1. Introduction 1. 简介
A floor plan is a drawing that describes the overall layout of a specific level of a building or a structure. There are different ways to format a floor plan, but all floor plans have both structural indoor elements, such as walls, windows, doors, and stairs, and spatial elements, like rooms and corridors, in common. Digitizing floor plans is challenging, since, in most cases, they are basically images without explicit information of any object. Therefore, feature extraction and analysis of indoor spatial data obtained from floor plan images have been done by pre-processing the input image using image-processing techniques and then applying statistical and analytical algorithms. Studies with heuristic algorithms have resulted in high accuracy and precision; however, these algorithms cannot be applied to different types of drawing styles due to the limitations of being dependent on certain types of data [
1,
2,
3,
4,
5,
6]. To alleviate these limitations, various machine learning-based approaches have been used in floor plan analysis. Among them, Convolutional Neural Network-based approaches have been used the most, as they can be applicable to many styles of floor-plan images. CNN-based approaches only require a basic level of image pre-processing techniques and are robust to floor plan noise. In addition, they can be applied to any style of drawing without the need for transformation, which makes them efficient and versatile [
7,
8,
9,
10].
楼层平面图是一种描述建筑或结构特定层整体布局的图纸。楼层平面图的格式有多种,但所有楼层平面图都具有共同的室内结构元素,如墙壁、窗户、门和楼梯,以及空间元素,如房间和走廊。由于在大多数情况下,楼层平面图基本上是图像,没有任何对象的明确信息,因此数字化楼层平面图具有挑战性。因此,通过使用图像处理技术对输入图像进行预处理,然后应用统计和分析算法,对从楼层平面图像获得的室内空间数据进行特征提取和分析。使用启发式算法的研究导致了高精度和准确性;然而,由于这些算法依赖于某些类型的数据,因此它们不能应用于不同类型的绘图风格[1, 2, 3, 4, 5, 6]。为了减轻这些限制,已经在楼层平面分析中使用了基于各种机器学习的方法。其中,基于卷积神经网络的方法被使用得最多,因为它们可以适用于许多风格的楼层平面图像。 基于 CNN 的方法只需要基本的图像预处理技术,对平面图噪声具有鲁棒性。此外,它们可以应用于任何风格的图纸,无需进行转换,这使得它们既高效又灵活[7, 8, 9, 10]。However, because these methods perform pixel-level segmentation, the exact shape of indoor elements is hard to capture. To overcome this limitation, these approaches have incorporated additional post-processing steps that abstract the output of the neural network. This, however, results in feature loss of the original indoor elements, such as how polygons are expressed as line vectors. For example, walls should have a thickness and an area of their own; nonetheless, as the shapes get blurry as they pass through the convolution layers, the walls are finally depicted as line vectors by the post-processing algorithms [
7,
8]. Although abstracting a floor plan layout through machine learning-based models may be essential for specific user purposes, such as to express navigable areas in IndoorGML format [
11], vector outputs that keep the form of the original floor plan image intact can be transformed into various objects depending on the user’s purpose, owing to the high flexibility and deformation ability of the vector data type.
然而,由于这些方法执行像素级分割,室内元素的精确形状难以捕捉。为了克服这一限制,这些方法已经纳入了额外的后处理步骤,以抽象化神经网络输出。然而,这导致了原始室内元素的特征损失,例如如何将多边形表示为线向量。例如,墙壁应该有自己的厚度和面积;然而,由于形状在通过卷积层时变得模糊,最终后处理算法将墙壁描绘为线向量[7, 8]。尽管通过基于机器学习的模型抽象化楼层平面布局对于特定用户目的可能是必要的,例如在 IndoorGML 格式中表示可导航区域[11],但由于矢量数据类型的高灵活性和变形能力,保持原始楼层平面图像形式的矢量输出可以根据用户目的转换为各种对象。In this paper, we propose a framework that finds any kind of element in the floor plan without losing the shape information. It first vectorizes the input floor plan image as it is to maintain the shape of the original indoor elements and minimize the abstraction. The polygon vector set is then converted into a region adjacency graph. The graph is then fed to an inductive learning-based graph neural network (GNN), which is used to compare multiple floor plan graphs and perform node classification by analyzing inherent features and the relationships between the nodes. This allows the user to classify basic indoor elements (e.g., walls, windows, doors, etc.) and symbols, together with space elements (e.g., rooms, corridors, or outer spaces), without losing their shape and arial features. Furthermore, a new GNN model, the Distance-Weighted Graph Neural Network (DWGNN), is presented. In accordance with the first law of geography [
12], the neighboring nodes that are close to a target node should be given relatively high attention values compared to the neighbors that are far apart from the target node. To do so, we developed a GNN model that assigns attention values to the neighbors in a target node’s neighboring subgraph. The DWGNN considers the distance information between the nodes, expressed by edge features, in the spatial network (graph). To evaluate the performance and expressiveness of the new proposed floor plan analysis framework, we applied it to two floor plan datasets and one data-augmented dataset.
本文提出了一种框架,可以在不丢失形状信息的情况下找到平面图中的任何元素。该框架首先将输入的平面图图像矢量化,以保持原始室内元素的形状并最小化抽象化。然后将多边形矢量集转换为区域邻接图。该图随后被输入到基于归纳学习的图神经网络(GNN)中,该网络通过分析固有特征和节点之间的关系来比较多个平面图图并执行节点分类。这使得用户能够对基本室内元素(例如墙壁、窗户、门等)和符号以及空间元素(例如房间、走廊或外部空间)进行分类,同时不丢失它们的形状和面积特征。此外,还提出了一种新的 GNN 模型,即距离加权图神经网络(DWGNN)。根据地理学的第一定律[12],与目标节点较近的相邻节点应比与目标节点较远的相邻节点赋予相对较高的关注值。 为了实现这一点,我们开发了一个 GNN 模型,该模型将注意力值分配给目标节点邻近子图中的邻居。DWGNN 考虑了在空间网络(图)中节点之间的距离信息,这些信息由边特征表示。为了评估新提出的楼层平面分析框架的性能和表达能力,我们将它应用于两个楼层平面数据集和一个数据增强数据集。The remainder of the paper is structured as follows. In
Section 2, we discuss the limitations of previous researches related to floor plan analysis, particularly regarding indoor element classification using rule-based methods and machine learning approaches. In
Section 3, based on the described limitations, we propose a framework for floor plan element classification via GNN. Finally, we analyze the results on three datasets and discuss issues and further research.
本文其余部分结构如下。在第 2 节中,我们讨论了与平面图分析相关的先前研究的局限性,特别是关于使用基于规则的方法和机器学习方法的室内元素分类。在第 3 节中,基于所描述的局限性,我们提出了一种通过 GNN 进行平面图元素分类的框架。最后,我们在三个数据集上分析了结果,并讨论了问题和进一步的研究。 2. Related Works 2. 相关工作
2.1. Rule-Based Heuristic Methods and Machine Learning Algorithms in Floor Plan Analysis Research
2.1. 基于规则的启发式方法和机器学习算法在平面分析研究中的应用
Detecting and classifying floor-plan basic elements or regions have been studied for many years, with various approaches. Ruled-based heuristic approaches utilize methods based on image processing, such as the morphological filtering [
1,
6], Hough transformation [
2,
4], text/graphic recognition [
3,
4], or using graph algorithms [
5,
13]. Although they have showed meaningful outputs, rule-based heuristic approaches struggle to maintain the shapes of elements, and can only be applied to specific drawing styles.
