 将配备 4 个电源架,提供 132kW 的电力。

Each power shelves will send power to the busbar at the rear of the rack running at 1200A. Power will enter the tray from the busbar bar connector at the back of the server tray, then it the cable will bring 48V DC to the power distribution board (PDB). The PDB will step down the DC to 12V and send it too all the board in the compute tray. The Bianca board receives power from the yellow 12V power connector placed at the edges. The fan receives power from the Bianca board through the 8 pin Molex fan connectors.
每个电源架将以 1200A 的电流向机架后面的母线供电。电源将通过服务器托盘后面的母线连接器进入托盘,然后电缆将 48V 直流电送到配电板(PDB)。PDB 将直流电降压至 12V,并将其发送到计算托盘中的所有电路板。Bianca 电路板通过放置在边缘的黄色 12V 电源连接器接收电源。风扇通过 8 针 Molex 风扇连接器从 Bianca 电路板接收电源。
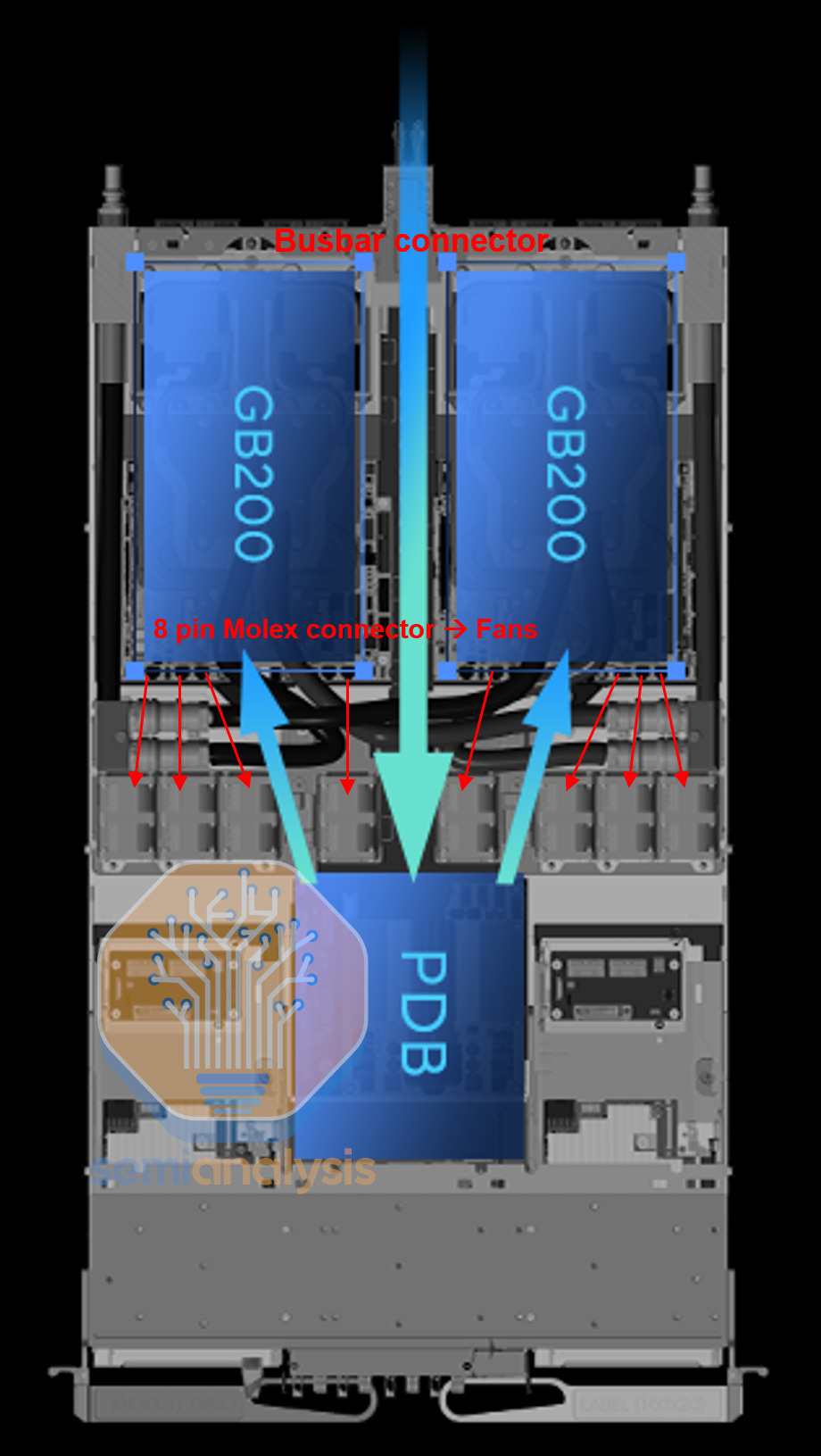
来源:华硕,SemiAnalysis
The supply chain for PDB and VRM on Bianca is quite diverse with even low quality companies such as Alpha Omega getting share on the PDB. The VRM on the Bianca board is much tighter, with the primary share players being Monolithic Power Systems, Renesas, and Infineon. We share more details on price and ASP in the GB200 Component & Supply Chain Model.
比安卡的 PDB 和 VRM 供应链相当多样化,甚至一些低质量公司如 Alpha Omega 也在 PDB 中占有份额。比安卡板上的 VRM 则紧凑得多,主要的市场参与者是单片电源系统、瑞萨和英飞凌。我们在 GB200 组件与供应链模型中分享了更多关于价格和 ASP 的细节。
BMC
Baseboard management controller (BMC) is a specialized processor with logic control features that is used to remotely monitor and manage host systems. BMC can be accessed remotely via dedicated or shared networks and has multiple connections to the host system, allowing it to monitor hardware via sensors, flash BIOS/UEFI, provide host access via serial or physical/virtual KVM Console. It is able to power cycle and record host and log events. The BMC is used in servers and some datacenter equipment such as NIC, power supplier, DPU and so on.
