
ClassHyPer:基于ClassMix的混合扰动,用于遥感影像的深度半监督语义分割
作者:
1
西安大略大学地理与环境系,伦敦,ON N6A 3K7,加拿大
2
中山大学地球空间工程与科学学院, 珠海519082
*
应向其通信的作者。
遥感, 2022, 14(4), 879;https://doi.org/10.3390/rs14040879
提交日期:2022 年 1 月 3 日 / 修订日期:2022 年 1 月 26 日 / 录用日期:2022 年 2 月 9 日 / 出版日期:2022 年 2 月 12 日
(本文属于《深度学习在遥感图像分类中的应用》特刊)
下载浏览图表版本注释
抽象
在深度学习(DL)的巨大成功和遥感数据可用性的提高的启发下,基于深度学习的图像语义分割在遥感界引起了越来越多的兴趣。深度学习应用的理想场景需要大量与感兴趣区域具有相同特征分布的标注数据。然而,获得如此庞大的训练集以适应目标区域的数据分布是非常耗时和昂贵的。基于一致性正则化的半监督学习 (SSL) 方法因其易于实现和卓越的性能而越来越受欢迎。然而,SSL在遥感中的应用有限。本文从数据级和模型级扰动的角度,综合分析了几种基于一致性正则化的先进SSL方法。然后,引入一种基于混合扰动范式的端到端SSL方法,在有限数量的标签下提高深度学习模型的性能。该方法集成了语义边界信息,在进行数据级扰动时生成更有意义的混合图像。此外,通过使用基于模型级扰动的隐式伪监督,它消除了在训练中设置额外阈值参数的需要。此外,它可以以端到端的方式灵活地与深度学习模型配对,而不是传统伪标记中使用的分离训练阶段。5个遥感基准数据集在道路、建筑物和土地覆被分割应用中的实验结果验证了所提方法的有效性和鲁棒性。 特别令人鼓舞的是,在所有基准数据集上,使用具有 5% 标签的所提出方法与使用具有 100% 标签的纯监督方法获得的准确率之比超过 89%。
1. 引言
近年来,高分辨率遥感数据的数量和可用性不断提高,在城市规划、农业监测和灾害监测中,快速、准确地提取语义信息在城市规划、农业监测和灾害监测中得到了极大的关注[1,2]。传统的基于阈值和区域的方法可以在不需要大量标记数据的情况下执行图像分割,尽管其结果很粗糙[3]。受到深度学习 (DL) 在计算机视觉领域取得成功的启发,遥感社区还将这种最先进的技术引入像素分类(也称为语义分割)。与传统的机器学习技术(例如随机森林或支持向量机)相比,深度学习的优势在于它仅从海量数据中自动利用特征表示,而不是基于特定领域的知识手工制作特征[4]。
一般来说,基于海量标记训练数据的监督学习因其高精度和鲁棒性而成为深度学习的主流解决方案[ 5]。然而,创建标记数据通常既耗时又昂贵。由于场景复杂性高,在遥感应用中获取高质量的像素级标签进行语义分割尤其具有挑战性。例如,Ji等[6]花了大约6个月的时间创建了他们的WHU建筑数据集(8188张标记的航空图像和3742张标记的卫星图像,512×512像素),而Luo等[7]花了将近4个月的时间来注释他们的航空图像阴影数据集(514张标记图像从256×256到1688×1688像素不等)。这两个例子都反映了遥感中语义分割的标注工作的难度,特别是当面对来自卫星、飞机和无人机等各种平台的越来越多的地球观测数据时。
为了应对标记训练数据的挑战,越来越多的研究开始研究如何在保持深度学习模型性能的同时减少标签,其中一些研究试图基于多时相遥感数据之间的时间一致性进行纯无监督学习[ 8, 9]。与使用标记训练数据的方法相比,这些方法具有更高的计算效率,但准确性较低。此外,一些研究[ 10, 11]更关注遥感范围内的图像合成与平移,从而以合成的方式产生更多的标记数据。然而,由于缺乏对合成过程的特定控制,合成数据的特征分布往往与真实数据的特征分布不一致。此外,来自OpenStreetMap[12]或地籍图[13]的低质量参考数据也被用作深度学习模型训练的标签,尽管它们的性能相对较差。最近,自监督学习范式(如对比学习)试图通过分别减少和增加类内和类间表示与大量未标记数据的距离来表征潜在空间,然后将其应用于下游任务,尽管需要大量的计算资源,但在一系列应用中取得了令人印象深刻的结果[ 14, 除了上述方法之外,还有几种广泛使用的解决方案具有不错的性能,例如迁移学习(TL)、弱监督学习(WSL)和半监督学习(SSL),它们强调从相关任务中转移模型能力,或者在训练中使用来自感兴趣目标的弱标签或很少的标签。
TL侧重于将从一个注释丰富的域(源域)学到的知识转移到一个相关但注释稀缺的域(目标域),以提高模型跨域的可用性[16]。通常,域适应(DA)和参数转移是基于神经网络的方法中两种流行的TL方案[17,18]。DA 旨在减少特征的域偏移,以便在源数据中启用适用于未标记目标数据的预训练模型。尽管发展议程最近取得了进展,但由于其相对较弱的性能,它仍然具有挑战性。参数转移假设不同但相关任务的单个模型可以共享一些参数,从而允许它们跨域传输。在实践中,参数传递因其易于实现和高效而得到更广泛的应用。基于这一策略,遥感研究人员结合有限的任务依赖性训练数据,开展了土地覆被分类[19]、场景分类[20]、贫困制图[21]、建筑物提取[22]等多种应用。基于参数的TL已被广泛用于缓解标记数据缺陷,而过拟合和负转移方面仍然存在挑战[ 17]。因此,基于参数的 TL 通常与其他技术(如 WSL 和 SSL)配对,以鼓励 DL 模型在使用很少的标签时获得更好的性能。
在训练过程中,WSL 尝试将像素级标签替换为粗略的批注,例如框标签或图像级标签,以减少人工标记工作。Chen等[ 23]提出了一种使用图像级标签作为建筑物检测监督信息的WSL方法。此外,开发了一种基于图像级标注的弱监督特征融合网络(WSF-Net),用于对水和云数据集进行分割[24]。这些研究利用弱标签,取得了与纯监督方法相当的结果,从而展示了WSL方法在遥感图像分割中的实用性。WSL 似乎能够在一定程度上减少注释工作。然而,在训练过程中仍然需要大量的弱标签,像素级标注在实际应用中可以优于弱标注。
与 TL 和 WSL 不同,SSL 旨在使用仅具有一小部分样本标签的数据集来训练模型 [ 5]。大多数SSL方法都集中在扩大数据分布以提高模型的泛化性,或者从大量未标记的数据中学习潜在特征,使决策边界位于低密度区域[ 5, 25]。值得注意的是,最近的SSL方法,如Mean Teacher [ 26]、CutMix [ 27]和FixMatch [ 28],已经逐步将图像分类性能推向了计算机视觉领域的高水平。与此同时,遥感界也试图研究SSL在广泛的应用中的标签缺陷,如土地覆盖分类[19]、场景分类[29]和建筑物提取[15]。值得注意的是,华等[30]提出了一种具有稀疏注释的半监督方法,用于遥感图像的语义分割。该方法基于特征和空间关系正则化建立无监督损失,同时利用点、线或多边形形式的稀疏标注像素计算监督损失。这种方法在模型性能和标记工作之间实现了不错的权衡,尽管稀疏注释忽略了类边界信息。Wang等[31]遵循经典的密集标注流水线,提出了一种用于遥感图像分割的SSL方法(CRAUP),该方法将一致性正则化与随机颜色抖动(类似于FixMatch)和伪标签的平均更新相结合。为了进一步提高SSL的性能,Wang等人。 [ 32] 采用 RanPaste 算法(类似于 CutMix)来增强数据扰动,并在训练中加入 Mean Teacher 和伪标记方法,在不同数据集上的表现优于 CRAUP 方法。请注意,这两项研究涉及伪标记和一致性正则化方案。伪标记直接利用未标记数据中预测的标签来指导训练过程,这是一种即插即用的方法,可以很容易地与现有的深度学习模型集成[25]。然而,确定置信预测的阈值仍然是一个悬而未决的问题,迄今为止还没有开发出通用的方法。此外,伪标记方法的训练过程不稳定且繁琐,导致多类分割任务的结果较差[31]。相比之下,一致性正则化背后的关键思想是鼓励模型对以各种方式受到干扰的未标记输入给出一致的预测[33]。通常,这可以通过确保具有轻微扰动的相同输入数据通过同一模型具有一致的输出(数据级扰动)来工作,或者具有较小扰动的模型为相同的输入数据生成一致的输出(模型级扰动)。例如,图像对比度、颜色和亮度的微小变化不应对深度语义分割模型的最终预测产生重大影响,具有相同架构但不同启动参数的模型应该在同一输入上获得类似的预测。一般来说,一个好的深度学习模型应该是鲁棒的,并且对轻微的扰动表现出很强的泛化能力。 基于这种策略,可以根据原始输入的输出与其扰动变体之间的差异来构建一致性损失,从而允许在训练过程中使用未标记的数据。值得注意的是,这一系列算法可以在训练阶段隐式利用伪标签信息,而不是在预测的置信度值方面显式使用它,从而避免了置信阈值设置的棘手步骤和无用预测的负面影响。
为了在密集标注范式的基础上探索基于扰动的SSL流水线的潜力,并提升模型在遥感图像语义分割中的性能,本文首先从数据级和模型级的扰动角度阐述了几种具有代表性的一致性学习方案。然后,基于这些方案,我们改编了一个融合了交叉伪监督和ClassMix的端到端半监督语义分割框架。使用5个遥感基准数据集对所提出的方法进行了评估,并与几个相关的基于扰动的方案进行了比较。
本研究的主要贡献如下:
- (1)
我们从数据和模型级扰动的角度综合分析了几种基于一致性正则化的深度半监督语义分割方法。据我们所知,我们不知道有任何研究从这个角度探讨了基于一致性正则化的遥感SSL方法;- (2)
为了提高深度学习模型在标签数量有限的情况下进行遥感图像分割的性能,引入了一种采用混合扰动范式的端到端半监督语义分割框架ClassHyPer;- (3)
通过对涉及道路、建筑物和土地覆被分割的五个遥感基准数据集的广泛实验,我们证明了 ClassHyPer 在遥感应用中的有效性和鲁棒性;- (4)
为了进一步推动该领域的探索和调查,我们计划在 https://github.com/YJ-He/ClassHyPer(2022 年 1 月 2 日访问)上公开相关代码。
二、相关作品
2.1. 遥感语义分割
到目前为止,大多数基于深度学习的语义分割方法都基于全卷积网络(FCN)架构[34]及其多种变体进行像素密集预测。基于FCN的模型由于在计算机视觉领域的优越性能,也被遥感界引入像素级遥感图像分割。随着遥感标注数据的不断增多和计算能力的不断提高,越来越多的研究使用基于FCN的语义分割方法提取建筑物[6]、道路[35]、土地覆被[36]、阴影[7]和云[37]。Ji等[6]基于自建的大型遥感影像数据集(WHU建筑数据集)开发了暹罗U-Net提取建筑物。该研究的结果证明了新模型的数据集质量高、性能良好,促使许多研究人员开发了大量基于FCN的语义分割模型。提出了一种用于道路提取的D-LinkNet[35],对膨胀卷积进行积分以扩大感受野并集成多尺度特征。DeepGlobe 2018 道路提取挑战赛的结果证明了其竞争性能。为了提高深度学习模型在复杂城市场景中的性能,Zheng等[ 36]提出了一种用于语义分割的EaNet,结合了边缘感知损失和大核金字塔池化模块。该方法能够准确捕获地面和空中城市场景数据集中的多尺度语义特征,例如Cityscapes [ 38]、ISPRS Vaihingen [ 39]和WHU Aerial Building数据集[ 6]。 此外,开发了一种用于阴影检测的深度监督卷积神经网络(DSSDNet)[7],用于基于用于阴影检测的航空图像数据集(AISD)提取阴影。此外,还创建了一个基于18张Landsat-8卫星图像的像素级云数据集[37],以评估基于深度学习的分割算法。很明显,关注为基于深度学习的语义分割方法创建的数据集的研究数量有所增加。反过来,数据集数量的增加也促进了各种算法的不断改进。算法和数据集的发展使深度学习相关的研究和应用保持活跃和繁荣。然而,所有这些研究都依赖于大量标记的训练数据来获得良好的性能,这在实际的遥感应用中仍然具有挑战性。
2.2. 面向遥感的半监督语义分割
最近,一些研究试图通过利用大量未标记数据以及基于SSL管道的一小部分标签进行遥感图像分割来提高深度学习模型的性能。SSL最关键的组成部分是基于特定假设的无监督损失的构造,它使用未标记的数据指导训练过程。各种无监督学习任务已被设计用于执行 SSL。例如,在具有稀疏标注的遥感语义分割中,利用像素的特征和空间关系构建对比损失[30]。Protopapadakis等[ 40]采用堆叠自动编码器从大量未标记的图像中学习潜在表示。此外,伪标签[ 41]的工作原理是迭代利用伪标签来指导训练过程所需的未标记数据。无监督损失是通过从伪标签到预测的监督来制定的。显然,通过集成现有的深度学习模型,伪标记很容易实现。因此,该技术已应用于众多遥感应用。例如,Tong等[19]利用伪标记来提高卫星图像上土地覆盖分类的深度模型的可转移性。Li等[42]设计了一种基于伪标记和条件随机场的SSL分类框架,用于高光谱图像分类和分割。实验结果表明了伪标注在遥感应用中的有效性。然而,为了确定置信预测的阈值,需要额外的方法,并且迄今为止还没有一种放之四海而皆准的方法。 此外,当模型以高置信度对未标记的数据生成许多无用的预测时,训练过程可能会变得不稳定[43]。
一致性正则化是另一类为SSL开发的算法,它通过鼓励网络的预测在观测样本附近保持一致来为目标函数做出贡献[5]。由于其卓越的性能,基于扰动的方案已成为最有效的一致性正则化方法之一。关于计算机视觉领域的图像级分类任务,已经开发了多种方法,包括数据级扰动(例如,Cutout [ 44]、MixUp [ 45]、FixMatch [ 28])和模型级扰动(例如,时间融合 [ 46] 和 Mean Teacher [ 26])。同时,数据级扰动方法(如CutMix [ 27]、CowMix [ 33]、ClassMix [ 47]、ComplexMix [ 48])和模型级扰动方法(如引导式协同训练[ 49]、交叉一致性训练 [ 50]、交叉伪监督 [ 51])在语义分割应用中蓬勃发展。随着SSL算法的显著发展,一些遥感研究试图将不同的SSL技术结合起来。例如,Wang等[31]提出了一种类似FixMatch的方法,结合伪标记和Mean Teacher进行基于SSL的遥感图像分割。随后,Wang等[32]在前人工作[31]的基础上,通过集成类似CutMix的方案和伪标记,进一步提高了模型性能。尽管这些研究在基于SSL的遥感语义分割方面取得了进展,但在其方法中使用伪标签方案使得训练过程离散且复杂。与伪标记方法不同,基于扰动的方法更灵活,更容易以端到端的方式与深度学习模型集成。 通常,基于扰动的方法将一致性损失嵌入到总成本函数中,并通过训练进行优化,而不是执行单独的训练和再训练过程。此外,它们不需要确定置信度阈值,从而降低了训练过程的复杂性和难度。
回顾最新的SSL语义分割方法,我们发现基于增强的方法(如CutMix和ClassMix)是突出的数据级扰动方案。同时,Mean Teacher 和交叉伪监督是模型级扰动管道的两个典型代表。受这些著名方法的启发,我们引入了一种端到端的混合扰动方法,即ClassHyPer,用于遥感图像的语义分割,并带有密集的注释。
第3章 方法论
3.1. 问题定义
给定一组N张标记图像和一组 P张未标记图像(P >> N), 指第-个未标记图像,同时 表示第-张带有空间维度 的标记图像及其对应的像素级标签 ,其中C为类数。SSL 语义分割任务旨在通过合并少量 来自的标记数据和来自 的大量未标记数据来训练模型,以便我们可以获得比仅使用标记数据的模型更好的模型。
通常,传统的语义分割监督学习仅包含基于标记图像的像素交叉熵损失公式化的监督损失:
其中 θ 表示 DL 模型 f 的参数。
在 SSL 期间,会根据一致性正则化管道添加无监督丢失 。如前所述,有两类方法:一类是基于输入数据及其预测的扰动的数据级扰动方法,另一类是基于模型参数扰动的模型级扰动方法,其损失项可以分别表述为公式(2)和(3):
其中 (.,.)是测量前扰动和扰动后差异的距离函数,我们可以根据具体情况使用交叉熵或均方误差函数; (.) 表示扰动来自未标记图像的预测的函数; 表示添加到模型参数中的小扰动。最后,SSL 的积分损失函数 是有监督损失和无监督损失的总和,如公式 (4):
其中 > 0 表示权衡权重,它控制了无监督项在总损失中的相对重要性;在后面的实验中,我们将根据经验将其设置为 1。基于损失项 ,我们可以利用梯度下降和反向传播算法来优化模型参数。
本研究的重点是研究四种突出的基于一致性正则化的SSL方法:两种用于数据级扰动,两种用于模型级扰动。然后,介绍了一种基于混合扰动方案的端到端SSL方法。
3.2. 数据级扰动
3.2.1. CutMix的
CutMix [ 27] 集成了 Cutout [ 44] 和 MixUp [ 45] 方法,它们从图像 A 中切割一个或多个具有随机纵横比和位置的矩形区域,并将它们粘贴到图像 B 上以合成新的混合图像(图 1)。通常,CutMix 用作 DL 中的数据增强方法,通过生成更多合成数据来扩展训练数据大小。在这里,它被用作SSL上下文中基于一致性正则化的方法,通过对未标记的图像及其预测施加扰动。操作公式如下:
式中 分别表示合成图像和基于未标记图像 的预测 ; 是一个二进制蒙版,指示在两个图像中剪切和填充的位置; 表示逐元素乘法,而 1 表示完全充满 1 的掩码; 并 分别表示图像 和 通过深度学习模型 的输出,θ 表示模型参数。