检测和分类平面图基本元素或区域已被研究多年,采用各种方法。基于规则的启发式方法利用基于图像处理的方法,如形态学滤波[1, 6]、霍夫变换[2, 4]、文本/图形识别[3, 4]或使用图算法[5, 13]。尽管它们已经显示出有意义的输出,但基于规则的启发式方法难以保持元素的形状,并且只能应用于特定的绘图风格。To avoid these style-dependent heuristics and take expressive generality among various drawing styles, approaches using machine learning algorithms have emerged . De las Heras et al. [
7] utilized a machine learning algorithm to detect indoor elements, and then converted the output into vector data. Citing the limitation that the existing rule-based methods are ad hoc and only applicable to certain drawing styles, they presented an automatic method that detected room boundaries in floor plans invariant to the style of the drawings. They used a Support Vector Machine Bag of Visual Words (SVM-BOVW) to detect the pixel boundaries of the structural elements, which included walls, doors, and windows, and then created the vector data. In addition, the model recognizes room boundaries in the floor plan by finding closed regions surrounded by vectors of structural elements. Liu et al. [
8] trained a CNN to detect the junctions, such as wall corners, in a floor plan and applied integer programming to extract vector data by combining the junctions to build simple primitives like walls and windows. In addition, they found spaces with closed combinations of simple primitives. However, all of the elements were assumed vertical and horizontal, thus failing to secure the shapes of the elements and resulting in largely abstracted primitives, such as expressing the walls with line vectors. Dodge et al. [
9] used Fully Connected Networks (FCN) and Faster R-CNN to segment walls and detect objects, respectively, in floor plans with various drawing styles. They also used OCR to be able to recognize the size of the rooms and to place furniture models scaled to the scene. Zeng et al. [
10] proposed a method that detects and classifies walls, doors, windows, and rooms by training a VGG encoder-decoder. Unlike [
8], their method is applicable to non-rectangular shape elements and is able to obtain the shape features of indoor elements. In addition, they used an attention mechanism for the decoder units. The two decoders share the attention values to predict the boundary and the type of rooms. However, their method is limited to only a few classes, which are used as a layout to help the decoder find the room boundaries; these boundaries are ultimately placed under the same class.
为了避免这些基于风格的启发式方法,并取各种绘图风格之间的表现性泛化,出现了使用机器学习算法的方法。De las Heras 等人[7]利用机器学习算法检测室内元素,然后将输出转换为矢量数据。鉴于现有基于规则的方法是临时的且仅适用于某些绘图风格,他们提出了一种自动方法,该方法检测了不受绘图风格影响的平面图中的房间边界。他们使用支持向量机视觉词袋(SVM-BOVW)检测结构元素的像素边界,包括墙壁、门和窗户,然后创建矢量数据。此外,该模型通过寻找由结构元素向量包围的封闭区域来识别平面图中的房间边界。Liu 等人[8]训练了一个 CNN 来检测平面图中的接合处,如墙角,并应用整数规划通过结合接合处构建简单的原语(如墙壁和窗户)来提取矢量数据。此外,他们还找到了由简单原语封闭组合的空间。 然而,所有元素都被假定为垂直和水平,因此未能确保元素的形状,导致大量抽象的原始形状,例如用线向量表示墙壁。Dodge 等人[9]使用全连接网络(FCN)和 Faster R-CNN 分别对具有各种绘图风格的平面图中的墙壁进行分割和检测物体。他们还使用 OCR 来识别房间的大小,并将按场景比例缩放的家具模型放置其中。Zeng 等人[10]提出了一种方法,通过训练 VGG 编码器-解码器来检测和分类墙壁、门、窗户和房间。与[8]不同,他们的方法适用于非矩形形状元素,并能获取室内元素的形状特征。此外,他们还使用了注意力机制来处理解码器单元。两个解码器共享注意力值以预测边界和房间的类型。然而,他们的方法仅限于少数几个类别,这些类别用作布局以帮助解码器找到房间边界;这些边界最终被放置在同一个类别下。Floor plan analysis using machine learning algorithms has shown great potential on various floor plan datasets, but still, each approach has its own limitations and shortcomings. Models trained on various input floor plan datasets may have great adaptability, but their outputs may be blurry as they perform pixel-level segmentation. This creates problems in the output, such as unconnected lines, which result in unclosed vectors. In many cases, room detection and recognition depend heavily on structural elements in the floor plan, such as walls, doors, and/or windows, and if these structural elements have unclosed issues, they will considerably affect the room formation process. Because elements may lose their shape information during the vectorization process [
7,
8], some approaches omit this process in order to secure the shape features [
9,
10]. In addition, none of the approaches that concentrated on detecting structural elements and space elements considers symbolic elements, such as cabinets, baths, or toilets, among others.
使用机器学习算法对平面图进行分析在多种平面图数据集上显示出巨大潜力,但仍然,每种方法都有其自身的局限性和不足。在多种输入平面图数据集上训练的模型可能具有很高的适应性,但它们的输出可能因为进行像素级分割而模糊。这导致输出中出现如未连接的线条等问题,从而产生未闭合的矢量。在许多情况下,房间检测和识别高度依赖于平面图中的结构元素,如墙壁、门和/或窗户,如果这些结构元素存在未闭合的问题,将大大影响房间形成过程。由于元素可能在矢量化过程中丢失其形状信息[7, 8],一些方法省略此过程以确保形状特征[9, 10]。此外,专注于检测结构元素和空间元素的所有方法都没有考虑符号元素,如橱柜、浴室或厕所等。 2.2. Graph Neural Network (Gnn) and Floor Plan Analysis Using Gnn
2.2. 图神经网络(GNN)和基于 GNN 的楼层平面分析
A graph data structure consists of a finite set of nodes (vertices) and edges (links). A node represents an entity, and an edge represents a relation between two nodes. Graphs are often referred to as non-euclidean data structures, since they are not confined to any particular dimension. Existing deep learning algorithms applied to euclidean data structures have shown great performance. However, existing deep learning models are unable to learn graphs because permutation between nodes can appear in various ways. Accordingly, GNNs [
14,
15] have been devised to describe a way to express the order of the nodes and allow the neural network to learn graph data structure.
图数据结构由有限个节点(顶点)和边(链接)组成。节点表示实体,边表示两个节点之间的关系。图通常被称为非欧几里得数据结构,因为它们不受任何特定维度的限制。应用于欧几里得数据结构的现有深度学习算法已显示出优异的性能。然而,现有的深度学习模型无法学习图,因为节点之间的排列可以以各种方式出现。因此,设计了图神经网络(GNNs [14, 15])来描述表达节点顺序的方法,并允许神经网络学习图数据结构。In recent years, GNNs have undergone numerous variations of the basic definition. Kipf et al. [
16] introduced the graph convolution networks (GCN) to utilize the convolution operation on graphs by updating the nodes’ latent vector using a normalized Laplacian matrix as an adjacency matrix of the input graph. Hamilton et al. [
17] proposed GraphSAGE and showed that the results of the latent vector of outcome differs with various AGGREGATE functions, and applied this notion to perform inductive learning to train the model with, not a single, but multiple graphs. Xu et al. [
18] found that GNN models cannot be properly trained, and introduced a new model, the graph isomorphism network (GIN), that can perform as much as the WL test, which is an isomorphism test for graph structure. They also classified graph-related tasks that can be appropriately applied according to the AGGREGATE methods.