底板管理控制器(BMC)是一种具有逻辑控制功能的专用处理器,用于远程监控和管理主机系统。BMC 可以通过专用或共享网络远程访问,并与主机系统有多个连接,允许通过传感器监控硬件,闪存 BIOS/UEFI,通过串行或物理/虚拟 KVM 控制台提供主机访问。它能够进行电源循环并记录主机和日志事件。BMC 用于服务器和一些数据中心设备,如网络接口卡(NIC)、电源供应器、数据处理单元(DPU)等。
Servers generally have an average of one to two BMCs per general server. For AI servers, the BMC content per server is different based on form factors and SKUs. In this section, we will analyze the BMC content for Nvidia AI servers as well as non-Nvidia AI servers.
服务器通常每台通用服务器平均有一个到两个 BMC。对于 AI 服务器,BMC 的内容因形状因素和 SKU 而异。在本节中,我们将分析 Nvidia AI 服务器和非 Nvidia AI 服务器的 BMC 内容。
In the GB200 NVL72 reference design with two Bluefield-3, there are 87 BMCs, including:
在 GB200 NVL72 参考设计中,配备了两个 Bluefield-3,共有 87 个 BMC,包括:
2 to 4 BMCs for compute tray
2 到 4 个 BMC 用于计算托盘one BMC for HMC (hardware management console),
一个 BMC 用于 HMC(硬件管理控制台),one BMC for DC-SCM (datacenter-ready security control module),
一个 BMC 用于 DC-SCM(数据中心就绪安全控制模块),one BMC for each Bluefield-3 DPU,
每个 Bluefield-3 DPU 一个 BMC,
one BMC for each NVSwitch tray,
每个 NVSwitch 托盘一个 BMC,one BMC for out of band management switch, and
一台用于带外管理交换机的 BMC,和one BMC for PDU/power shelves.
一个 BMC 用于 PDU/电源架。
As explained in the previous networking section, very few CSPs and OEMs will do Bluefield-3 for the frontend network. If they adopt Bluefield-3, most would go with a single instead of the dual configuration for the frontend network. For NVL72 without Bluefield-3, there are only 51 BMCs (87 BMCs minus 36 BMCs for Bluefield-3).
如前面的网络部分所述,极少数 CSP 和 OEM 会在前端网络中使用 Bluefield-3。如果他们采用 Bluefield-3,大多数会选择单一配置而不是双重配置。对于没有 Bluefield-3 的 NVL72,只有 51 个 BMC(87 个 BMC 减去 36 个用于 Bluefield-3 的 BMC)。
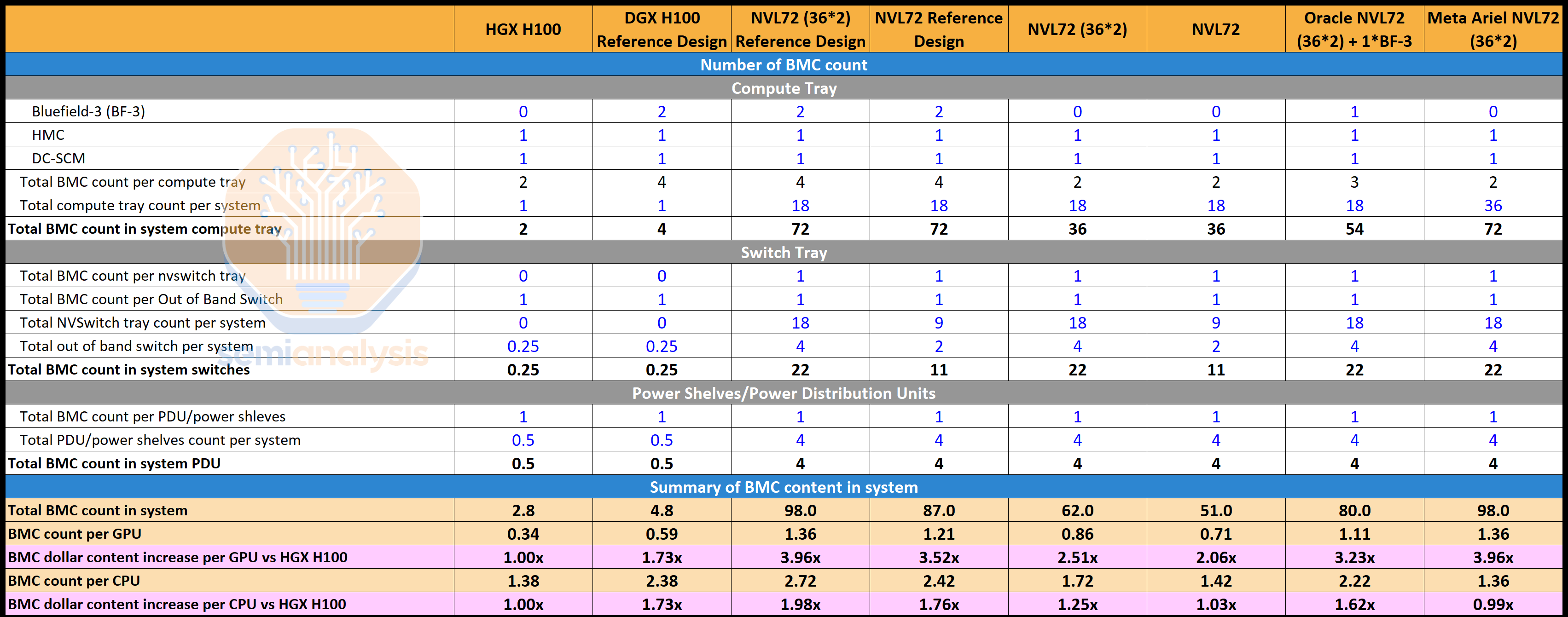
来源:SemiAnalysis GB200 组件与供应链模型
Among major buyers, Google, Microsoft, Meta, and AWS will use their custom NICs instead of Bluefield-3 for HGX and NVL72/NVL36. Oracle uses Bluefield-3, but only one Bluefield-3 instead of two for its NVL36 * 2 system. As a result, there are 80 BMCs for Oracle’s NVL36 *2 server, less than 98 BMCs for a reference NVL36*2 form factor.