图 1.用于 SSL 语义分割的 CutMix 图示: 和 是两个未标记的图像, 是用于语义分割的 DL 模型。我们将 和 输入到模型中,得到相应的预测 和 ,然后基于掩码 将它们混合并实现混合预测 。 同时,我们基于相同的掩码进行混合 和 进入 ,并将其馈送到模型中,得到预测结果 )。 最后,一致性损失 可以根据 ) 和 之间的 差异来计算。
因此,如公式(7)所示,一致性损失是根据混合图像的预测 和混合预测之间的差异计算 的。然后,将一致性损失与监督损失 相结合,使用梯度下降算法一起训练模型。
3.2.2. 类混合
ClassMix [ 47] 可以看作是 CutMix 的泛化;两者之间的唯一区别是掩码 M 的生成方式。ClassMix 不是剪切和粘贴矩形区域,而是从图像 A 中剪切部分预测类并将其粘贴到图像 B 上,从而形成一个合成图像,可以更好地保留图像 A 中对象的语义边界。如图 2 所示,掩码是从语义边界派生而来的,使混合图像更有意义。这样,经过训练的模型不仅可以对图像上下文的变化保持鲁棒性,还可以对不同的图像遮挡保持鲁棒性。该方法已应用于Cityscapes数据集[38],该数据集是为自动驾驶汽车驾驶的算法测试而创建的,并取得了比CutMix更好的结果。这种改进可以归因于两个因素:(1)创建的蒙版的多样性,这源于每个图像包含不同的类,每个类包含多个对象,导致训练中的蒙版多样化。增加的多样性有助于增强数据分布,提高模型的泛化能力。(2)蒙版基于图像的语义,尊重原始物体的语义边界。由于混合边界更接近实际语义边界,因此混合图像接近真实数据分布,使其对训练和预测更有意义。