近年来,GNNs 经历了基本定义的多种变化。Kipf 等人[16]引入了图卷积网络(GCN),通过使用归一化拉普拉斯矩阵作为输入图的邻接矩阵来更新节点的潜在向量,从而在图上利用卷积操作。Hamilton 等人[17]提出了 GraphSAGE,并表明结果潜在向量的差异与各种 AGGREGATE 函数有关,并将这一概念应用于归纳学习,用多个图而不是单个图来训练模型。Xu 等人[18]发现 GNN 模型无法得到适当的训练,并引入了一种新的模型,即图同构网络(GIN),它可以执行与 WL 测试相当的任务,WL 测试是图结构的同构测试。他们还根据 AGGREGATE 方法对可以适当应用的图相关任务进行了分类。A GNN can analyze various real-world problems. Due to their inherent characteristics, they can be represented as a graph, and GNN would take them as input to analyze and predict. A floor plan can also be converted into a graph by treating cell regions as nodes and constructing an adjacency matrix based on the adjacency among the regions of the floor plan. Various graph algorithms and analyses have been applied to floor plan graphs. In particular, floor plan graphs have been extensively used in the field of floor plan design research, which has recently studied different methodologies using GNN. For example, an automated generation framework for floor plan design using GNNs was proposed by Hu et al. [
19]. When it comes to detecting and classifying the indoor symbols or elements, Renton et al. [
20] applied GNN to classify symbols in the floor plan. They pre-processed floor plan images and considered the centroids of regions surrounded by black pixels as nodes. A region adjacency graph is then constructed by connecting the nodes that share a pixel line. Then, the floor plan graph is fed into a GNN model as the input graph and a graph is obtained where the nodes were classified according to their local dependencies. This study is the first to use GNN to classify symbols in floor plan images. However, it only targeted symbols and objects, excluding walls and rooms, which are the most important elements of floor plan images. In addition, the final output of the approach is limited to graphs that represent only the symbol classes and are not converted into vector-format output for utilization.
一个 GNN 可以分析各种现实世界问题。由于它们的固有特性,它们可以被表示为图,GNN 将它们作为输入进行分析和预测。平面图也可以通过将单元格区域视为节点,并根据平面图区域的相邻性构建邻接矩阵来转换为图。已经将各种图算法和分析应用于平面图图。特别是,平面图图在平面图设计研究领域得到了广泛的应用,最近研究了使用 GNN 的不同方法。例如,Hu 等人[19]提出了一种使用 GNN 的平面图设计自动化生成框架。当涉及到检测和分类室内符号或元素时,Renton 等人[20]将 GNN 应用于平面图中的符号分类。他们预处理了平面图图像,并将围绕黑色像素的区域的质心视为节点。然后通过连接共享像素线的节点构建了一个区域相邻图。 然后,将楼层平面图作为输入图输入到 GNN 模型中,得到一个节点根据其局部依赖关系进行分类的图。这项研究是首次使用 GNN 对楼层平面图像中的符号进行分类。然而,它只针对符号和对象,排除了墙壁和房间,这些是楼层平面图像最重要的元素。此外,该方法最终输出仅限于表示符号类别的图,并未转换为向量格式输出以供利用。 3. Materials and Methods 3. 材料与方法
To overcome the limitations described in the previous studies on floor plan element extraction and classification tasks, the following requirements were defined.
为了克服先前关于平面元素提取和分类任务研究中描述的限制,定义了以下要求。
- (1)
The framework must detect and classify space elements, such as rooms, together with basic elements (walls, doors, etc.) and symbols.
框架必须检测和分类空间元素,如房间,以及基本元素(墙壁、门等)和符号。
- (2)
The framework must start with raster data and output vector data maintaining shape without abstraction.
框架必须从栅格数据开始,输出矢量数据,保持形状不抽象。
- (3)
The framework must perform inductive learning by separating a set of graphs of various types and sizes into graph units, rather than transductive learning that deals with a single large graph.
该框架必须通过将各种类型和大小的图集分离成图单元来进行归纳学习,而不是处理单个大型图的演绎学习。
To meet these requirements, developing and extending the ideas used in [
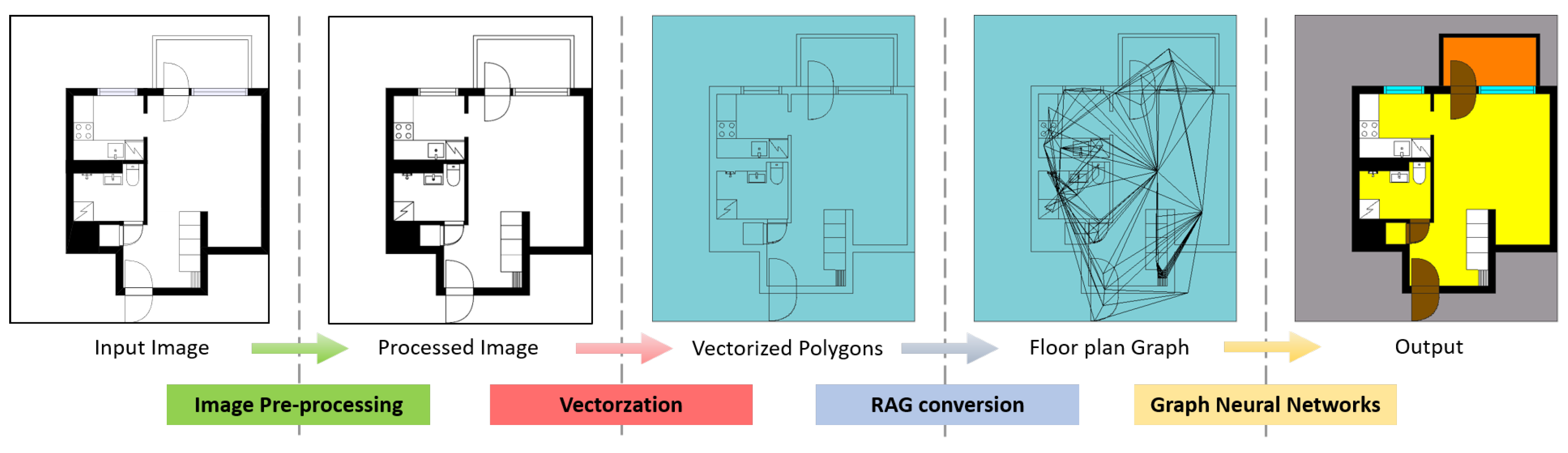
20], we propose a new framework as follows. The raster floor plan image is fed to the framework as the input data. The image is first pre-processed in order to obtain a binarized image to be vectorized. The closed regions in the image become polygons after the vectorization process. The polygons with shape features are then converted into a region adjacency graph (RAG) according to their adjacent relationship with neighboring polygons. The RAG is then fed into the neural network to train the GNN model. The final output of the framework is a set of polygons with different classes. The overview of the proposed framework is shown in .
为了满足这些要求,在[20]中使用和扩展了想法,我们提出了以下新框架。将栅格楼层平面图像作为输入数据输入到框架中。首先对图像进行预处理,以获得要矢量化二值化图像。图像中的封闭区域在矢量化过程中变为多边形。然后根据与相邻多边形的相邻关系,具有形状特征的多边形被转换为区域邻接图(RAG)。然后将 RAG 输入到神经网络中训练 GNN 模型。框架的最终输出是一组具有不同类别的多边形。所提出框架的概述如图 1 所示。
Figure 1.
Overview of the proposed framework. The input floor plan image is pre-processed to erase texts and get binarized. The processed image is then vectorized depending on its closed regions and converted to an RAG. The floor plan graph is input to a GNN module in order to classify each polygon according to its and the neighbors’ feature vectors.
图 1. 所提框架概述。输入楼层平面图像经过预处理以擦除文本并获取二值化。然后根据其封闭区域进行矢量化,并将其转换为 RAG。楼层平面图输入到 GNN 模块中,以根据其和邻居的特征向量对每个多边形进行分类。
3.1. Image Pre-Processing and Vectorization
3.1. 图像预处理和向量化
The pre-processing phase may vary depending on the layout style of the floor plans, but most consist of text removal and binarization. The three channels of the input floor plan image (Red, Blue, and Green) are merged into a single channel and binarized. The text information is removed using the OCR algorithm. The processed image is then vectorized. De [
6] assumed that only walls are depicted as thick black lines in a floor plan layout; therefore, thick and thin lines can be distinguished using a morphological transformation, and thick lines can be considered as walls. However, this approach can only be applied to specific floor plan styles, as in many cases, walls could be represented as white areas. To vectorize the image regardless of the floor plan drawing style, we chose to vectorize the white and black areas separately.