在主要买家中,谷歌、微软、Meta 和 AWS 将使用他们的定制 NIC,而不是 Bluefield-3,用于 HGX 和 NVL72/NVL36。甲骨文使用 Bluefield-3,但仅为其 NVL36 * 2 系统使用一个 Bluefield-3,而不是两个。因此,甲骨文的 NVL36 * 2 服务器有 80 个 BMC,少于参考 NVL36 * 2 形态的 98 个 BMC。
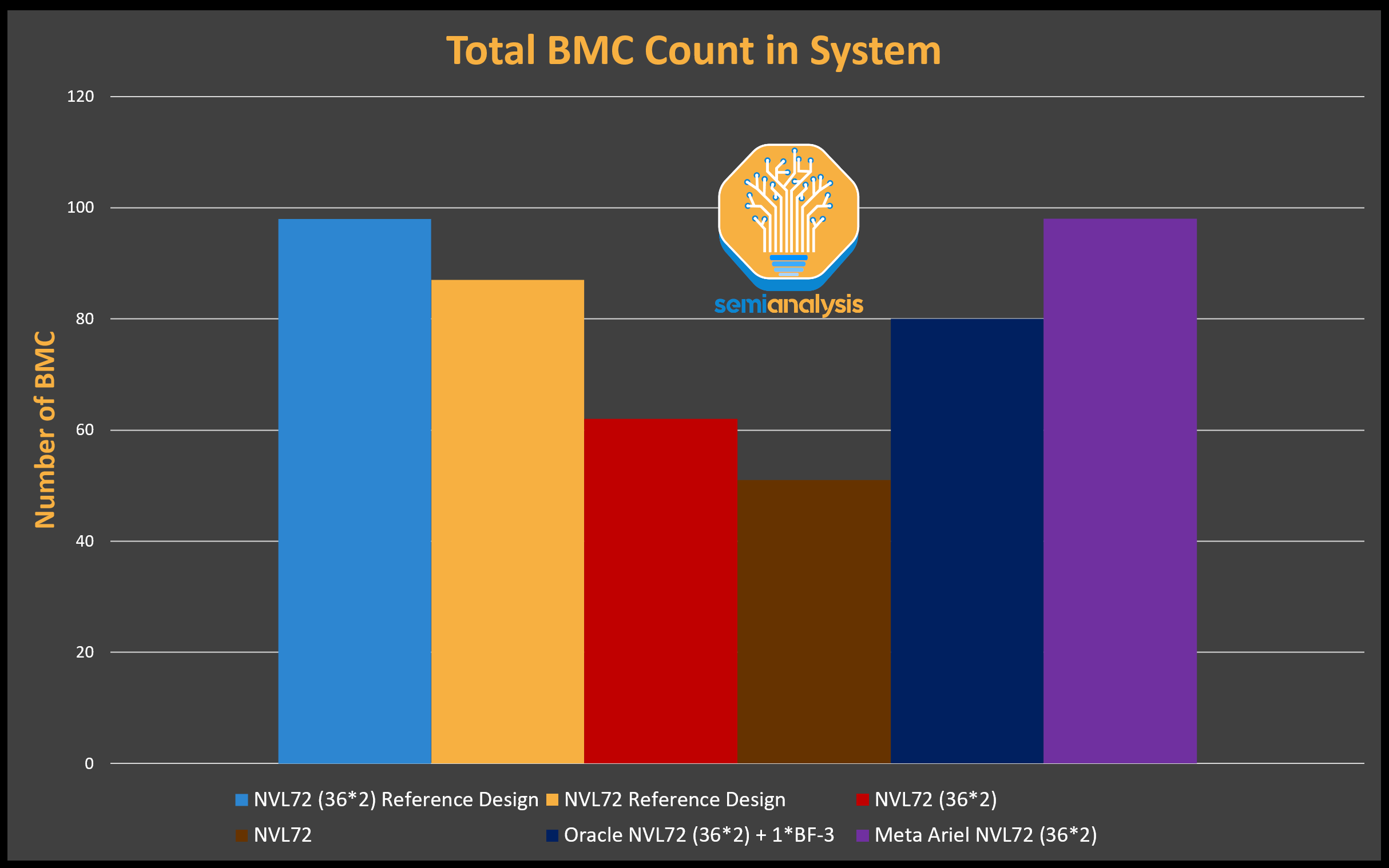
来源:SemiAnalysis GB200 组件与供应链模型
We can use BMC per GPU metric to compare the BMC content of different GB200 SKUs to that of HGX. Even the NVL72 system without Bluefield, which has the least BMC content among GB200 SKUs, has double the BMC to GPU ratio over HGX.