ClassMix 由于其固有的语义边界考虑,因此适用于与遥感相关的任务。与 CutMix 一样,一致性损失是基于混合图像和混合预测的预测 。关于混合方案,和分别定义为前景和 背景图像, 这意味着 需要剪切和粘贴到其中的一部分 。具体来说,如果 中 有两个以上的类,则预测类的一半将被剪切并粘贴到 。如果 包含两个类,则仅剪切和粘贴非背景类。如果 仅包含 background 类,则将忽略 mix。
3.3. 模型级扰动
3.3.1. 平均教师 (MT)
Mean Teacher [ 26] 最初是为图像级分类任务提出的,该任务通过基于教师模型和学生模型的预测构建一致性损失来执行 SSL(图 3)。机器翻译的关键思想是,与直接使用最终权重相比,连续学生模型的平均值可以表示更准确的模型。该技术已应用于遥感图像语义分割[31,32],并取得了可观的性能。从技术上讲,教师模型的参数是根据公式(8)中给出的学生模型参数的连续平均值计算得出的:
其中 为平滑系数,一般设置为0.99,而 和分别表示训练步骤 中学生模型和 教师模型的参数。

图3.用于 SSL 语义分割的 MT 图示:培训中有一个学生模型和一个教师模型 。学生模型是使用训练数据训练的主要模型。随着训练的进行,教师模型会使用学生模型参数的指数移动平均值进行更新,以便可以根据教师和学生模型的各自预测来建立一致性损失。需要注意的是,教师模型的参数不参与误差反向传播过程,符号“//”表示停止梯度。
直观地说,教师和学生模型应该产生一致的结果,因为它们的参数之间只有很小的差异。因此,教师模型中的伪标签可用于监督学生模型的预测。根据 MT 方案,一致性损失形成为公式 (9):
3.3.2. 交叉伪监督(CPS)
交叉伪监督 [ 51] 是最近提出的一种方法,它使用两个具有相同架构但不同初始化参数的模型,并施加相互监督来执行 SSL(图 4)。这种方法旨在保持两个相似模型之间的一致性,并具有轻微的参数扰动。根据交叉监督操作,在训练过程中建立了两个交叉一致性损失,如公式(10)和(11)。因此,无监督学习损失是用两个交叉一致性损失的总和计算的,如公式(12)所示。该框架包含两个监督损失 和 ,用于两个可优化的可训练子模型。总损耗公式为公式(13):
其中 和 表示具有相同架构 的两个模型的各自参数,并且它们使用不同的值进行初始化。 并 分别表示根据置信概率结果 和 计算得出的独热标签映射(称为伪分割映射)。

图4.用于 SSL 语义分割的 CPS 图示:我们将图像 x 输入到模型 中,然后 得到相应的概率图 和 伪标签 和 。随后,让 监督和监督 ,分别构造两个一致性损失 和 。符号“//”表示停止梯度。
CPS的模型结构稍微复杂一些,但几何对称,可以在子模型之间进行隐式伪监督,而无需设置置信度阈值。请注意,由于需要训练两个子模型,因此其计算工作量会增加。尽管该方法在计算机科学领域两个流行的语义分割数据集(Cityscapes [ 38] 和 PASCAL VOC 2012 [ 52])上取得了出色的性能,但我们仍然期望从遥感应用的角度探索其实际性能。
3.4. 混合扰动
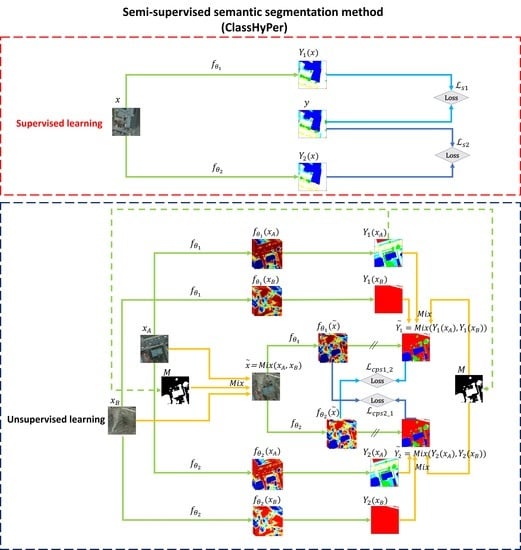
鉴于数据级和模型级扰动各自的优势,我们认为两种方案的结合可能会进一步增强模型能力。因此,为了结合这两种方案的优点,我们通过将 ClassMix 与 CPS 集成,设计了一种基于混合扰动的方法,即 ClassHyPer。具体来说,ClassMix 在生成尊重原始图像中对象语义边界的混合图像方面表现出色,这有助于完成语义分割任务。此外,掩码的多样性拓宽了数据分布的范围,从而增强了模型的泛化能力,缓解了过拟合问题。CPS的优势在于两个方面:一是两个分割网络之间的一致性促使预测决策边界位于低密度区域。二是模型参数的扰动隐式利用伪分割图作为训练信号,让它们相互监督,从而避免了置信阈值确定的棘手过程。此外,这两种方案都可以端到端地轻松嵌入到现有的深度学习模型中,从而降低了模型训练的复杂性和难度。
如图 5 所示,将两个未标记的图像输入两个分割网络,然后根据其中一个伪分割图生成掩码。随后,基于掩码的混合输入和输出用于构建一致性损失。最后,大量具有成本效益的未标记数据能够通过一致性学习来增强模型性能。除此之外,我们还在图 6 中演示了结合 MT 和 ClassMix 的方法,我们在后面的实验中将其用作对比方法。在本节中,通过相关实验验证了ClassHyPer在不同遥感数据集上的有效性和鲁棒性。


4. 实验和结果
4.1. 数据集
为了评估混合扰动框架在遥感图像语义分割中的有效性,我们选择了5个高分辨率遥感基准数据集进行实验。表 1 给出了每个数据集的概述,图 7 显示了这些数据集的一些示例。

图7.(a) DG_Road、(b) Massa_Building、(c) WHU_Building、(d) 波茨坦和 (e) Vaihingen 数据集的示例。每个数据集的左列和右列分别表示图像和相应的地面实况标签。

DeepGlobe Road Extraction Dataset (DG_Road) [ 53]:这是一个 RGB 卫星数据集,用于道路和街道网络提取挑战,将每个像素分类为二进制类别(道路和背景);它包含 6226 张标记的 RGB 卫星图像,在泰国、印度和印度尼西亚上空捕获了 1024 × 1024 像素。在我们的实验中,我们将它们的大小调整为 512 × 512 像素以减少计算,如 [ 32] 所述,因为目标是验证 SSL 的性能,而不是在挑战竞赛中获得最佳分割结果。然后,我们将它们随机分为三个子集,分别用于训练(3735)、验证(623)和测试(1868),比例为60%:10%:30%;
马萨诸塞州建筑数据集 (Massa_Building) [ 54]:该数据集包含波士顿地区的 151 张 RGB 航拍图像,以及来自 OpenStreetMap 的相应建筑多边形作为地面实况。每个图像为 1500 × 1500 像素,空间分辨率为 1 m。我们遵循官方数据拆分(137 个用于训练,4 个用于验证,10 个用于测试),然后使用最近邻插值将它们重新采样到 1536 × 1536 像素,最后将它们裁剪成 512 × 512 像素的补丁,没有重叠。去除部分空白图像后,分别获得1065张、36张和90张标记图像进行训练、验证和测试;
WHU Aerial Building Dataset (WHU_Building) [ 6]:这是一个用于二进制类语义分割(建筑物和背景)的大型航空 RGB 数据集,覆盖了新西兰基督城 450 公里 2 的 220,000 多座建筑物,空间分辨率为 0.3 m。创建者将图像无缝裁剪成 8188 个具有 512 × 512 像素的补丁,然后将它们分成三个子集:4736 个用于训练,1036 个用于验证,2046 个用于测试。该数据集样本量大、标注精度高,已成为遥感界最流行的基于深度学习的建筑物提取基准数据集之一。为了方便训练,我们在实验中遵循了官方的数据拆分方案;
ISPRS Potsdam 2D Semantic Labeling Dataset (Potsdam) [ 39]:该数据集是 ISPRS 语义标注竞赛基准数据集的一个子集,由 38 幅空间分辨率为 0.05 m 的航空真实正射影像和相应的六类地面实况标签(即不透水表面、建筑物、低矮植被、树木、汽车和杂波/背景)组成。每个修补程序的原始大小为 6000 × 6000 像素。虽然 RGB、IRRG、RGBIR 和 DSM 数据是官方提供的,但我们在实验中只使用了三通道 RGB 标记的图像。根据官方建议,我们将它们分为训练、验证和测试子集,分别有 17、7 和 14 张标记图像。由于计算能力有限,原始图像的大小被调整为 3072 × 3072 像素,然后裁剪成 512 × 512 像素的块,没有重叠。结果,我们分别获得了 612、252 和 504 张标记图像用于训练、验证和测试;
ISPRS Vaihingen 2D Semantic Labeling Dataset (Vaihingen) [ 39]:这也是 ISPRS 基准数据集的一个子集,包含 33 个空间分辨率为 0.09 m 的补丁。每个斑块都涉及一个彩色红外正射影像、DSM 和相应的地面实况标签,具有六个类别(与波茨坦数据集相同)。在我们的实验中,我们只使用了彩色红外正射影像和相应的标签。我们还遵循了官方的建议,分别选择了 11、5 和 17 个补丁作为训练集、验证集和测试集。所有补丁被裁剪成 512 × 512 个子补丁。唯一的区别是训练样本被裁剪为256×256重叠,而验证和测试样本没有重叠。最后,分别获取了 692、68 和 249 个子补丁进行训练、验证和测试。
4.2. 实验设置
所有实验均通过 PyTorch 1.9.0 [ 55] 和 CUDA 10.2 在具有 11 G 内存的单个 NVIDIA GeForce RTX 2080Ti GPU 中实现。数据增强采用随机水平和垂直翻转。采用权重衰减为0.0002、动量为0.9的AdamW优化器[56],因为它具有快速收敛的特点。学习率初始化为0.0001,采用单周期学习率策略[57]调整训练中的学习率。为了避免过度拟合,我们采用了早期停止策略,当最大 IoU 在几个时期内没有改善时,该策略会指导训练停止。所有实验的批量大小都设置为 4,以适应 GPU 内存并确保公平比较。
关于 CutMix 中的蒙版生成,我们遵循了 [ 5] 中提出的方案。三个矩形覆盖了图像区域的 50%,具有随机的纵横比和位置来创建蒙版。对于ClassMix的掩码生成,采用了预热策略。具体来说,该模型首先训练了几个 epoch(例如,总训练 epoch 的 1/8),仅使用标记数据,以便生成具有更准确类边界的预测,以便在训练中获得更有意义的掩码。
遵循模型训练中的一般经验法则,我们使用训练集来拟合模型参数,使用验证集来评估模型并确定最佳模型参数,并使用测试集进行最终模型评估。此外,为了进行SSL实验,我们将训练集分成两组,随机抽样整个集合的5%、10%、20%或50%作为标记子集,其余数据作为未标记子集。为了降低随机性,保证结果的可靠性,我们对每个数据集重复了3次随机数据子抽样,并使用评估指标的平均值来评估最终的模型性能。
此外,为了避免完全监督学习方法和半监督学习方法之间的不公平比较,我们遵循了[49]中描述的训练规则。首先,我们将训练样本的总数定义为:
其中 表示总训练周期数,表示每个周期中的迭代次数, 并且是 批处理大小 - 由于 GPU 内存有限,在所有实验中都设置为 4。具体培训规则如下:
- (1)
所有纯监督实验都经过 50 个 epoch 的训练,其中 20 个 epoch 提前停止。 在SSL的上下文中,随着标记数据数量的减少而减少,但为了防止过拟合,我们没有增加 ;- (2)
进行了调整,以确保 与使用所有标记数据的完全监督基线相同。由于SSL实验中的每一批都涉及标记和未标记的数据,因此我们在SSL实验中将“epoch”定义为对未标记的数据进行一次检查,同时标记的子集重复几次以匹配一个epoch内未标记的样本数量;- (3)
根据经验,我们在SSL实验中使用了自适应早期停止策略,以避免折叠训练和过拟合。提前停止的周期按 0.4 × 计算 。
4.3. 基本分割模型
关于语义分割模型,选择了一个简单但经典的FCN模型(图8)作为基础模型架构;将其编码器替换为VGG16的编码器[58],因此我们可以直接使用在ImageNet数据集[59]上训练的VGG16模型参数。该数据集是一个非常大的 1000 类图像识别基准数据集,包含超过 120 万张标记图像。虽然它是为图像级分类而不是像素级语义分割而创建的,但它的预训练模型编码器仍然可以从图像中提取一般特征[20]。通过这种参数TL策略,我们可以加速训练过程,实现更好的模型性能,特别是在标注数据很少的情况下。请注意,本研究中设计的 SSL 框架可以与其他突出的 DL 语义分割架构集成。然而,考虑到我们的目标是评估所提出的SSL方法的有效性,由于实验工作极其耗时,我们只在研究中基于这种模型架构进行了实验(参见第5.1节中的时间效率)。