预处理阶段可能因平面图的布局风格而异,但大多数包括文本移除和二值化。输入平面图图像的三个通道(红色、蓝色和绿色)合并为一个通道并二值化。使用 OCR 算法移除文本信息。处理后的图像随后进行矢量化。De [6] 假设只有墙壁在平面图布局中以粗黑线表示;因此,可以使用形态学变换区分粗细线条,并将粗线视为墙壁。然而,这种方法只能应用于特定的平面图风格,因为在许多情况下,墙壁可能以白色区域表示。为了不受平面图绘制风格的影响进行矢量化,我们选择分别矢量化白色和黑色区域。The detailed process is described as follows. A closed area surrounded by black pixels in the image becomes a polygon object. Likewise, a set of polygons is generated from all the closed white areas in the plan (c). If the floor plan layout contains black areas, the empty polygon with the size of the floor plan (b) does the difference operation on the white polygon set. This creates a second set of polygons that represent the black areas in the floor plan (d). Since we binarized the image, there are only two colors in the image, which make it possible to turn every area in the image into a polygon regardless of the drawing or layout style. Lastly, the two polygon sets get merged, and the complete set of polygons is generated (e). During this process, the regions occupied by the pixel lines that surround the polygons will not be included in the polygons. Therefore, the polygons will be buffered by the thickness of the pixel line before executing the difference operation (f). Buffering the polygon is crucial because, if the polygons are separated from one another, the adjacency operation will return false when constructing the adjacency graph. Taking the thickness of the pixel line t, the buffering distance parameter is selected as 𝑡/2, as each pixel line has to be covered by two polygons from two directions.
详细过程描述如下。图像中由黑色像素包围的封闭区域成为多边形对象。同样,从平面图(图 2c)中所有封闭的白色区域生成一组多边形。如果平面图布局包含黑色区域,则与平面图大小相同的空多边形(图 2b)对白色多边形集进行差集运算。这创建了一个代表平面图中黑色区域的第二个多边形集(图 2d)。由于我们对图像进行了二值化,图像中只有两种颜色,这使得无论绘图或布局风格如何,都可以将图像中的每个区域都转换为多边形。最后,将两个多边形集合并,生成完整的多边形集(图 2e)。在这个过程中,围绕多边形的像素线所占据的区域将不包括在多边形内。因此,在执行差集运算之前,多边形将由像素线的厚度进行缓冲(图 2f)。 缓冲多边形至关重要,因为如果多边形彼此分离,则在构建邻接图时邻接操作将返回 false。考虑像素线的厚度,缓冲距离参数选为 𝑡/2 ,因为每个像素线必须由两个方向的两个多边形覆盖。
Figure 2.
Overview of the vectorization process. The white areas in (a) are vectorized and buffered according to the thickness of the pixel lines surrounding them (c). The black areas are converted into polygons (d), which are generated by the difference operation between (b,c). Finally, the complete polygon set (e) is generated by merging the two polygon sets. (f) describes the detailed process of polygon buffering (the frame color of each step shows the respective small square in the process in detail).
图 2. 向量化过程概述。图(a)中的白色区域根据其周围像素线的厚度进行向量和缓冲。黑色区域被转换为多边形(d),这些多边形是通过(b,c)之间的差值操作生成的。最后,通过合并两个多边形集生成完整的多边形集(e)。(f)描述了多边形缓冲的详细过程(每个步骤的框架颜色显示了过程中相应的详细小方块)。
3.2. Region Adjacency Graph (Rag) Conversion and Feature Extraction
3.2. 区域邻接图(RAG)转换和特征提取
Algorithm 1 describes the RAG conversion process. First, an empty graph
G is created, and for each polygon element
p in the polygon set
P, the polygon centroid of
p (
𝑣𝑝) is added as a node. To construct the edge set of
G,
p executes an
INTERSECTS operation on another polygon
𝑞∈𝑃,𝑞≠𝑝. With the rest of the polygon elements in
P,
p would need to execute the
INTERSECTS operation
|𝑃|−1 times, and the number of iterations for
P would increase exponentially with the number of nodes. To reduce the number of iterations and the complexity, instead of two nested loops, we used an
STRtree[
21], which is a spatial indexing algorithm based on an
R-tree. The tree returns a resulting polygon set
Q when
p queries the
INTERSECTS of the other spatial objects. If a polygon element
q is in
Q and
q’s area is bigger than the minimum area parameter
m, the edge between
𝑣𝑝 and
𝑣𝑞 is added to the edge set
E. By using the
STRtree, the time complexity of the RAG conversion process is reduced from
𝑂(𝑛2) to
𝑂(𝑛log𝑚𝑛).
n is the number of polygons (nodes) and
m is the number of entries in the tree.
算法 1 描述了 RAG 转换过程。首先,创建一个空图 G,然后对于多边形集合 P 中的每个多边形元素 p,将 p 的多边形质心( 𝑣𝑝 )作为一个节点添加。为了构建 G 的边集,p 对另一个多边形 𝑞∈𝑃,𝑞≠𝑝 执行 INTERSECTS 操作。对于 P 中的其余多边形元素,p 需要执行 INTERSECTS 操作 |𝑃|−1 次,P 的迭代次数会随着节点数量的增加而呈指数增长。为了减少迭代次数和复杂性,我们使用了 STRtree [21],这是一个基于 R-tree 的空间索引算法。当 p 查询其他空间对象的 INTERSECTS 时,树返回一个结果多边形集 Q。如果一个多边形元素 q 在 Q 中且 q 的面积大于最小面积参数 m,则将 𝑣𝑝 和 𝑣𝑞 之间的边添加到边集 E 中。通过使用 STRtree ,将 RAG 转换过程的时间复杂度从 𝑂(𝑛2) 降低到 𝑂(𝑛log𝑚𝑛) 。n 是多边形的数量(节点数),m 是树中的条目数。Algorithm 1: RAG conversion
算法 1:RAG 转换 |
 |
The constructed graph
𝐺=(𝒱,ℰ) consists of the node set
𝒱 and the edge set
ℰ, which represent the adjacent relationship among nodes in the floor plan layout. A polygon node
𝑣𝑝 is recognized as the centroid of
p and has its own unique feature vector
𝐱𝑣𝑝∈𝐗𝑣.
𝐗𝑣 is the feature matrix of
G whose size is the number of
𝒱 and the dimension of the node feature vector
𝑑𝑣.
𝑒𝑝𝑞 is an element of the edge set
E, which represents how the polygon nodes
𝑣𝑝 and
𝑣𝑞 are connected to each other. An edge also has its own feature vector
𝐱𝑒𝑝𝑞∈𝐗𝑒. Each edge feature vector has
𝑑𝑒 features. If
𝑑𝑒=1, we consider the edge feature as the weight value between two nodes. The constructed RAG
G is described as follows:
构建的图 𝐺=(𝒱,ℰ) 由节点集 𝒱 和边集 ℰ 组成,它们表示楼层平面布局中节点之间的相邻关系。一个多边形节点 𝑣𝑝 被识别为 p 的质心,并具有其独特的特征向量 𝐱𝑣𝑝∈𝐗𝑣 。 𝐗𝑣 是 G 的特征矩阵,其大小是 𝒱 的数量和节点特征向量的维度 𝑑𝑣 。 𝑒𝑝𝑞 是边集 E 的一个元素,它表示多边形节点 𝑣𝑝 和 𝑣𝑞 如何相互连接。边也有其特征向量 𝐱𝑒𝑝𝑞∈𝐗𝑒 。每个边特征向量有 𝑑𝑒 个特征。如果 𝑑𝑒=1 ,我们将边特征视为两个节点之间的权重值。构建的 RAG G 描述如下:In the framework, we used four features for
𝐗𝑣 and a single feature for
𝐗𝑒 (a weight value). A node feature vector for node
𝑣𝑝 (
𝐱𝑣𝑝∈𝐗𝑣) consists of the area of
p, the degree of the node, the normalized central moment of order 1 and 1 for the polygon, and the Zernike moment [
22] of order 4 and repetition 2 (
𝐱𝑣𝑝∈ℝ4). The two used moments are scale- and rotation-invariant. The edge feature vector
𝐱𝑒𝑝𝑞∈𝐗𝑒 consists of the euclidean distance between its two nodes
(𝑣𝑝,𝑣𝑞). Edge features are considered as weights of
G since the edge feature dimension parameter
𝑑𝑒=1. The polygon set
P and the RAG
G are constructed for each floor plan layout in the datasets. In the following section, we will describe various GNN models to classify the classes of polygons in
P using
G.