我们可以使用每个 GPU 的 BMC 指标来比较不同 GB200 SKU 的 BMC 内容与 HGX 的 BMC 内容。即使是没有 Bluefield 的 NVL72 系统,它在 GB200 SKU 中 BMC 内容最少,其 BMC 与 GPU 的比例也超过 HGX 的两倍。
Although the BMC per GPU metric is sufficient to estimate the incremental BMC TAM of the GB200 system, we believe the BMC content increase per CPU metric provides another interesting perspective when analyzing BMC content. The GB200 system without Bluefield-3 have BMC content increase per CPU multiple around 1 times. In other words, BMC content does not increase per CPU from HGX H100 to the GB200 system without the significant incremental BMC content from Bluefield-3.
尽管每个 GPU 的 BMC 指标足以估算 GB200 系统的增量 BMC 总可寻址市场(TAM),但我们认为每个 CPU 的 BMC 内容增加指标在分析 BMC 内容时提供了另一个有趣的视角。没有 Bluefield-3 的 GB200 系统每个 CPU 的 BMC 内容增加倍数约为 1 倍。换句话说,从 HGX H100 到没有 Bluefield-3 的 GB200 系统,每个 CPU 的 BMC 内容并没有增加,缺乏来自 Bluefield-3 的显著增量 BMC 内容。
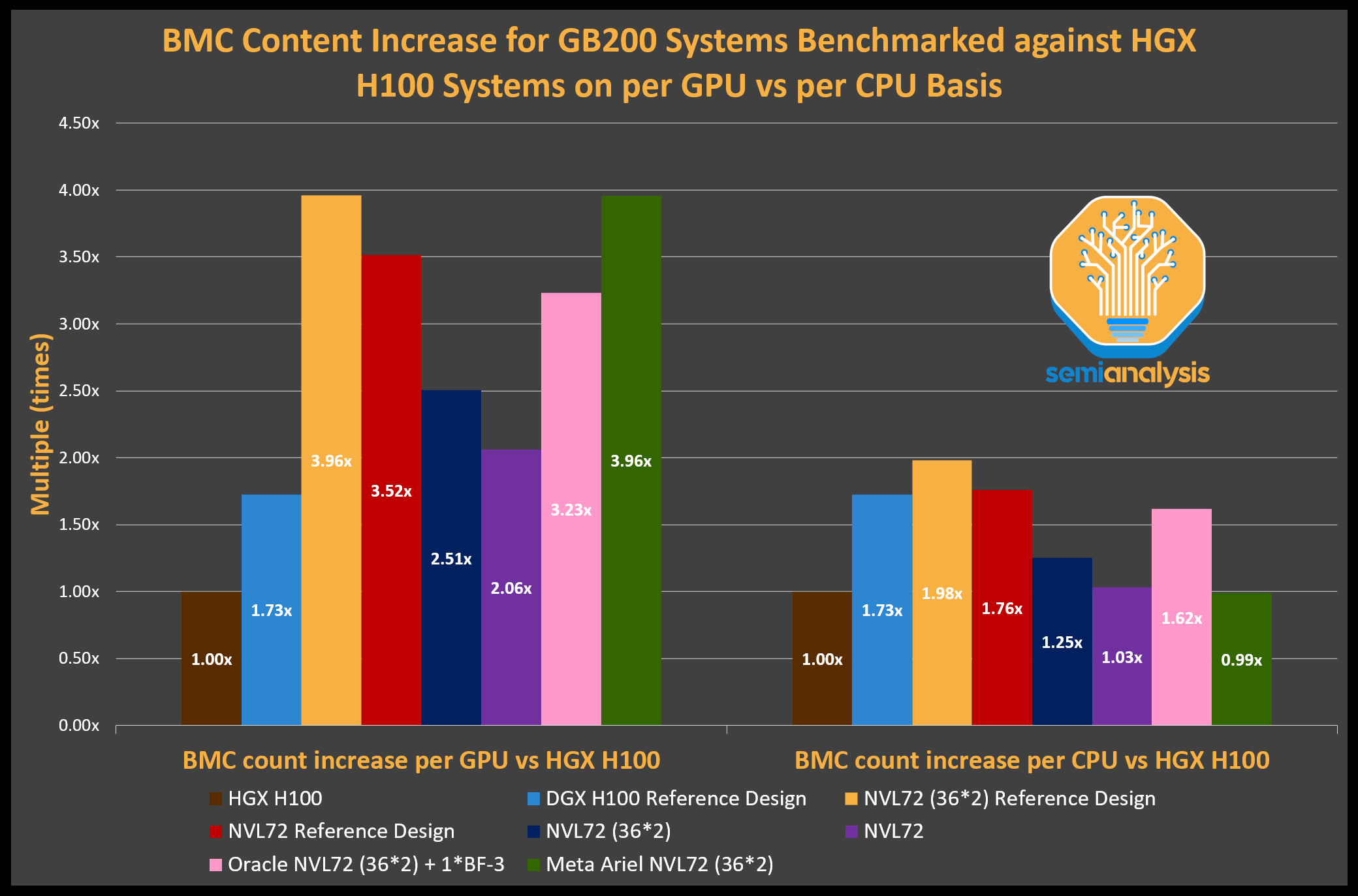
来源:SemiAnalysis GB200 组件与供应链模型
In conclusion, the main driver of higher BMC content for GB200 over HGX is the shift from the 2:8 CPU to GPU ratio for HGX to the 2:4 CPU to GPU ratio for GB200. This makes even more sense when you compare the BMC content increase per GPU against the BMC content increase per CPU of the Meta Ariel form factor with a 1:1 CPU to GPU ratio. (Typically, in AI accelerator and general servers, you have 2 CPUs per server chassis and the BMC content is directly tied to the server chassis. This is why it is essential to look at both per CPU and per GPU ratio).