4.4. 评估指标
通常,像素级语义分割有几个主要的定量评估指标,例如精确率、召回率、F 1 分数和交集 ( )。这些指标与预测中的四个分类条件相关:真阳性 ( )、假阳性 ( )、真阴性 ( ) 和假阴性 ( ),其中 是正确分类的像素,是错误分类的像素,是正确拒绝的像素, 是错误拒绝的像素。
其中,表示整个图像集并集的预测与真值的交集, 取值范围为0-1;即使数据集中的类数量不平衡,它也可以稳健地评估分割结果。例如,在Massa_Building数据集中,非建筑物像素的数量远远多于建筑物像素; 在这种不平衡的分类情况下,仍然可以对检测结果进行鲁棒的测量,这既可以兼顾检测精度,也可以兼顾完整性。因此, 用于在以后的实验中评估模型性能。
4.5. 实验结果
为了全面评估ClassHyPer和其他基于扰动的SSL方法,我们使用纯监督学习方法(Sup)和半监督学习方法(SSL)在多个遥感数据集上对不同比例的标记样本进行了实验。基线表示使用第 4.3 节中介绍的修改后的 FCN 模型的方法。TL表示使用了参数迁移学习策略。具体来说,将VGG 16的预训练参数转移到基线模型中。请注意,TL 策略也应用于所有 SSL 方法。由于二元类数据集(例如DG_Road、Massa_Building和WHU_Building)通常存在类不平衡问题,因此我们只考虑 目标对象(例如道路或建筑物)进行性能评估,而不考虑背景。对于多类数据集(例如波茨坦和Vaihingen),采用均值 ( )进行精度评估,即所有类的平均值 。为了简化表达式,我们稍后使用 统一表示精度,无论数据集是否用于二进制类分割。
4.5.1. DG_Road
DG_Road是基于卫星影像的道路提取数据集,分为两类:道路和背景。从表 2 所示的定量结果可以看出,TL 和 SSL 都可以在基线上提高模型性能。准确性提升相对较高,尤其是在使用很少的标记数据时。当使用 5% 的标记数据(186 张标记图像)时,TL 和最佳 SSL 方法 (CPS+CutMix) 将平均值 分别从 46.65% 提高到 52.88% 和 58.88%,这在语义分割任务中是一个巨大的改进。此外,数据级扰动方法(CutMix 和 ClassMix)可以显著提高模型的准确性,而不是 TL,而且标签很少。相比之下,模型级扰动方法(MT 和 CPS)不能做同样的事情,尽管它们的精度高于基线。基于CPS的混合扰动方法具有更好的性能,但基于MT的混合扰动方法甚至不能单独胜过数据级扰动方法。在基于CPS的混合方法中,ClassHyPer的准确率略低于CPS+CutMix。这可能是由于基于ClassMix的方法不适合道路提取,因为具有线性特征的道路目标分布极其稀疏。此外,值得注意的是,在这个数据集上,我们的模型的性能比最近的 RanPaste 方法 [ 32] 要好得多。例如,ClassHyPer 在 373 个标签中获得了约 60% 的收益,而 RanPaste 在 400 个标签中获得了 54.24% 的收益。从图 9 中可以看出,可视化结果也与定量分析密切相关。 与其他方法相比,CPS+CutMix的假阴性(黄色)和假阳性(红色)像素最少。


4.5.2. Massa_Building
Massa_Building是一个空间分辨率为1 m的航空影像建筑提取数据集,涉及建筑和背景两类。如表3所示,定量结果与DG_Road数据集的结果相似。基线在标记数据的每个比例上具有最低的准确性,而 TL 和 SSL 可以使用很少的标签来提高准确性。当使用 5% 的标记数据(53 张标记图像)时,TL 和最佳 SSL 方法 (ClassHyPer) 分别从 57.35% 显着增加到 65.05% 和 69.85%。数据级扰动方法可以比模型级扰动方法获得更好的结果。此外,使用100%标记数据的TL方法具有最佳性能(73.15%),而使用50%标记数据的ClassHyPer(72.31%)的准确率也不甘落后。但是,与 DG_Road 数据集的结果不同,ClassMix 在此数据集上比 CutMix 更有效。ClassHyPer在所有比例子集中都获得了最佳的精度,表明场景的多样性的增加和对类边界信息的考虑可以激发SSL算法的潜力。从视觉上看,图 10 还展示了 SSL 方法在仅 5% 标签的数据集上的优越性,其中 ClassHyPer 实现了最佳的提取结果(绿色像素更多,黄色和红色像素更少)。

4.5.3. WHU_Building
WHU_Building是一个空间分辨率为0.3 m的大型建筑物提取数据集,包含两个类(建筑物和背景)。定量结果如表4所示。该数据集可以达到近90%, 并且在不同子采样之间的多次重复实验中存在相对较小的标准差,代表了该数据集的鲁棒性和高质量。当使用5%的标记数据(236个标签)时,与基线相比, TL和ClassHyPer分别从81.65%提高到86.37%和88.37%。相对而言,基于 CPS 的方法比其他方法获得更好的性能。令人印象深刻的是,仅使用5%的标记数据,基于CPS的方法就可以获得接近TL在100%标记下实现的高精度。由于其固有的高标记准确性,该数据集对训练数据量不敏感。因此,CutMix 和 ClassMix 取得了相似的结果,因此我们无法发现它们之间的显着差异。此外,当使用4736个标签时, (89.64%)可以优于一些报道的方法,例如SiU-Net [ 6]和SRI-Net [ 60],展示了我们改进的FCN模型的可用性和有效性。同样,从图 11 所示的可视化结果可以看出,由于这些 SSL 方法的精度相对较高,因此很难分辨出这些 SSL 方法之间的视觉差异。

4.5.4. 波茨坦
与前三个数据集不同,波茨坦数据集是为多类语义分割而创建的;此外,它具有极高的空间分辨率,因此场景复杂度明显大于以前的数据集。我们希望使用这个数据集来验证 ClassHyPer 在多类分割上的适用性。从表 5 中可以看出,ClassHyPer 在所有数据比例上都优于其他基于扰动的方法。当使用 5% 的标记数据(31 个标签)时,ClassHyPer 的准确率比 TL 有显著提高,从 63.09% 增加到 67.13%。但是,当标签比例增加 20% 以上时,与 TL 相比,SSL 方法并不能显着提高准确性。此外,无论是否与数据级扰动相结合,MT 对模型性能都没有帮助。图 12 显示了基于 5% 标签的可视化结果;我们可以看到,很难将所有像素分为六类,因为某些类别可能具有相对同质的特征。例如,由于低矮植被和树木的特征相似,因此在实践中区分低矮植被是具有挑战性的。但是,ClassHyPer 仍然可以提高准确性并实现视觉上更流畅的预测。


图 12.使用波茨坦数据集中 5% 标签的语义分割的可视化结果。从(c)到(),不同的颜色代表具有不同类别的像素,即白色(不透水表面)、蓝色(建筑物)、青色(低植被)、绿色(树木)、黄色(汽车)、红色(杂物/背景)。
4.5.5. Vaihingen
尽管 Vaihingen 数据集也像波茨坦数据集一样有六个类,但与前四个数据集相比,它由彩色红外图像而不是 RGB 图像组成。如表 6 所示,ClassHyPer 可以在所有数据分区上实现最佳精度。所有SSL方法都可以在极少的标签下提高基线上的模型性能,证明了它们在三波段彩色红外图像上用于多类语义分割的适用性。最有趣的结果是,具有50%标签 (68.08%)的ClassHyPer甚至优于具有100%标签的纯监督方法(67.39%),揭示了SSL方法的巨大潜力。基于5%标签的可视化结果(图13)显示,真值标签可能存在一些意外错误。例如,在图13(a1)中,被橙色矩形包围的区域包含一些不透水的表面像素,但我们无法从地面实况标签(b1)中找到它们。此外,图13(a2)中的矩形显示了一个表面不透水的区域,而通过人工检查,它实际上是低矮的植被。为了更清晰地进行比较,图 14 提供了图 13 中橙色矩形包围的区域的放大可视化。令人印象深刻的是,SSL 方法能够识别这些区域,这也证明了 DL 方法的强大功能和 SSL 范式的卓越性能,即使标记的训练数据数量有限。