在框架中,我们为 𝐗𝑣 使用了四个特征,为 𝐗𝑒 (一个权重值)使用了一个特征。节点 𝑣𝑝 ( 𝐱𝑣𝑝∈𝐗𝑣 )的节点特征向量由 p 的面积、节点的度、多边形的归一化一阶中心矩和 1 以及泽尼克矩[22]的 4 阶和 2 次重复( 𝐱𝑣𝑝∈ℝ4 )组成。所使用的两个矩是尺度不变和旋转不变的。边特征向量 𝐱𝑒𝑝𝑞∈𝐗𝑒 由其两个节点 (𝑣𝑝,𝑣𝑞) 之间的欧几里得距离组成。边特征被视为 G 的权重,因为边特征维度参数 𝑑𝑒=1 。为数据集中的每个楼层平面布局构建了多边形集 P 和 RAG G。在下一节中,我们将描述各种 GNN 模型,以使用 G 对 P 中的多边形类别进行分类。 3.3. Graph Neural Network Models
3.3. 图神经网络模型
A GNN performs a prediction on various tasks, such as node classification, edge prediction, and graph classification. Like other deep learning models, it extracts a unique embedding vector of each entity in the target dataset and compares its similarity to other embedding vectors to predict a result as close as possible to the label data. The domain of interest of GNN varies, including nodes, edges, graphs, and subgraphs [
23]. The GNN takes the adjacency matrix
A and the feature matrix
X of the target graph as input.
A represents the relationship between the nodes, and
X holds the feature vector for each node in the target graph. If features are found on the edges, they can be added to the value for
A or taken as a separate edge feature matrix.
一个 GNN 在多种任务上执行预测,例如节点分类、边预测和图分类。与其他深度学习模型一样,它从目标数据集中提取每个实体的唯一嵌入向量,并将其与其他嵌入向量之间的相似性进行比较,以预测与标签数据尽可能接近的结果。GNN 感兴趣的应用领域包括节点、边、图和子图[23]。GNN 以目标图的邻接矩阵 A 和特征矩阵 X 作为输入。A 表示节点之间的关系,X 包含目标图中每个节点的特征向量。如果边上存在特征,可以将它们添加到 A 的值中或作为单独的边特征矩阵。GNN has multiple layers, and each layer consists of the AGGREGATE and UPDATE functions. The AGGREGATE function aggregates information coming from the neighboring nodes and returns a message. The UPDATE function combines the target node’s embedding vector and the message to update the new latent embedding vector of the target node. This process is called message passing. The forward-propagation process of a vanilla GNN model for generating the new embedding vector of node
v at layer
k can be as follows [
24]:
GNN 具有多层,每层由 AGGREGATE 和 UPDATE 函数组成。AGGREGATE 函数聚合来自相邻节点的信息并返回一个消息。UPDATE 函数将目标节点的嵌入向量和消息结合以更新目标节点的新的潜在嵌入向量。这个过程称为消息传递。对于生成节点 v 在层 k 的新嵌入向量的 vanilla GNN 模型的正向传播过程可以如下 [ 24]:
where
𝒩(𝑣) is the set of neighboring nodes of
v and
𝐡𝑘−1𝑢 is the latent embedding vector of
𝑢∈𝒩(𝑣) at layer
𝑘−1.
AGGREGATE𝑘 aggregates the embedding vectors to return the message
𝐦𝑘𝒩(𝑣).
UPDATE𝑘 takes
𝐦𝑘𝒩(𝑣) with
𝐡𝑘−1𝑣, which is the embedding vector of node
v at layer
𝑘−1 as input and generates the embedding vector of node
v at layer
k. Both
AGGREGATE𝑘 and
UPDATE𝑘 are arbitrary differentiable functions at layer
k (i.e., neural networks). These two functions can be defined in various ways depending on the task the model wants to solve. The definition of the AGGREGATE function allows neighboring nodes to determine how they will affect the target node, and the UPDATE function determines how to combine the message and target node’s embedding vector of the previous layer, and how the embedding vector is generated.
𝒩(𝑣) 是节点 v 的邻接节点集, 𝐡𝑘−1𝑢 是在层 𝑘−1 上 𝑢∈𝒩(𝑣) 的潜在嵌入向量。 AGGREGATE𝑘 将嵌入向量聚合以返回消息 𝐦𝑘𝒩(𝑣) 。 UPDATE𝑘 以 𝐦𝑘𝒩(𝑣) 和 𝐡𝑘−1𝑣 作为输入,其中 𝐡𝑘−1𝑣 是层 𝑘−1 上节点 v 的嵌入向量,生成层 k 上节点 v 的嵌入向量。 AGGREGATE𝑘 和 UPDATE𝑘 都是层 k 上的任意可微函数(即神经网络)。这两个函数可以根据模型想要解决的问题以各种方式定义。AGGREGATE 函数的定义允许相邻节点确定它们如何影响目标节点,而 UPDATE 函数确定如何结合消息和目标节点上一层的嵌入向量,以及如何生成嵌入向量。Our goal is to classify the polygon nodes by extracting the latent embedding vectors for each node in the floor plan graph, which is categorized as a node classification task. The performance of a GNN model for node classification highly depends on the structure of its network, not only regarding the functions used for AGGREGATE and UPDATE, but also regarding the number of layers. As the number of layers increases, the wider the neighborhood node information is included. This is similar to the receptive field of a target pixel in a CNN; as the number of layers increases, the receptive field widens.