总之,GB200 的 BMC 内容较 HGX 更高的主要驱动因素是 HGX 的 2:8 CPU 与 GPU 比例转变为 GB200 的 2:4 CPU 与 GPU 比例。当你将每个 GPU 的 BMC 内容增加与 Meta Ariel 形态因子中 1:1 CPU 与 GPU 比例的每个 CPU 的 BMC 内容增加进行比较时,这一点更为合理。(通常,在 AI 加速器和通用服务器中,每个服务器机箱有 2 个 CPU,而 BMC 内容与服务器机箱直接相关。这就是为什么必须同时关注每个 CPU 和每个 GPU 的比例)。
We share estimates of the year-over-year change in BMC demands for general servers and AI servers based on the GPU/accelerator shipments in our Accelerator Model and our GB200 Component & Supply Chain Model. This includes the BMC breakdown for each client's different AI form factors, as discussed above.
我们根据我们的加速器模型和 GB200 组件与供应链模型,分享了对通用服务器和 AI 服务器的 BMC 需求年同比变化的估计。这包括上述讨论的每个客户不同 AI 形态的 BMC 细分。
Key Assumptions for this estimation:
此估算的关键假设:
For HGX/NVL36/NVL72 servers for Google, Microsoft, AWS, Meta and Oracle, we calculate the BMC demand based on their system designs.
对于 Google、Microsoft、AWS、Meta 和 Oracle 的 HGX/NVL36/NVL72 服务器,我们根据他们的系统设计计算 BMC 需求。For HGX/NVL36/NVL72 for other buyers, we estimate usage of Bluefield-3, with our assumptions in the table below.
对于 HGX/NVL36/NVL72 的其他买家,我们估计使用 Bluefield-3,具体假设见下表。
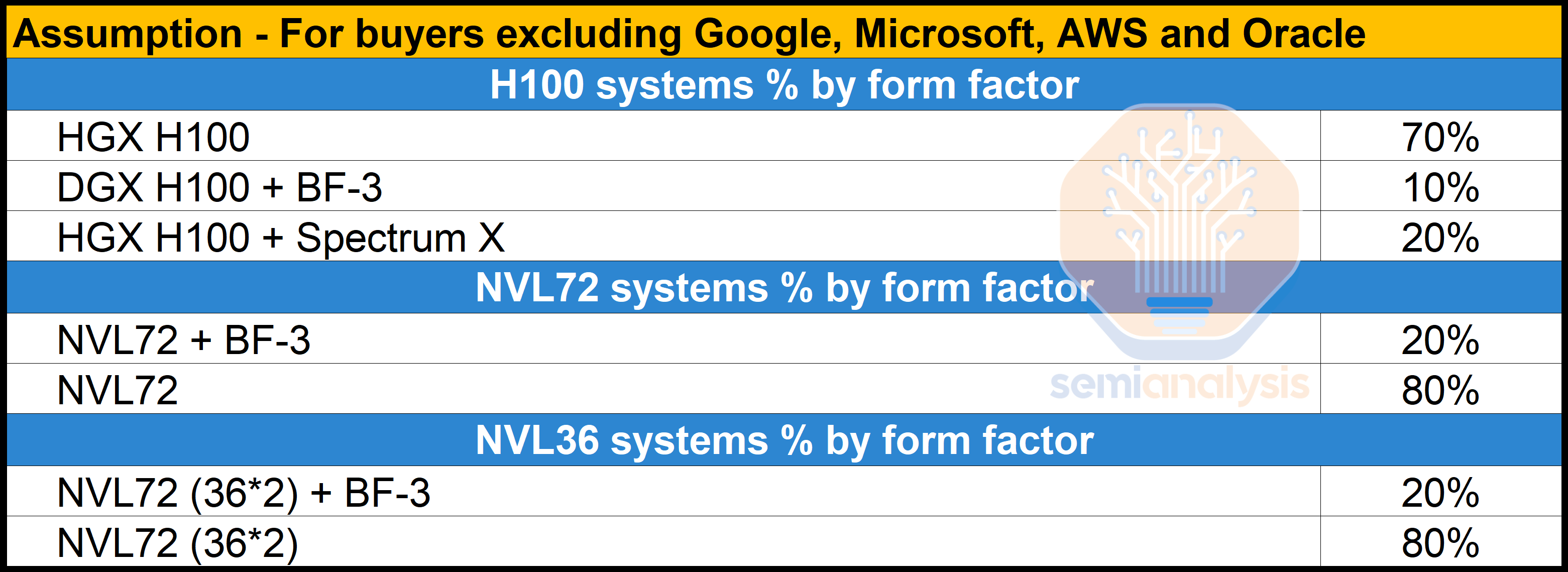
来源:SemiAnalysis GB200 组件与供应链模型
For other AI servers, the majority will have an average of 2.8 BMCs, the same as HGX.
对于其他 AI 服务器,大多数将平均拥有 2.8 个 BMC,与 HGX 相同。For general servers we assume a 10% recovery in 2024 and 5% in 2025.
对于一般服务器,我们假设 2024 年恢复 10%,2025 年恢复 5%。
Given the assumption, our model estimates total BMC shipments increase in 2025, mainly driven by the 64% growth of BMC units for Nvidia-based AI servers. Other AI servers’ BMC demand should also grow. In terms of market size, the Nvidia NVL36/72 systems will increase BMC TAM in 2025, but our estimates differ from the street.