图 13.使用来自 Vaihingen 数据集的 5% 标记数据进行语义分割的可视化结果。从(c)到(),不同的颜色代表具有不同类别的像素,即白色(不透水表面)、蓝色(建筑物)、青色(低植被)、绿色(树木)、黄色(汽车)、红色(杂物/背景)。

图 14.图 13 中被橙色矩形包围的区域的放大结果。从(c)到(),不同的颜色代表具有不同类别的像素,即白色(不透水表面)、蓝色(建筑物)、青色(低植被)、绿色(树木)、黄色(汽车)、红色(杂物/背景)。
4.6. 数据集之间的整体比较
4.6.1. ClassHyPer 与不同比例标签的比较
为了分析和比较所提方法在不同数据集之间的结果,我们在表7中展示了使用ClassHyPer的结果的准确性。
如表1和表7所示,这5个数据集在训练标签数量、空间分辨率、类别、训练精度等多个维度上都具有异构性。总体而言,除WHU_Building数据集外,其他数据集的准确率随着训练标签数量的增加而逐渐提高。例如,如果将具有 100% 标签的 TL 的准确率视为准确率的上限,则每个数据集的 50% 标签接近上限。有趣的是,具有 50% 标签的 Vaihingen 数据集的准确性甚至超过了上限,显示了所提方法的强大能力。此外,当仅使用 5% 的训练标签时,ClassHyPer 可以达到与 100% 标签相比相当高的准确性,如表 11 所示。
此外,我们发现在不同的数据集上实现了不同程度的准确性。具体来说,WHU_Building数据集具有最多标记的训练图像(4736),并且在所有比例下都达到了最高的准确性。通过查看WHU_Building数据,我们可以看到它具有非常高的空间分辨率(0.3 m),使其能够更准确地描绘建筑物边界并具有更高的标注精度。该数据集的创建者还强调,创建数据集大约需要六个月的时间,严格的人工检查确保了其最终标注的准确性。此外,该数据集是为二元分类而创建的,降低了其任务复杂性并实现了相对较高的准确性。
尽管DG_Road数据集使用了 3735 个标签进行训练,但其准确性在所有数据集中都是最低的。对此有两种可能的解释:(1)其标记精度受到其相对较低的空间分辨率和异质成像质量的限制。例如,由于该数据集由来自具有不同特征的多颗卫星的图像组成,因此即使对于人类来说,也很难标记某些特定区域。(2)该数据集的类不平衡问题严重,对最终模型性能有显著影响。例如,该数据集中的道路像素仅占所有训练标签的 4.21%,如表 8 所示。
Massa_Building数据集中的建筑物标签直接从OpenStreetMap数据库中引用,无需人工校正,涉及许多意外错误。同时,在DG_Road数据集中,其建筑像素占比(15.53%)大于道路像素占比。因此,我们可以获得在WHU_Building和DG_Road数据集之间占据中间地带的精度。
波茨坦数据集和Vaihingen数据集都具有极高的空间分辨率,因此包含更多的细节和噪声信息。由于不同类别之间存在严重的不平衡类问题,多类分类任务更加困难。如表 8 所示,这两个数据集的汽车像素数量有限,分别仅占所有训练像素的 1.69% 和 1.26%,因此很难对如此罕见的类别进行分类。此外,正如我们之前提到的,类越多,不同类别具有相似特征的可能性就越大。例如,由于低矮植被和树木具有相似的光谱特征,即使使用许多训练样本,也很难区分它们。因此,这两个数据集在所有比例上的准确率仅为63%至73%,尽管波茨坦的准确率高于Vaihingen。
4.6.2. 5%标签不同方法的比较
此外,为了进一步比较上述方法与有限数量的标签,我们总结了基于5%标签的所有五个数据集的准确率结果,如表9所示。根据结果,很明显,数据级扰动方法(即 CutMix 和 ClassMix)可以比模型级扰动方法(即 MT 和 CPS)获得更大的精度改进。对于数据级扰动方法,除DG_Road外,ClassMix在所有数据集上均优于CutMix,这证明了ClassMix在道路提取以外的建筑物提取和土地覆被分类中的适用性。对于模型级的扰动方法,CPS在所有数据集上都优于MT。尽管一些研究[ 31, 32]仍然在他们的方法中使用了机器翻译,但从模型扰动的角度来看,CPS已经成为一种新颖且具有竞争力的SSL范式。事实上,CPS的成功不仅归功于其训练参数数量的增加,还归功于通过鼓励相互监督的多模型组合策略。关于混合流水线,基于MT的方法的性能无法与基于CPS的方法竞争。具体而言,基于CPS的混合方案在所有数据集上都能产生最佳性能,其中ClassHyPer在3个数据集上取得了最佳的准确率,而CPS+CutMix也具有相当的准确率。
通过对涉及不同任务和特征的五个数据集进行整体比较,ClassHyPer 能够应用于标记训练数据很少的场景。此外,基于CPS和基于掩模的数据增强的一致性正则化的混合扰动方法可以实现相对较高的精度。我们应该根据相应的数据及其在具体应用中的特点来选择合适的方法。无论如何,在标签数量有限的情况下,使用未标记的数据可能更具成本效益。
5. 讨论
本节进一步分析和讨论了实验结果,包括所提方法的时间效率和训练中的标签冗余。
5.1. 时间效率
为了分析所提出的方法的时间效率,我们选择了两个大型数据集(DG_Road和WHU_Building)。这两个数据集包含超过 3700 个用于训练的标记数据,当使用大量未标记数据时,它们可以很好地代表 SSL 方法的时间消耗。
如表10所示,对于DG_Road数据集,当我们使用5%的标记数据进行训练时,TL用了0.37 h才达到52.88%, 而ClassHyPer用了5.2 h就达到了57.92%。 TL方法在时间方面显然更有效;但是,为了达到与具有 5% 标签的 ClassHyPer 相同的准确度水平,TL 中需要多 ~10% 的标记数据。事实上,根据我们通常的经验,在此数据集中创建 10% 以上的标签(~370 个标签)将花费比 5 小时更多的时间。这同样适用于WHU_Building数据集;虽然ClassHyPer的训练时间更长(6.64 h),但它可以用更少的标签获得更高的准确性,从而节省更多的标签工作时间。此外,我们发现,当标记数据的比例从5%增加到10%时,WHU_Building数据集的准确性并没有显着提高。这可能是因为数据集的高质量使得准确性对标签大小的小幅增加不敏感。
在分析时间效率时,我们发现 ClassHyPer 需要更长的训练时间。但是,它可以从大量未标记的数据中学习,并显着提高分割精度。特别是,当手头只有有限数量的标记数据时,这种方法可以加速问题的解决。
5.2. 标签冗余
基于上述分析,所提出的方法在极少标签的情况下表现出很高的准确性。与此同时,我们发现训练准确性并没有随着标记数据数量的增加而线性提高。如果将使用 TL 进行全监督学习的 100% 标记数据的结果作为准确率的上限,我们可以计算 出从 ClassHyPer (SSL ) 到上限 (Sup ) 的比率。表 11 显示了所有数据集的比较结果。值得注意的是,ClassHyPer 使用 5% 标签获得的准确率与使用 100% 标签的纯监督方法获得的准确率之比超过 89%。一方面,该统计强调了所提出的方法如何通过利用大量未标记的数据来显着增强深度学习模型的能力,这对于SSL在遥感应用中的应用具有可喜性。另一方面,基于剩余的 95% 的标记数据,准确率仅提高了不到 10%,这意味着训练数据中存在许多冗余标签。例如,在仅使用5%标签的WHU_Building数据集上达到了98.58%的 比率,这非常接近精度的上限。此外,我们还观察到标签中存在一些意想不到的错误,这可能是影响最终准确性的另一个因素。因此,用很少但有效的标签来提高模型性能是一个值得未来研究的有趣课题。
6. 结论
本研究旨在缓解遥感语义分割应用中的标签稀缺问题,从数据级和模型级扰动的角度,综合分析了几种基于一致性正则化的先进SSL方法。然后,引入了一种基于ClassMix的端到端混合扰动SSL方法,即ClassHyPer,以在面对有限数量的注释时提高模型的能力。在5个数据集上的实验结果表明,所提方法通过结合5%的标记数据和其余95%的未标记数据,能够在其中3个数据集上实现最佳性能;同时,在其他两个数据集上获得了相对较高的准确度。此外,这种方法不需要设置置信度阈值,可以很容易地与现有的深度学习模型配对。尽管训练需要更多时间,但该模型可以节省花费在标记工作上的时间。
通过各种实验,我们注意到训练中存在许多冗余标签。因此,我们将进一步探讨如何减少标签冗余并提高标签工作的有效性,例如,通过纳入主动学习方案。此外,我们只对三个波段(R-G-B或IR-R-G)的遥感影像进行了实验,因此未来仍需要对多光谱影像(三个波段以上)进行更多的研究。为此,本研究中使用的传统参数迁移学习管道需要针对三个以上波段的多光谱图像进行相应的调整。此外,该方法可以扩展到特定的遥感应用,例如灾害和农业监测,以在实践中挖掘其巨大潜力。
作者贡献
Y.H.为方法的设计和实施做出了贡献,进行了实验,并撰写和修改了论文;J.W.和C.L.对方法的讨论做出了贡献,并修订了文件;B.S.和X.Z.为论文的编辑和形式分析做出了贡献。所有作者均已阅读并同意该稿件的已发表版本。
资金
这项研究由加拿大自然科学与工程研究委员会(NSERC)授予王金飞博士的发现基金(资助号RGPIN-2016-04741)和授予何永军的西部研究生研究奖学金(WGRS)资助。
机构审查委员会声明
不適用。
知情同意书
不適用。
数据可用性声明
本研究中使用的数据集都是公开的。
确认
我们感谢地理信息技术与应用(GITA)实验室为实验提供计算资源。作者还要感谢提供公共数据集的团体。此外,作者感谢编辑和匿名审稿人的宝贵意见和建议,这些意见和建议有助于显着改进这项工作。
利益冲突
作者声明没有利益冲突。
引用
廖,C.;王杰;谢庆;巴兹,A.A.;黄彦;尚先生;基于一维卷积神经网络的多时相RADARSAT-2和VENμS数据协同使用作物分类。遥感 2020, 12, 832.[ 谷歌学术搜索][ 交叉参考][ 绿色版]
郑志;王杰;单,B.;他,Y.;廖,C.;高玲;杨,S.基于迁移学习的烧伤严重程度映射的新模型。遥感 2020, 12, 708.[ 谷歌学术搜索][ 交叉参考][ 绿色版]
科塔里迪斯,I.;Lazaridou, M. 遥感图像分割进展:荟萃分析。ISPRS J. 摄影图。遥感 2021, 173, 309–322.[ 谷歌学术搜索][ 交叉参考]
朱旭X.;图亚,D.;牟,L.;夏,G.S.;张玲玲;徐峰;Fraundorfer, F. 遥感中的深度学习:综合回顾和资源列表。IEEE地球科学。遥感杂志 2017, 5, 8–36.[ 谷歌学术搜索][ 交叉参考][ 绿色版]
法语,G.;莱恩,S.;艾拉,T.;麦凯维奇,M.;Finlayson, G. 半监督语义分割需要强而多样的扰动。2020 年 9 月 7 日至 10 日,第 31 届英国机器视觉虚拟会议论文集,英国虚拟活动。[ 谷歌学术搜索]
姬,S.;魏,S.;Lu, M. 从开放的航空和卫星图像数据集中提取多源建筑物的全卷积网络。IEEE译. Geosci.遥感 2019, 57, 574–586.[ 谷歌学术搜索][ 交叉参考]
罗,S.;李H.;Shen, H. 基于新型航空阴影图像数据集的深度监督卷积神经网络进行阴影检测。ISPRS J. 摄影图。遥感 2020, 167, 443–457.[ 谷歌学术搜索][ 交叉参考]
萨哈,S.;牟,L.;邱,C.;朱旭X.;博沃洛,F.;Bruzzone, L. 多时相高分辨率图像的无监督深度关节分割。IEEE译. Geosci.遥感 2020, 58, 8780–8792.[ 谷歌学术搜索][ 交叉参考]
萨哈,S.;埃贝尔,P.;Zhu, X.X. 自监督多传感器变化检测。IEEE译. Geosci.遥感 2021, 60, 1–10.[ 谷歌学术搜索][ 交叉参考]
Anantrasirichai,N.;比格斯,J.;白化病,F.;公牛,D.使用合成数据集从卫星图像中检测火山变形的深度学习方法。远程传感器环境。2019, 230, 111179.[ 谷歌学术搜索][ 交叉参考][ 绿色版]
拜尔,G.;德切姆斯,A.;施密特,M.;Yokoya, N. 从土地覆盖图和辅助栅格数据合成光学和 SAR 影像。IEEE译. Geosci.遥感 2022, 60, 1–12.[ 谷歌学术搜索][ 交叉参考]
凯撒,P.;韦格纳,法学博士;卢奇,A.;贾吉,M.;霍夫曼,T.;Schindler, K. 从在线地图中学习航空图像分割。IEEE译. Geosci.遥感 2017, 55, 6054–6068.[ 谷歌学术搜索][ 交叉参考]
吉拉德,N.;查皮亚特,G.;Tarabalka, Y. 在没有完美地面实况数据的情况下校正未对齐的地籍图的嘈杂监督。IGARSS 2019—2019 IEEE国际地球科学与遥感研讨会论文集,日本横滨,2019年7月28日至8月2日;第10103-10106页。[ 谷歌学术搜索]
胡, X.;李婷婷;周, T.;刘彦;Peng, Y. 基于Transformer的高光谱图像分类对比学习.应用科学 2021, 11, 8670.[ 谷歌学术搜索][ 交叉参考]- Kang, J.; Wang, Z.; Zhu, R.; Sun, X.; Fernandez-Beltran, R.; Plaza, A. PiCoCo: Pixelwise Contrast and Consistency Learning for Semisupervised Building Footprint Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10548–10559. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer Learning Using Computational Intelligence: A Survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep Visual Domain Adaptation: A Survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-Cover Classification with High-Resolution Remote Sensing Images Using Transferable Deep Models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Xie, M.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Transfer Learning from Deep Features for Remote Sensing and Poverty Mapping. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3929–3935. [Google Scholar]
- Majd, R.D.; Momeni, M.; Moallem, P. Transferable Object-Based Framework Based on Deep Convolutional Neural Networks for Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2627–2635. [Google Scholar] [CrossRef]