我们的目标是通过对楼层平面图中的每个节点提取潜在嵌入向量来对多边形节点进行分类,这被归类为节点分类任务。GNN 模型在节点分类中的性能高度依赖于其网络结构,不仅涉及用于 AGGREGATE 和 UPDATE 的功能,还涉及层数。随着层数的增加,包含的邻域节点信息越广泛。这类似于 CNN 中目标像素的感受野;随着层数的增加,感受野变宽。
3.3.1. A GNN Variant for Inductive Learning on Graphs
3.3.1. 图上归纳学习的 GNN 变体
Most of the GNN models target one large graph, such as a social network, focused on generating embedding nodes from a single fixed graph. However, from a real-world application point of view, a GNN model that generates embedding vectors for unseen nodes, or entirely new graphs, is needed [
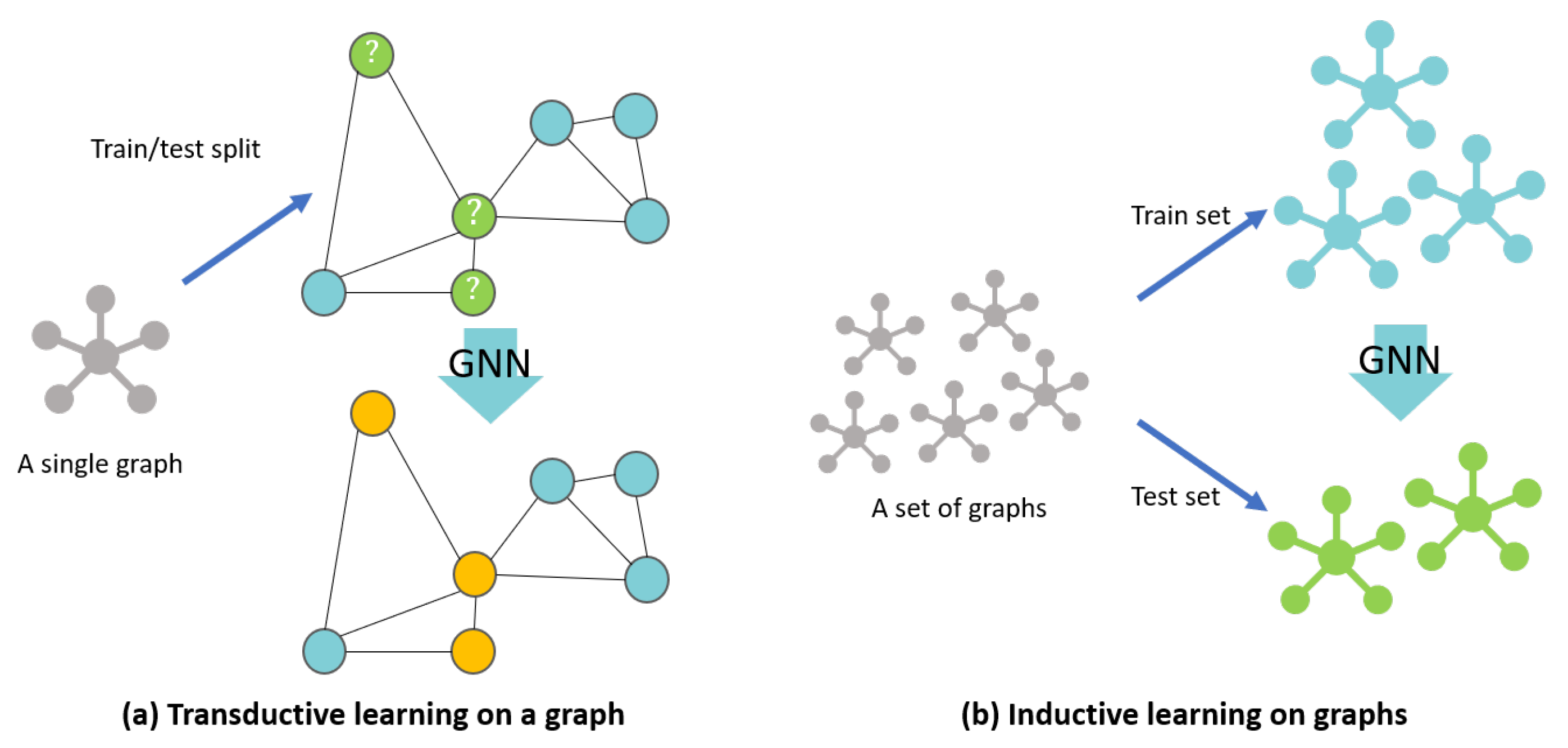
17]. explains the difference between transductive learning and inductive learning in graphs. Our study also required the inductive learning GNN model as the floor plan datasets mostly consist of various floor plans, and each floor plan is converted into a unique graph. Inductive learning enables prediction on these completely unseen graphs. We trained the inductive learning-based GNN model on the floor plan graphs of the training set, and the model predicted the classes of the nodes in the test-set floor-plan graphs.
大多数 GNN 模型针对一个大型图,例如社交网络,专注于从单个固定图中生成嵌入节点。然而,从实际应用的角度来看,需要一个能够为未见节点或全新图生成嵌入向量的 GNN 模型[17]。图 3 解释了图中的归纳学习和转导学习之间的区别。我们的研究还需要归纳学习 GNN 模型,因为大多数楼层平面数据集主要由各种楼层平面组成,每个楼层平面都转换为唯一的图。归纳学习使这些完全未见过的图上的预测成为可能。我们在训练集的楼层平面图上训练了基于归纳学习的 GNN 模型,该模型预测了测试集楼层平面图中节点的类别。
Figure 3.
Node classification on a transductive learning GNN method (a) and on an inductive learning GNN method (b). In the transductive learning method, (a) the model is trained by accessing all the nodes and edges in order to predict the class of nodes in the test set (denoted by question marks). In the inductive learning method (b), on the other hand, the set of graphs is split into training and test set, and the test set is predicted with a GNN model trained on a set of training graphs.
图 3. 在归纳学习 GNN 方法(b)和演绎学习 GNN 方法(a)上的节点分类。在演绎学习方法中,(a)模型通过访问所有节点和边来训练,以预测测试集中节点(用问号表示)的类别。在归纳学习方法(b)中,另一方面,图集被分为训练集和测试集,测试集使用在训练图集上训练的 GNN 模型进行预测。
Many existing spatial-based GNN models are transductive learning-based GNN models [
16,
18], while GraphSAGE [
17] is based on inductive learning. GraphSAGE is a general inductive framework for generating latent embedding vectors of completely unseen nodes. In the GraphSAGE model, which consists of
K layers, the algorithm for generating an embedding vector of node
v at layer
k is as follows:
许多现有的基于空间的 GNN 模型是归纳学习基于的 GNN 模型[16, 18],而 GraphSAGE[17]基于归纳学习。GraphSAGE 是一个用于生成完全未见节点潜在嵌入向量的通用归纳框架。在 GraphSAGE 模型中,该模型由 K 层组成,生成节点 v 在第 k 层嵌入向量的算法如下:
where
𝐖𝑘 is a weight parameter matrix to be trained and
𝜎 is a non-linear activation function (e.g., sigmoid function). The UPDATE function in GraphSAGE is a concatenation function multiplied with the weight matrix.
𝐖𝑘 是一个待训练的权重参数矩阵, 𝜎 是一个非线性激活函数(例如,Sigmoid 函数)。GraphSAGE 中的 UPDATE 函数是权重矩阵乘以拼接函数。The initial vector for node
v is the input node feature vector, and, as the number of layers increase, the embedding vector of node
v holds the information coming from farther neighbors. This means that, if
𝑘=0,
𝐡0𝑣 is
𝐱𝑣∈𝐗𝐯, and
𝐡𝐾𝑣 aggregates all the information of the neighbors within
K-hops from
v in the graph. Hamilton et al. [
17] showed the difference of performance among various AGGREGATE functions. For the AGGREGATE function, they used the MEAN operator (similar to GCN [
16]), an LSTM layer, and a POOL function based on the MAX operator with a weight matrix parameter. Unlike others, LSTM is not permutation-invariant, but shows strong performance and expressiveness as it trains additional neural networks [
17].
初始向量对于节点 v 是输入节点特征向量,随着层数的增加,节点 v 的嵌入向量包含来自更远邻居的信息。这意味着,如果 𝑘=0 , 𝐡0𝑣 是 𝐱𝑣∈𝐗𝐯 ,而 𝐡𝐾𝑣 聚合了从 v 在图中的 K-hop 范围内的所有邻居信息。Hamilton 等人[17]展示了各种 AGGREGATE 函数之间的性能差异。对于 AGGREGATE 函数,他们使用了 MEAN 运算符(类似于 GCN[16]),一个 LSTM 层,以及基于 MAX 运算符的权重矩阵参数的 POOL 函数。与其它方法不同,LSTM 不是排列不变的,但它在训练额外的神经网络[17]时表现出强大的性能和表达能力。 3.3.2. A GNN Model to Utilize Distance Weight Feature
3.3.2. 利用距离权重特征的 GNN 模型
A graph describing a real-world example may not only have node features, but also edge features. In spatial networks, the distance between two nodes can be expressed as an edge feature or the weight value of the graph [
25]. The edge weight values are an important feature in that they describe the relationship between nodes in a spatial graph. Under the first law of geography, neighboring nodes that are close to a target node should be given relatively high attention values compared to the other neighbors that are far apart from the target node [
12].