根据假设,我们的模型估计 2025 年 BMC 出货量总量将增加,主要受 Nvidia 基础的 AI 服务器 BMC 单元增长 64%的推动。其他 AI 服务器的 BMC 需求也应有所增长。在市场规模方面,Nvidia NVL36/72 系统将在 2025 年增加 BMC 总可寻址市场,但我们的估计与市场预期有所不同。
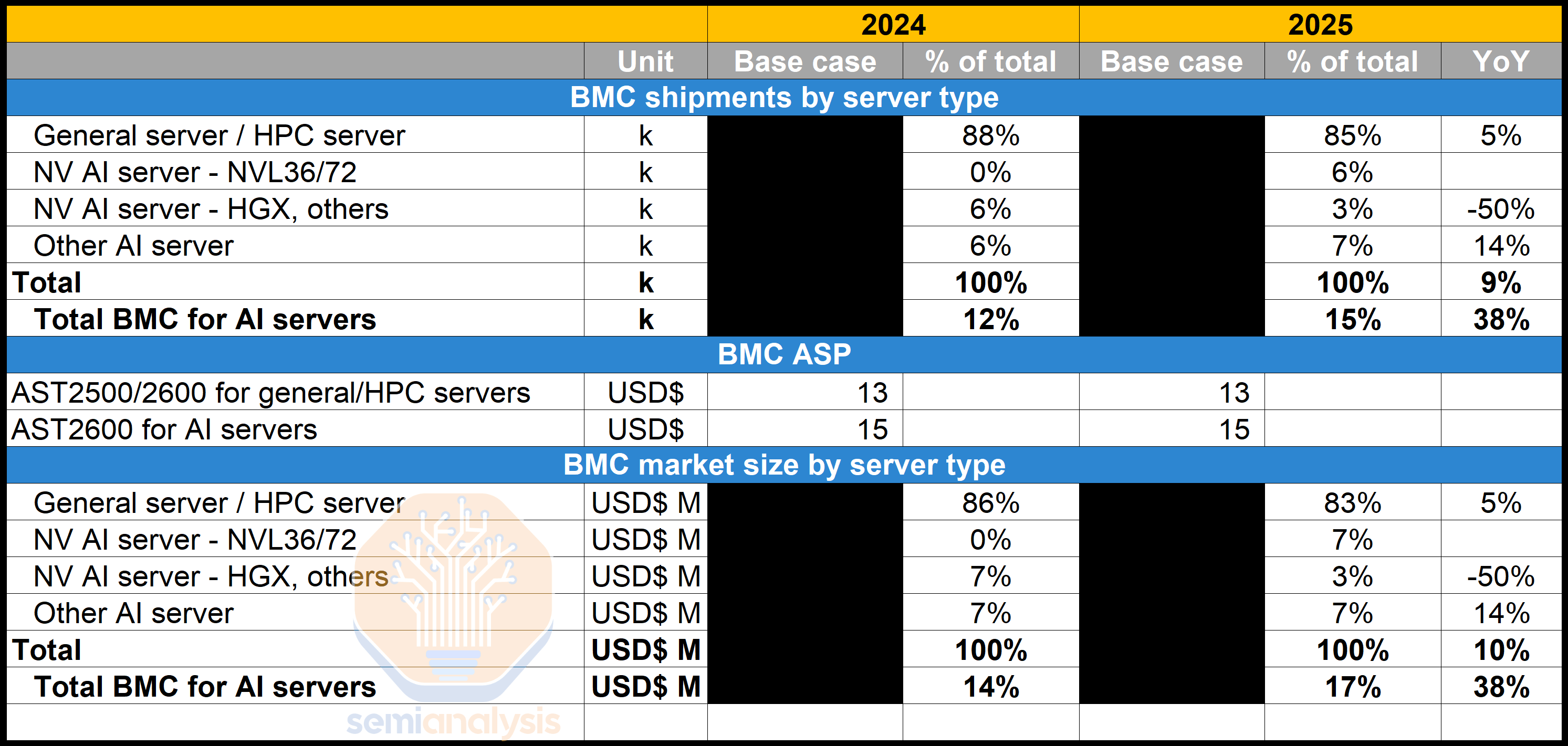
来源:SemiAnalysis GB200 组件与供应链模型
Consensus assumption of the capital market is that the majority or even all NVL36/72 servers will follow Nvidia’s reference design adopting Bluefield-3. However, this is incorrect as the major CSPs will have their custom NICs solutions instead of the Nvidia DPU. A sensitivity analysis must be done to see the upsides if other buyers (non-Google/Microsoft/Meta/AWS/Oracle) use more Bluefield-3. With 20% more buyers using Bluefield-3 based on Nvidia reference design, the BMC units would increase by 25k units, implying 0.5% upside to AI server BMC demand, or just 0.1% upside to total BMC market. If other buyers 100% follow Nvidia’s reference design, the upside to would be 11% for AI-related BMC volume, or only 2% for total BMC volume. In other word, even if other (non-Google/Microsoft/Meta/AWS/Oracle) buyer all adopt the Bluefield-3 DPU solution for their GB200 racks, the total BMC shipment would not increase significantly. This is because that BMC for AI servers only accounts for roughly 17% of BMC shipments only.