- Chen, J.; He, F.; Zhang, Y.; Sun, G.; Deng, M. SPMF-Net: Weakly Supervised Building Segmentation by Combining Superpixel Pooling and Multi-Scale Feature Fusion. Remote Sens. 2020, 12, 1049. [Google Scholar] [CrossRef] [Green Version]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly Supervised Feature-Fusion Network for Binary Segmentation in Remote Sensing Image. Remote Sens. 2018, 10, 1970. [Google Scholar] [CrossRef] [Green Version]
- van Engelen, J.E.; Hoos, H.H. A Survey on Semi-Supervised Learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results. In Proceedings of the 31 Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Sohn, K.; Berthelot, D.; Li, C.-L.; Zhang, Z.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Zhang, H.; Raffel, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 596–608. [Google Scholar]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A Semi-Supervised Generative Framework with Deep Learning Features for High-Resolution Remote Sensing Image Scene Classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Hua, Y.; Marcos, D.; Mou, L.; Zhu, X.X.; Tuia, D. Semantic Segmentation of Remote Sensing Images With Sparse Annotations. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, J.; Ding, C.H.Q.; Chen, S.; He, C.; Luo, B. Semi-Supervised Remote Sensing Image Semantic Segmentation via Consistency Regularization and Average Update of Pseudo-Label. Remote Sens. 2020, 12, 3603. [Google Scholar] [CrossRef]
- Wang, J.-X.; Chen, S.-B.; Ding, C.H.Q.; Tang, J.; Luo, B. RanPaste: Paste Consistency and Pseudo Label for Semisupervised Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- French, G.; Oliver, A.; Salimans, T. Milking CowMask for Semi-Supervised Image Classification. arXiv 2020, arXiv:2003.12022. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Zheng, X.; Huan, L.; Xia, G.-S.; Gong, J. Parsing Very High Resolution Urban Scene Images by Learning Deep ConvNets with Edge-Aware Loss. ISPRS J. Photogramm. Remote Sens. 2020, 170, 15–28. [Google Scholar] [CrossRef]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks. In Proceedings of the IEEE 20th International Workshop on Multimedia Signal Processing, Vancouver, BC, Canada, 29–31 August 2018. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS Benchmark on Urban Object Classification and 3D Building Reconstruction. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Melbourne, Australia, 25 August–1 September 2012; Volume I-3, pp. 293–298. [Google Scholar]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked Autoencoders Driven by Semi-Supervised Learning for Building Extraction from near Infrared Remote Sensing Imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Lee, D.-H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the Workshop on Challenges in Representation Learning, Daegu, Korea, 3–7 November 2013; Volume 3, p. 896. [Google Scholar]
- Li, F.; Clausi, D.A.; Xu, L.; Wong, A. ST-IRGS: A Region-Based Self-Training Algorithm Applied to Hyperspectral Image Classification and Segmentation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3–16. [Google Scholar] [CrossRef]
- Oliver, A.; Odena, A.; Raffel, C.; Cubuk, E.D.; Goodfellow, I.J. Realistic Evaluation of Deep Semi-Supervised Learning Algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 3239–3250. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Olsson, V.; Tranheden, W.; Pinto, J.; Svensson, L. ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1368–1377. [Google Scholar]
- Chen, Y.; Ouyang, X.; Zhu, K.; Agam, G. ComplexMix: Semi-Supervised Semantic Segmentation Via Mask-Based Data Augmentation. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2264–2268. [Google Scholar]
- Ke, Z.; Qiu, D.; Li, K.; Yan, Q.; Lau, R.W.H. Guided Collaborative Training for Pixel-Wise Semi-Supervised Learning. In Proceedings of the 16th IEEE European Conference Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 429–445. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-Supervised Semantic Segmentation With Cross-Consistency Training. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12671–12681. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation With Cross Pseudo Supervision. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Virtual, 19–25 June 2021; pp. 2613–2622. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- PyTorch: An Python-Based Open Source Machine Learning Framework Based on the Torch Library. Available online: https://pytorch.org/get-started/locally/ (accessed on 5 November 2021).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 464–472. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building Footprint Extraction from High-Resolution Images via Spatial Residual Inception Convolutional Neural Network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Illustration of CutMix for SSL semantic segmentation: and are two unlabeled images, and is a DL model for semantic segmentation. We input and to the model and obtain the respective predictions and , then mix them based on a mask and achieve a mixed prediction . At the same time, we mix and into based on the same mask , and feed it to the model to get the predictions ). Finally, the consistency loss can be calculated in terms of the differences between ) and .

Figure 2.
Illustration of ClassMix for SSL semantic segmentation. The only difference from CutMix is that the mask is generated by the prediction of instead of a random combination of rectangular areas.

Figure 3.
Illustration of MT for SSL semantic segmentation: There is a student model and a teacher model in training. The student model is the main model trained with the training data. As the training goes on, the teacher model is updated with an exponential moving average of the student model’s parameters, so that a consistency loss can be established based on the respective predictions from the teacher and student models. Note that the parameters of the teacher model do not take part in the process of error backpropagation, and the symbol “//” signifies the stop-gradient.

Figure 4.
Illustration of CPS for SSL semantic segmentation: We input image x into the model and , then get the corresponding probability maps and and pseudo-labels and . Subsequently, let supervise and supervise , constructing two consistency losses and , respectively. The symbol “//” signifies the stop-gradient.

Figure 5.
Illustration of the ClassHyPer approach for SSL semantic segmentation.