描述现实世界示例的图可能不仅具有节点特征,还具有边特征。在空间网络中,两个节点之间的距离可以表示为边特征或图的权重值[25]。边权重值是一个重要特征,因为它们描述了空间图中节点之间的关系。根据地理第一定律,与目标节点较近的邻近节点应比远离目标节点的其他邻近节点给予相对较高的关注值[12]。However, most of the existing GNN models do not leverage the edge feature in their networks. Studies that have utilized the edge feature in node and graph classification tasks have focused on multi-dimensional features, not single-dimension features like weight values in spatial networks [
26,
27]. Glimmer et al. [
26] proposed a model utilizing edge features in the message-passing process. However, their model is too general, since the message function
𝑀𝑡 is not a specific method and could be any function. A GNN model that can handle spatial networks consisting of nodes and distance weights is thereby needed.
然而,大多数现有的 GNN 模型没有利用其网络中的边特征。在节点和图分类任务中利用边特征的研究主要集中在多维特征,而不是像空间网络中的权重值这样的单维特征[26, 27]。Glimmer 等人[26]提出了一种在消息传递过程中利用边特征的模型。然而,由于消息函数 𝑀𝑡 不是一个特定方法,可以是任何函数,因此他们的模型过于通用。因此,需要一个能够处理由节点和距离权重组成的空间网络的 GNN 模型。We propose a new inductive learning-based GNN model named the Distance-Weighted Graph Neural Network (DWGNN). DWGNN is a GraphSAGE-based model in which an edge feature mechanism is applied in the message-passing process. Its target graph represents a spatial network where the distance between nodes is a one-dimensional weight value. When DWGNN aggregates the neighbor’s information, it assigns the attention values to neighboring nodes’ embedding vectors according to the relative distance from the target node. The update process of DWGNN is as follows.
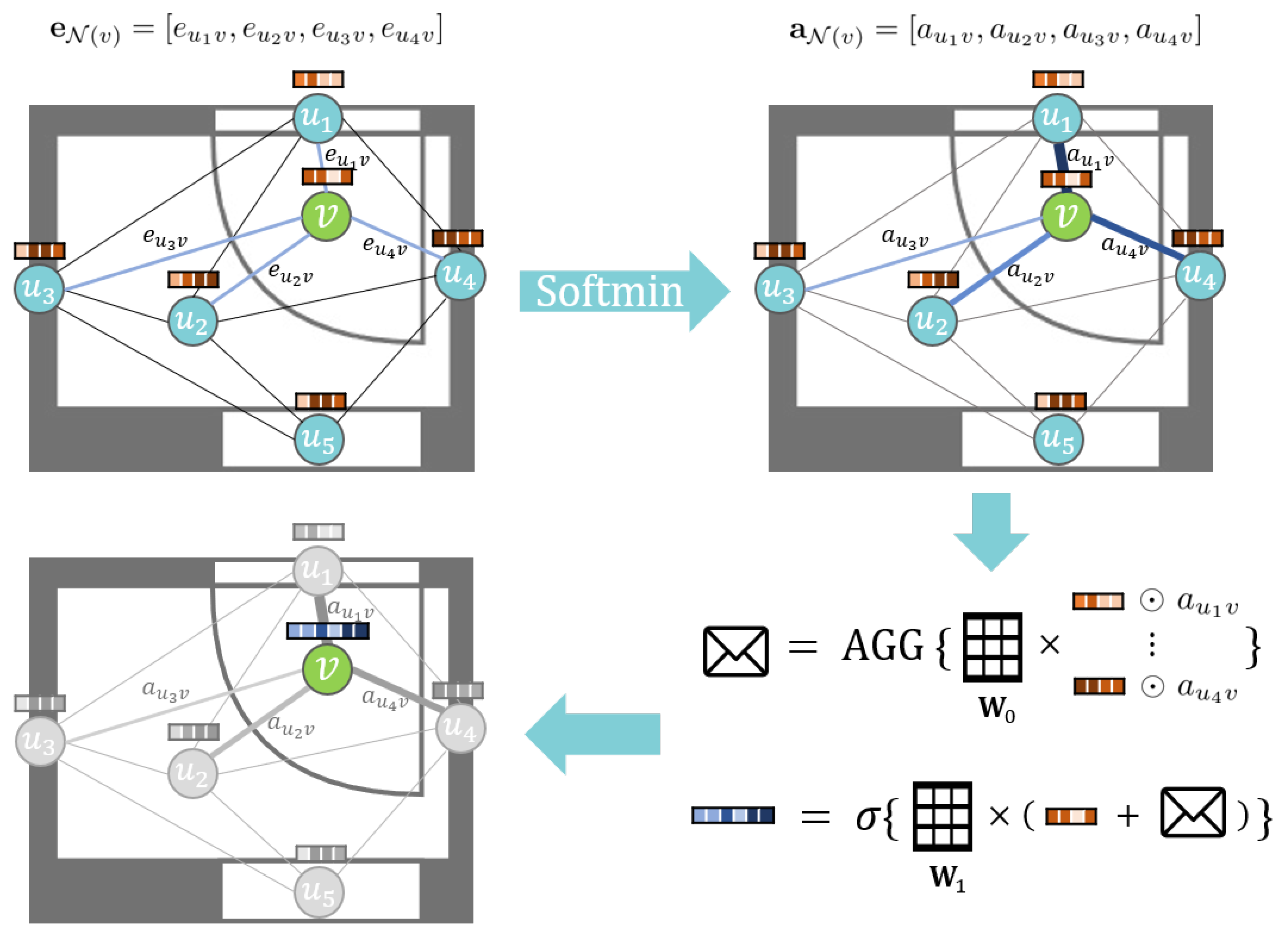
我们提出了一种基于归纳学习的 GNN 模型,命名为距离加权图神经网络(DWGNN)。DWGNN 是一种基于 GraphSAGE 的模型,在消息传递过程中应用了边特征机制。其目标图表示一个空间网络,其中节点之间的距离是一个一维权重值。当 DWGNN 聚合邻居的信息时,它会根据目标节点的相对距离将注意力值分配给邻居节点的嵌入向量。DWGNN 的更新过程如下。
where
𝐞𝒩(𝑣) is the distance weight vector of node
v and its neighboring node set
𝒩(𝑣) and ⊙ denotes element-wise multiplication. Softmin is a function that converts every element of
𝐞𝒩(𝑣) into an attention value. It is defined as follows,
𝐞𝒩(𝑣) 是节点 v 及其相邻节点集 𝒩(𝑣) 的距离权重向量,⊙ 表示逐元素乘法。Softmin 是一个将 𝐞𝒩(𝑣) 的每个元素转换为注意力值的函数。它定义如下,Similar to the softmax function, which converts each element of the input vector to a value between [0,1] and the sum of all converted values is equal to 1 such as a probability value, the softmin function returns a normalized vector where each element gets a larger attention value if its weight value is relatively smaller than others. This assigns nearby neighboring nodes a larger attention value compared to those far apart. In addition, similar to GraphSAGE, the AGGREGATE function of DWGNN can be chosen between various functions, such as SUM, MEAN, MAX, and LSTM. The update process of DWGNN is shown in . If the weights play a significant role in a spatial network, DWGNN can be an appropriate GNN model to analyze such graphs.
类似于 softmax 函数,它将输入向量的每个元素转换为介于 0#和所有转换值之和等于 1 之间的值,例如概率值,softmin 函数返回一个归一化向量,其中每个元素如果其权重值相对于其他元素较小,则获得更大的注意力值。这为相邻的邻近节点分配了比那些相距较远的节点更大的注意力值。此外,与 GraphSAGE 类似,DWGNN 的 AGGREGATE 函数可以在 SUM、MEAN、MAX 和 LSTM 等函数之间选择。DWGNN 的更新过程如图 4 所示。如果权重在空间网络中起着重要作用,DWGNN 可以是一个分析此类图的适当 GNN 模型。
Figure 4.