资本市场的共识假设是,大多数甚至所有 NVL36/72 服务器将遵循 Nvidia 的参考设计,采用 Bluefield-3。然而,这种假设是错误的,因为主要的 CSP 将有他们定制的 NIC 解决方案,而不是 Nvidia 的 DPU。必须进行敏感性分析,以查看如果其他买家(非 Google/Microsoft/Meta/AWS/Oracle)使用更多 Bluefield-3 的潜在收益。如果基于 Nvidia 参考设计的买家增加 20%使用 Bluefield-3,BMC 单元将增加 25,000 个,这意味着 AI 服务器 BMC 需求的上行空间为 0.5%,或总 BMC 市场的上行空间仅为 0.1%。如果其他买家 100%遵循 Nvidia 的参考设计,AI 相关 BMC 的数量将有 11%的上行空间,而总 BMC 数量仅有 2%的上行空间。换句话说,即使其他(非 Google/Microsoft/Meta/AWS/Oracle)买家全部采用 Bluefield-3 DPU 解决方案用于他们的 GB200 机架,总 BMC 出货量也不会显著增加。这是因为 AI 服务器的 BMC 仅占 BMC 出货量的约 17%。
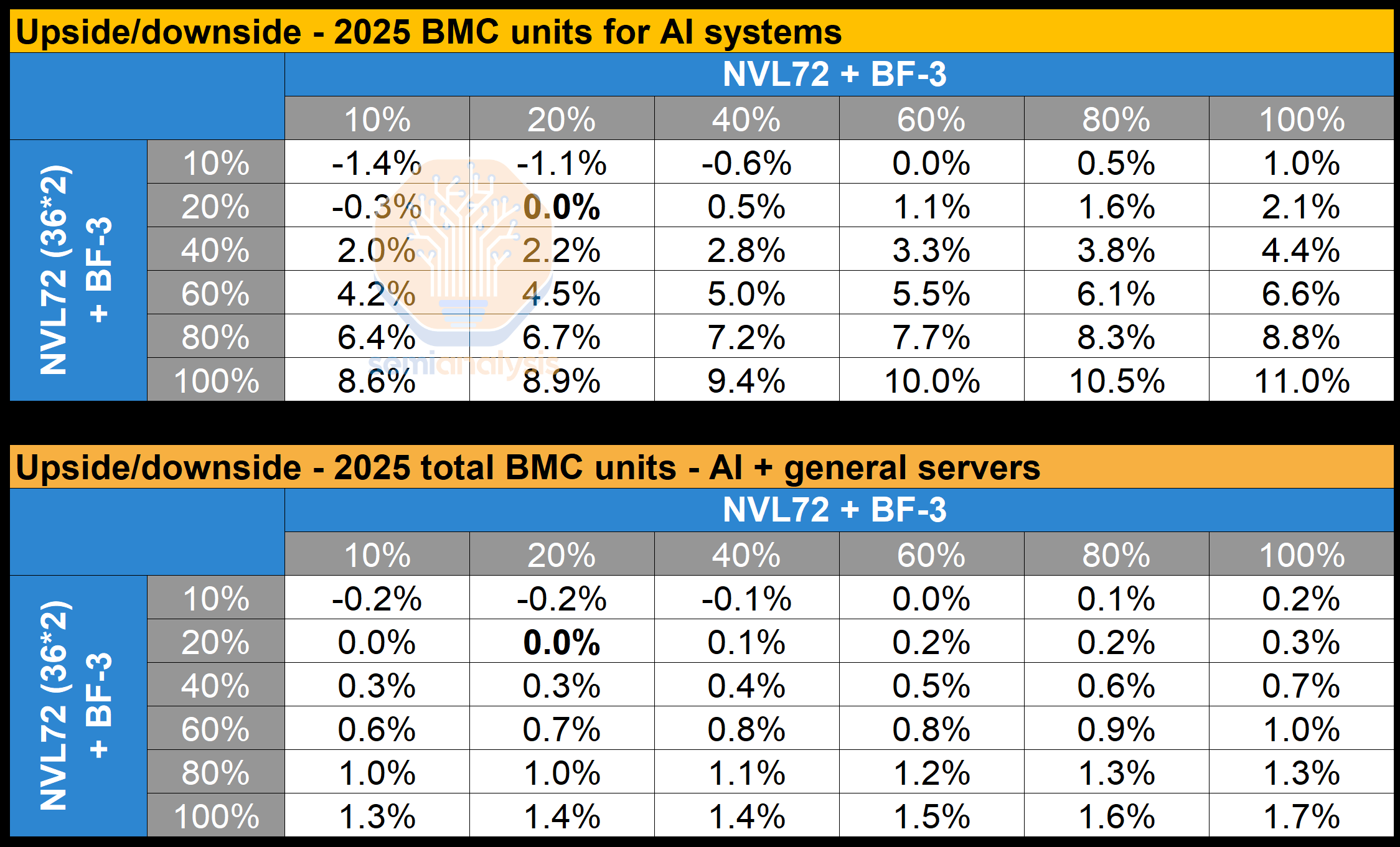
来源:SemiAnalysis GB200 组件与供应链模型
In an unrealistic scenario where all NVL36/72 buyers including Google/Microsoft/Meta/AWS/Oracle all follow Nvidia’s reference design in adopting Bluefield-3, they would require an additional 854k units of BMC, representing 18% upside to AI server BMC demand, or 3% upside to total BMC demand. This would drive the total BMC volume to grow 12% in 2025.