Figure 6.
Illustration of the hybrid of MT and ClassMix for SSL semantic segmentation.

Figure 7.
Examples of the (a) DG_Road, (b) Massa_Building, (c) WHU_Building, (d) Potsdam, and (e) Vaihingen datasets. The left and right columns of each dataset denote the images and corresponding ground-truth labels, respectively.

Figure 8.
The architecture of the modified FCN model.

Figure 9.
Visualization results of semantic segmentation using 5% labels from the DG_Road dataset. From (c) to (l), green, yellow, and red color true positive, false negative, and false positive pixels, respectively.


Figure 10.
Visualization results of semantic segmentation using 5% labels from the Massa_Building dataset. From (c) to (l), green, yellow, and red represent true positive, false negative, and false positive pixels, respectively.

Figure 11.
Visualization results of semantic segmentation using 5% labels from the WHU_Building dataset. From (c) to (l), green, yellow, and red represent true positive, false negative, and false positive pixels, respectively.

Figure 12.
Visualization results of semantic segmentation using 5% labels from the Potsdam dataset. From (c) to (l), the different colors represent the pixels with different categories, i.e., white (impervious surfaces), blue (building), cyan (low vegetation), green (tree), yellow (car), red (clutter/background).


Figure 13.
Visualization results of semantic segmentation using 5% labeled data from the Vaihingen dataset. From (c) to (l), the different colors represent the pixels with different categories, i.e., white (impervious surfaces), blue (building), cyan (low vegetation), green (tree), yellow (car), red (clutter/background).

Figure 14.
Enlarged results of the area surrounded by the orange rectangle in Figure 13. From (c) to (l), the different colors represent the pixels with different categories, i.e., white (impervious surfaces), blue (building), cyan (low vegetation), green (tree), yellow (car), red (clutter/background).