在一个不现实的情境中,如果所有 NVL36/72 的买家,包括谷歌/微软/Meta/AWS/甲骨文,都遵循英伟达的参考设计采用 Bluefield-3,他们将需要额外的 854,000 个 BMC,这代表了 AI 服务器 BMC 需求的 18%的上行空间,或总 BMC 需求的 3%的上行空间。这将推动 2025 年总 BMC 量增长 12%。
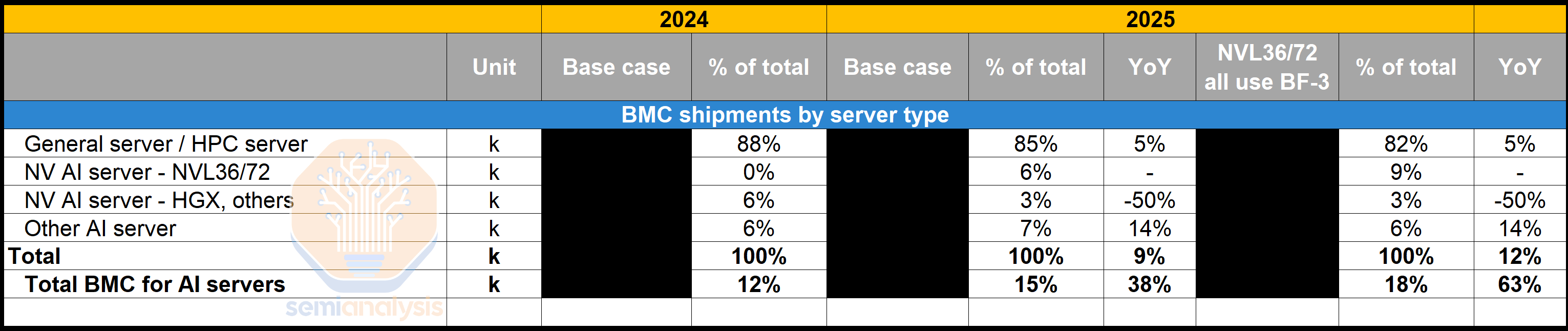
来源:SemiAnalysis GB200 组件与供应链模型
Mechanical Components 机械组件
The two main mechanical components are the chassis and the rail kit. These both benefitted from significant content increases for HGX H100 given the higher 5U-8U chassis and considerable weight that comes with the 3DVC compared to a 1U-2U traditional server. Hence, the chassis and rail kit ASP for HGX both went up ~10 times compared to traditional server.
两个主要的机械组件是底盘和轨道套件。由于 HGX H100 的 5U-8U 底盘更高,以及与 1U-2U 传统服务器相比,3DVC 带来的显著重量,这两者都受益于内容的显著增加。因此,HGX 的底盘和轨道套件的平均销售价格(ASP)相比传统服务器都上涨了约 10 倍。
With the liquid cooling of GB200 architecture, high 5U-8U chassis and high spec rail kit are not necessary not suitable anymore. Hence, the rail kit content is downgraded from HGX to GB200, with a more similar spec to the traditional server. King Slide has an extremely solid technological and IP leadership over its competitors especially for high 5U-8U rail kit, in which King Slide has high share of HGX rail kit. Its 60% gross margin for lower spec 1U or 2U traditional and over 60% gross margin for 5U+ AI server rail kit reflects its pricing power. Note there is a content increase for 10U B200 liquid cooled servers.
随着 GB200 架构的液体冷却,高 5U-8U 机箱和高规格导轨套件不再必要且不适合。因此,导轨套件的内容从 HGX 降级到 GB200,其规格更接近传统服务器。金滑在其竞争对手中拥有极为强大的技术和知识产权领导地位,尤其是在高 5U-8U 导轨套件方面,金滑在 HGX 导轨套件中占有较高的市场份额。其低规格 1U 或 2U 传统服务器的毛利率为 60%,而 5U+ AI 服务器导轨套件的毛利率超过 60%,反映了其定价能力。请注意,10U B200 液冷服务器的内容有所增加。
Although Nan Juen(Repon) is still slightly behind King Slide in terms of IP for the 5U+ rail kit, it will gain share from King Slide at GB200 due to the lower IP barrier to overcome. However, this is unlikely to drive the pricing down as Nan Juen’s pricing is only slightly less than King Slide who determine the pricing for the market.
尽管南骏(Repon)在 5U+轨道套件的知识产权方面仍略逊于 King Slide,但由于克服的知识产权障碍较低,它将在 GB200 上从 King Slide 那里获得市场份额。然而,这不太可能导致价格下降,因为南骏的定价仅略低于 King Slide,而后者决定市场价格。
The chassis will have slightly better pricing than the traditional server of the same height due to better material and thicker chassis for GB200 compute tray. The main players of chassis for GB200 will be Chenbro and AVC. Note players like Ingrasys will make their own chassis.
底盘的定价将比同高度的传统服务器略有优势,因为 GB200 计算托盘使用了更好的材料和更厚的底盘。GB200 底盘的主要供应商将是 Chenbro 和 AVC。需要注意的是,像 Ingrasys 这样的公司将会制造自己的底盘。
OEM / ODM Mapping OEM / ODM 映射
OEM and ODM details are also very important as there is a big shift generation on generation. There is a fear from some that OEMs get much weaker. This is not the case because complexity of deployments is much higher. Another fear is that Quanta loses tons of share to Ingrasys, but that is only at Microsoft. We have all these details and more in the GB200 Component & Supply Chain Model.
OEM 和 ODM 的细节也非常重要,因为每一代之间都有很大的变化。一些人担心 OEM 会变得更弱,但事实并非如此,因为部署的复杂性要高得多。另一个担忧是广达会在英迈科技面前失去大量市场份额,但这仅限于微软。我们在 GB200 组件和供应链模型中有所有这些细节和更多信息。















In the article it says "most customers will opt for the NVL36x2 design due to power and colling constraints which we will discuss below." However I'm not seeing where that distinction is discussed. The challenges and benefits of different types of cooling and different power consumptions per rack are there - but I'm not understanding A+B = C. Appreciate any clarification or reference to a line I'm missing, please.
在文章中提到“由于电力和冷却限制,大多数客户将选择 NVL36x2 设计,我们将在下面讨论。”然而,我没有看到讨论这种区别的地方。不同类型的冷却和每个机架的不同功耗的挑战和好处都有提到——但我不明白 A+B=C。感谢任何澄清或指向我遗漏的行。
1 条回复来自迪伦·帕特尔
True? https://www.theinformation.com/articles/nvidias-new-ai-chip-is-delayed-impacting-microsoft-google-meta
真的? https://www.theinformation.com/articles/nvidias-new-ai-chip-is-delayed-impacting-microsoft-google-meta