Table 1.
Overview of the datasets used in the experiments.
| Dataset | Labeled Images | Split (Train:Val:Test) | Classes | Size (Pixels) | Resolution (m) | Bands | Data Source |
|---|---|---|---|---|---|---|---|
| DG_Road | 6226 | 3735:623:1868 | 2 | 512 × 512 | 1 | R-G-B | Satellite |
| Massa_Building | 1191 | 1065:36:90 | 2 | 512 × 512 | 1 | R-G-B | Aerial |
| WHU_Building | 8188 | 4736:1036:2416 | 2 | 512 × 512 | 0.3 | R-G-B | Aerial |
| Potsdam | 1368 | 612:252:504 | 6 | 512 × 512 | 0.1 | R-G-B | Aerial |
| Vaihingen | 1009 | 692:68:249 | 6 | 512 × 512 | 0.09 | IR-R-G | Aerial |
Table 2.
Accuracy (, %) comparison of different methods on the DG_Road dataset, where the values in bold are the best for each proportion.
| Method | 5% (186) | 10% (373) | 20% (747) | 50% (1867) | 100% (3735) | |
|---|---|---|---|---|---|---|
| Sup | Baseline | 46.65 ± 0.54 | 50.72 ± 0.83 | 55.80 ± 0.27 | 60.15 ± 0.25 | 62.97 ± 0.07 |
| TL | 52.88 ± 0.39 | 56.76 ± 0.11 | 59.34 ± 0.25 | 62.49 ± 0.21 | 64.73 ± 0.38 | |
| SSL | CutMix | 55.63 ± 0.33 | 58.33 ± 0.33 | 60.62 ± 0.11 | 62.52 ± 0.27 | |
| ClassMix | 55.06 ± 0.49 | 58.05 ± 0.42 | 59.96 ± 0.26 | 61.85 ± 0.02 | ||
| MT | 51.70 ± 0.87 | 54.66 ± 0.68 | 58.01 ± 0.66 | 61.60 ± 0.13 | ||
| MT+CutMix | 55.85 ± 0.47 | 58.74 ± 0.24 | 60.75 ± 0.07 | 62.10 ± 0.13 | ||
| MT+ClassMix | 54.23 ± 0.60 | 57.50 ± 0.83 | 59.87 ± 0.20 | 60.75 ± 0.36 | ||
| CPS | 52.10 ± 1.16 | 56.77 ± 1.00 | 59.27 ± 0.60 | 62.00 ± 0.12 | ||
| CPS+CutMix | 58.88 ± 0.46 | 60.53 ± 0.48 | 61.77 ± 0.18 | 63.19 ± 0.27 | ||
| ClassHyPer | 57.92 ± 0.26 | 60.03 ± 0.28 | 61.14 ± 0.13 | 62.56 ± 0.09 | ||
Table 3.
Accuracy (, %) comparison of different methods on the Massa_Building dataset, where the values in bold are the best.
| Method | 5% (53) | 10% (106) | 20% (212) | 50% (532) | 100% (1065) | |
|---|---|---|---|---|---|---|
| Sup | Baseline | 57.35 ± 1.31 | 63.60 ± 0.75 | 65.71 ± 0.06 | 69.51 ± 0.28 | 71.73 ± 0.28 |
| TL | 65.05 ± 0.98 | 68.21 ± 0.32 | 69.78 ± 0.36 | 71.48 ± 0.57 | 73.15 ± 0.12 | |
| SSL | CutMix | 66.32 ± 1.49 | 70.07 ± 0.83 | 70.98 ± 0.61 | 71.67 ± 0.37 | |
| ClassMix | 68.98 ± 0.40 | 69.94 ± 0.77 | 70.60 ± 0.38 | 71.39 ± 1.21 | ||
| MT | 63.27 ± 2.36 | 67.35 ± 0.68 | 69.64 ± 0.86 | 71.18 ± 0.87 | ||
| MT+CutMix | 66.54 ± 1.52 | 70.05 ± 0.86 | 70.73 ± 0.39 | 72.18 ± 0.45 | ||
| MT+ClassMix | 67.98 ± 1.38 | 70.35 ± 0.03 | 70.79 ± 0.57 | 71.82 ± 0.49 | ||
| CPS | 66.75 ± 0.64 | 69.17 ± 1.05 | 70.54 ± 0.54 | 70.84 ± 0.40 | ||
| CPS+CutMix | 69.03 ± 1.26 | 71.08 ± 0.55 | 71.77 ± 0.34 | 71.92 ± 0.57 | ||
| ClassHyPer | 69.85 ± 0.25 | 71.62 ± 0.51 | 72.17 ± 0.47 | 72.31 ± 0.38 | ||
Table 4.
Accuracy (, %) comparison of different methods on the WHU_Building dataset, where the values in bold are the best.
| Method | 5% (236) | 10% (473) | 20% (947) | 50% (2368) | 100% (4736) | |
|---|---|---|---|---|---|---|
| Sup | Baseline | 81.65 ± 0.52 | 84.48 ± 0.08 | 86.71 ± 0.35 | 88.48 ± 0.35 | 89.40 ± 0.06 |
| TL | 86.37 ± 0.27 | 86.46 ± 0.53 | 88.15 ± 0.35 | 89.49 ± 0.34 | 89.64 ± 0.04 | |
| SSL | CutMix | 87.38 ± 0.24 | 87.87 ± 0.30 | 88.63 ± 0.26 | 89.16 ± 0.29 | |
| ClassMix | 87.54 ± 0.22 | 88.16 ± 0.31 | 88.68 ± 0.15 | 89.17 ± 0.20 | ||
| MT | 87.37 ± 0.51 | 87.67 ± 0.46 | 88.78 ± 0.30 | 89.31 ± 0.21 | ||
| MT+CutMix | 86.98 ± 0.38 | 88.33 ± 0.17 | 88.84 ± 0.37 | 89.36 ± 0.15 | ||
| MT+ClassMix | 87.22 ± 0.05 | 88.08 ± 0.13 | 88.62 ± 0.10 | 88.71 ± 0.13 | ||
| CPS | 88.44 ± 0.11 | 88.75 ± 0.57 | 89.17 ± 0.08 | 89.50 ± 0.07 | ||
| CPS+CutMix | 88.25 ± 0.28 | 88.79 ± 0.12 | 89.14 ± 0.19 | 89.53 ± 0.33 | ||
| ClassHyPer | 88.37 ± 0.07 | 88.98 ± 0.19 | 89.30 ± 0.16 | 89.44 ± 0.21 | ||
Table 5.
Accuracy (, %) comparison of different methods on the Potsdam dataset, where the values in bold are the best.
| Method | 5% (31) | 10% (61) | 20% (122) | 50% (306) | 100% (612) | |
|---|---|---|---|---|---|---|
| Sup | Baseline | 46.63 ± 0.98 | 50.31 ± 1.91 | 57.01 ± 0.28 | 64.34 ± 0.31 | 68.86 ± 0.12 |
| TL | 63.09 ± 0.85 | 66.41 ± 0.42 | 70.23 ± 0.26 | 71.65 ± 0.33 | 73.49 ± 0.36 | |
| SSL | CutMix | 65.45 ± 0.25 | 67.54 ± 0.80 | 70.14 ± 0.58 | 71.51 ± 0.15 | |
| ClassMix | 65.62 ± 0.91 | 67.89 ± 0.55 | 70.42 ± 0.34 | 71.73 ± 0.27 | ||
| MT | 61.84 ± 0.82 | 63.9 ± 0.73 | 68.02 ± 0.83 | 70.61 ± 0.33 | ||
| MT+CutMix | 61.38 ± 0.79 | 65.59 ± 0.67 | 68.49 ± 0.94 | 71.06 ± 0.31 | ||
| MT+ClassMix | 64.83 ± 0.72 | 66.38 ± 0.93 | 69.11 ± 0.38 | 70.51 ± 0.26 | ||
| CPS | 62.72 ± 0.89 | 65.48 ± 0.23 | 70.09 ± 0.50 | 71.05 ± 0.41 | ||
| CPS+CutMix | 66.27 ± 0.69 | 68.17 ± 0.55 | 70.28 ± 0.31 | 71.75 ± 0.65 | ||
| ClassHyPer | 67.13 ± 0.40 | 68.63 ± 0.60 | 70.54 ± 0.30 | 71.87 ± 0.23 | ||
Table 6.
Accuracy (, %) comparison of different methods on the Vaihingen dataset, where the values in bold are the best.
| Method | 5% (34) | 10% (69) | 20% (138) | 50% (346) | 100% (692) | |
|---|---|---|---|---|---|---|
| Sup | Baseline | 44.92 ± 0.86 | 48.54 ± 0.8 | 50.15 ± 0.26 | 55.47 ± 1.03 | 61.63 ± 0.56 |
| TL | 55.27 ± 0.93 | 59.28 ± 1.56 | 60.98 ± 0.91 | 65.81 ± 0.10 | 67.39 ± 0.49 | |
| SSL | CutMix | 58.86 ± 1.71 | 62.87 ± 1.22 | 64.61 ± 1.37 | 65.81 ± 1.59 | |
| ClassMix | 60.33 ± 0.83 | 65.19 ± 1.55 | 66.39 ± 0.49 | 66.82 ± 0.65 | ||
| MT | 59.46 ± 0.87 | 62.46 ± 1.58 | 64.85 ± 2.84 | 66.33 ± 0.40 | ||
| MT+CutMix | 60.46 ± 1.51 | 64.85 ± 1.14 | 65.35 ± 1.27 | 66.63 ± 1.32 | ||
| MT+ClassMix | 60.57 ± 1.40 | 64.21 ± 1.15 | 65.46 ± 0.70 | 67.60 ± 0.69 | ||
| CPS | 62.70 ± 1.26 | 65.88 ± 1.63 | 66.98 ± 0.80 | 67.40 ± 0.85 | ||
| CPS+CutMix | 63.16 ± 1.46 | 66.17 ± 0.80 | 67.00 ± 1.10 | 67.15 ± 0.99 | ||
| ClassHyPer | 63.49 ± 1.95 | 66.31 ± 1.67 | 67.03 ± 1.18 | 68.08 ± 0.47 | ||
Table 7.
Accuracy (, %) comparison of ClassHyPer on different datasets.
| Dataset | Training Labels | ClassHyPer | TL with 100% Labels | |||
|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 50% | |||
| DG_Road | 3735 | 57.92 ± 0.26 | 60.03 ± 0.28 | 61.14 ± 0.13 | 63.19 ± 0.27 | 64.73 ± 0.38 |
| Massa_Building | 1065 | 69.85 ± 0.25 | 71.62 ± 0.51 | 72.17 ± 0.47 | 72.31 ± 0.38 | 73.15 ± 0.12 |
| WHU_Building | 4736 | 88.37 ± 0.07 | 88.98 ± 0.19 | 89.30 ± 0.16 | 89.44 ± 0.21 | 89.64 ± 0.04 |
| Potsdam | 612 | 67.13 ± 0.40 | 68.63 ± 0.60 | 70.54 ± 0.30 | 71.87 ± 0.23 | 73.49 ± 0.36 |
| Vaihingen | 692 | 63.49 ± 1.95 | 66.31 ± 1.67 | 67.03 ± 1.18 | 68.08 ± 0.47 | 67.39 ± 0.49 |
Table 8.
Statistics of pixels in different categories of each dataset based on ground-truth data.
| Dataset | Classes | Train | Val | Test | |||
|---|---|---|---|---|---|---|---|
| Ratio | Pixels | Ratio | Pixels | Ratio | Pixels | ||
| DG_Road | Background | 95.79% | 937,917,468 | 95.62% | 156,165,832 | 95.75% | 468,869,474 |
| Road | 4.21% | 41,190,372 | 4.38% | 7,149,880 | 4.25% | 20,815,518 | |
| Massa_Building | Background | 84.47% | 235,820,198 | 87.39% | 8,246,907 | 78.84% | 18,601,348 |
| Building | 15.53% | 43,363,162 | 12.61% | 1,190,277 | 21.16% | 4,991,612 | |
| WHU_Building | Background | 81.34% | 1,009,799,430 | 89.00% | 241,707,225 | 88.87% | 562,861,562 |
| Building | 18.66% | 231,714,558 | 11.00% | 29,873,959 | 11.13% | 70,478,342 | |
| Potsdam | Impervious surfaces | 28.85% | 46,203,252 | 27.54% | 18,265,098 | 31.47% | 41,579,812 |
| Buildings | 26.17% | 41,919,727 | 28.05% | 18,604,168 | 23.92% | 31,601,996 | |
| Low vegetation | 23.52% | 37,670,506 | 23.58% | 15,637,762 | 21.01% | 27,757,373 | |
| Trees | 15.08% | 24,153,823 | 13.52% | 8,969,936 | 17.04% | 22,515,491 | |
| Cars | 1.69% | 2,710,112 | 1.68% | 1,116,603 | 1.97% | 2,596,193 | |
| Clutter/Background | 4.69% | 7,512,564 | 5.62% | 3,728,865 | 4.59% | 6,069,711 | |
| Vaihingen | Impervious surfaces | 29.34% | 53,219,815 | 26.48% | 4,719,397 | 27.35% | 17,853,972 |
| Buildings | 26.88% | 48,763,596 | 24.24% | 4,321,511 | 26.49% | 17,289,928 | |
| Low vegetation | 19.56% | 35,478,641 | 21.93% | 3,909,070 | 20.25% | 13,219,923 | |
| Trees | 22.08% | 40,052,822 | 26.04% | 4,641,147 | 23.63% | 15,421,237 | |
| Cars | 1.26% | 2,283,335 | 1.23% | 219,078 | 1.31% | 855,221 | |
| Clutter/Background | 0.89% | 1,605,439 | 0.09% | 15,589 | 0.97% | 633,575 | |
Table 9.
Accuracy comparison (, %) on different datasets with 5% labels, where the values in bold are the best for each dataset.
| Dataset | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| CutMix | ClassMix | MT | MT+CutMix | MT+ClassMix | CPS | CPS+CutMix | ClassHyPer | |
| DG_Road | 55.63 ± 0.33 | 55.06 ± 0.49 | 51.70 ± 0.87 | 55.85 ± 0.47 | 54.23 ± 0.60 | 52.10 ± 1.16 | 58.88 ± 0.46 | 57.92 ± 0.26 |
| Massa_Building | 66.32 ± 1.49 | 68.98 ± 0.40 | 63.27 ± 2.36 | 66.54 ± 1.52 | 67.98 ± 1.38 | 66.75 ± 0.64 | 69.03 ± 1.26 | 69.85 ± 0.25 |
| WHU_Building | 87.38 ± 0.24 | 87.54 ± 0.22 | 87.37 ± 0.51 | 86.98 ± 0.38 | 87.22 ± 0.05 | 88.44 ± 0.11 | 88.25 ± 0.28 | 88.37 ± 0.07 |
| Potsdam | 65.45 ± 0.25 | 65.62 ± 0.91 | 61.84 ± 0.82 | 61.38 ± 0.79 | 64.83 ± 0.72 | 62.72 ± 0.89 | 66.27 ± 0.69 | 67.13 ± 0.40 |
| Vaihingen | 58.86 ± 1.71 | 60.33 ± 0.83 | 59.46 ± 0.87 | 60.46 ± 1.51 | 60.57 ± 1.40 | 62.70 ± 0.26 | 63.16 ± 1.46 | 63.49 ± 1.95 |
Table 10.
Time efficiency analysis.
| Dataset | TL | ClassHyPer | |||
|---|---|---|---|---|---|
| Time (h) | Time (h) | ||||
| DG_Road | 5% (186) | 0.37 | 52.88 ± 0.39 | 5.20 | 57.92 ± 0.26 |
| 10% (373) | 0.47 | 56.76 ± 0.11 | 5.12 | 60.03 ± 0.28 | |
| 20% (747) | 0.63 | 59.34 ± 0.25 | 5.24 | 61.14 ± 0.13 | |
| 50% (1867) | 1.17 | 62.49 ± 0.21 | 5.44 | 62.56 ± 0.09 | |
| 100% (3735) | 2.00 | 64.73 ± 0.38 | |||
| WHU_Building | 5% (236) | 0.42 | 86.37 ± 0.27 | 6.64 | 88.37 ± 0.07 |
| 10% (473) | 0.52 | 86.46 ± 0.53 | 6.53 | 88.98 ± 0.19 | |
| 20% (947) | 0.73 | 88.15 ± 0.35 | 6.76 | 89.30 ± 0.16 | |
| 50% (2368) | 1.45 | 89.49 ± 0.34 | 7.01 | 89.44 ± 0.21 | |
| 100% (4736) | 2.62 | 89.64 ± 0.04 | |||
Table 11.
The ratio of from ClassHyPer with different proportions of labeled training data to from TL with 100% labels.
| Dataset | 5% | 10% | 20% | 50% | 100% | ||||
|---|---|---|---|---|---|---|---|---|---|
| Labels | Labels | Labels | Labels | Labels | |||||
| DG_Road | 186 | 89.48% | 373 | 92.74% | 747 | 94.45% | 1867 | 96.65% | 3735 |
| Massa_Building | 53 | 95.49% | 106 | 97.91% | 212 | 98.66% | 532 | 98.85% | 1065 |
| WHU_Building | 236 | 98.58% | 473 | 99.26% | 947 | 99.62% | 2368 | 99.78% | 4736 |
| Potsdam | 30 | 91.34% | 61 | 93.38% | 122 | 95.98% | 306 | 97.80% | 612 |
| Vaihingen | 34 | 94.21% | 69 | 98.40% | 138 | 99.47% | 346 | 101.02% | 692 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
He, Y.; Wang, J.; Liao, C.; Shan, B.; Zhou, X. ClassHyPer: ClassMix-Based Hybrid Perturbations for Deep Semi-Supervised Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2022, 14, 879. https://doi.org/10.3390/rs14040879
AMA Style
He Y, Wang J, Liao C, Shan B, Zhou X. ClassHyPer: ClassMix-Based Hybrid Perturbations for Deep Semi-Supervised Semantic Segmentation of Remote Sensing Imagery. Remote Sensing. 2022; 14(4):879. https://doi.org/10.3390/rs14040879
Chicago/Turabian StyleHe, Yongjun, Jinfei Wang, Chunhua Liao, Bo Shan, and Xin Zhou. 2022. "ClassHyPer: ClassMix-Based Hybrid Perturbations for Deep Semi-Supervised Semantic Segmentation of Remote Sensing Imagery" Remote Sensing 14, no. 4: 879. https://doi.org/10.3390/rs14040879
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.

{kind=link}