Visual illustration of the update process of node v (a door segment). The softmin function assigns respective attention values to each neighbor of v according to their distance to v (𝑒𝑢𝑖𝑣). Each node’s embedding vector at layer 𝑘−1 is element-wise multiplied with a respective attention value. They pass through a weight matrix 𝑊0 and aggregated to a message. This message is added to v’s embedding vector at layer 𝑘−1 and multiplied with the weight matrix 𝑊1. The result is the embedding vector of node v at layer k. In the Figure, 𝐚𝒩(𝑣) is the converted attention vector and 𝐀𝐆𝐆 is the AGGREGATE function.
图 4. 节点 v(门段)更新过程的视觉说明。Softmin 函数根据 v 的距离为 v 的每个邻居分配相应的注意力值( 𝑒𝑢𝑖𝑣 )。每个节点在第 1#层的嵌入向量与相应的注意力值逐元素相乘。它们通过权重矩阵 𝑊0 并聚合为一个消息。该消息添加到 v 在第 3#层的嵌入向量中,并与权重矩阵 𝑊1 相乘。结果是节点 v 在第 k 层的嵌入向量。在图中, 𝐚𝒩(𝑣) 是转换后的注意力向量, 𝐀𝐆𝐆 是聚合函数。
4. Results 4. 结果
4.1. Datasets 4.1. 数据集
To test and evaluate the proposed framework, we conducted experiments on two different floor plan benchmarks, together with one data-augmented dataset. We did not use the floor plan datasets which had been used in previous works, since their raster images had a lot of noise and/or the resolution was too low (e.g., R2V [
8], RF-P [
9]) or unable to be obtained (ILPIso [
20]). We will discuss applicability issues in detail in
Section 5. In what follows, we will address two different floor plan datasets we used in the experiments. Both datasets consist of basic structural classes and spatial element classes together with the object class. Object class is comprised of various furniture and installations placed in an indoor environment, such as cabinets, chairs, or toilets. Any other object not in a structural or spatial category will be assigned to the object class.
为了测试和评估所提出的框架,我们在两个不同的楼层平面基准上进行了实验,同时使用了一个数据增强的数据集。我们没有使用之前工作中使用过的楼层平面数据集,因为它们的栅格图像有很多噪声和/或分辨率太低(例如,R2V [8],RF-P [9])或无法获得(ILPIso [20])。我们将在第 5 节详细讨论适用性问题。在接下来的内容中,我们将讨论我们在实验中使用的两个不同的楼层平面数据集。这两个数据集都包括基本结构类别和空间元素类别以及对象类别。对象类别包括放置在室内环境中的各种家具和设施,如橱柜、椅子或洗手间。任何其他不在结构或空间类别中的对象将被分配到对象类别。The CubiCasa5K [
28] (CubiCasa) dataset consists of 5000 different apartment floor plans. The quality of the floor plan images varies from clean, noise-free ones to scribbled or noisy ones. They are divided into three categories: high quality, architectural high quality, and colorful. We used the SVG formatted labeled floor plan images hand-annotated by experts as input data, by converting them into raster image data. After we vectorized the polygons, we classified the polygons into eight classes: four structural element classes (walls, windows, doors, and stairs), three spatial element classes (rooms, porches, and outer-space), and the object class comprised of various symbols. We selected the 400 high-quality floor plan images and split them evenly into training and test sets.
CubiCasa5K [28](CubiCasa)数据集包含 5000 个不同的公寓平面图。平面图图像的质量从干净、无噪声的到涂鸦或噪声的都有。它们被分为三类:高质量、建筑高质量和彩色。我们使用专家手工标注的 SVG 格式标签平面图图像作为输入数据,通过将它们转换为栅格图像数据。在将多边形矢量化后,我们将多边形分为八类:四个结构元素类别(墙壁、窗户、门和楼梯)、三个空间元素类别(房间、门廊和外部空间)以及由各种符号组成的对象类别。我们选择了 400 张高质量平面图,并将它们平均分为训练集和测试集。The University of Seoul (UOS) dataset containing plans for seven floors of the 21st century building at the University of Seoul, was used to evaluate whether the framework is applicable to large-area floor plan data along with relatively small ones, such as CubiCasa5K. We exported the CAD floor plan data into raster data. We classified the elements of vector plans into nine classes: five structural element classes (including elevators), three spatial element classes (rooms, corridors, and X-rooms), and the object class. Though the number of plans is limited because of security issues, if the framework is able to generalize and classify the indoor elements in UOS, we can say that the framework works well with a smaller number of floor plans. We used a seven-fold cross-validation strategy. Each session consisted of six training plans and one plan for the test. The final result was averaged by all seven sessions.
首尔大学(UOS)数据集包含首尔大学 21 世纪建筑七层平面图,用于评估框架是否适用于大型区域平面图数据以及相对较小的数据,如 CubiCasa5K。我们将 CAD 平面图数据导出为栅格数据。我们将矢量平面图的元素分为九类:五个结构元素类别(包括电梯)、三个空间元素类别(房间、走廊和 X 房间)以及对象类别。由于安全问题,平面图数量有限,但如果框架能够泛化和分类 UOS 的室内元素,我们可以说框架与较少的平面图数量配合良好。我们使用了七折交叉验证策略。每个会话包括六个训练平面图和一个测试平面图。最终结果由所有七个会话的平均值得出。
4.2. GNN Models 4.2. GNN 模型
We implemented four GNN models for performance comparison. We conducted inductive learning experiments under the same conditions and settings. The following are the used GNN models.
我们实现了四个 GNN 模型以进行性能比较。我们在相同条件和设置下进行了归纳学习实验。以下是用到的 GNN 模型。
- (1)
GCN [
16]: Graph Convolution Networks aggregate the neighbor nodes of the target node using a symmetric normalized graph Laplacian
𝐃̃−12𝐀̃𝐃̃−12 made with a self-loop adjacency graph
𝐀̃=𝐀+𝐈 and a diagonal degree matrix
𝐃̃=∑𝑗𝐀𝑖𝑗̃. The embedding vectors of the target nodes are generated by summing the information of neighboring nodes and projecting onto a weight matrix. The update process of GCN is
GCN [16]:图卷积网络使用对称归一化图拉普拉斯算子 𝐃̃−12𝐀̃𝐃̃−12 通过自环邻接图 𝐀̃=𝐀+𝐈 和对角度矩阵 𝐃̃=∑𝑗𝐀𝑖𝑗̃ 聚合目标节点的邻接节点。目标节点的嵌入向量通过汇总邻接节点的信息并投影到权重矩阵中生成。GCN 的更新过程是
where
𝑐𝑣𝑢 is a normalization constant for the edge
(𝑣,𝑢) originating from
𝐃̃−12𝐀̃𝐃̃−12.
𝑐𝑣𝑢 是从 𝐃̃−12𝐀̃𝐃̃−12 出发的边 (𝑣,𝑢) 的归一化常数。- (2)
GIN [
18]: A Graph Isomorphism Network was proposed to maximize the discriminative and representational power of each node in a graph. It shows almost the same performance as the Weisfeiler–Lehman graph isomorphism test [
29]. We used MAX, MEAN, and SUM operations as the AGGREGATE function in our experiments. The update process of GIN is
图同构网络被提出以最大化图中每个节点的判别力和表示能力。它几乎与 Weisfeiler-Lehman 图同构测试[29]具有相同的性能。在我们的实验中,我们使用了 MAX、MEAN 和 SUM 操作作为聚合函数。GIN 的更新过程是
where
MLP𝑘 is a multi-layer perceptron placed at layer
k to maximize the discriminative power of the generated embedding vectors. Along with MLPs,
𝜖𝑘 is a scalar parameter at layer
k to be trained. We fixed
𝜖𝑘=0.
MLP𝑘 是放置在第 k 层的多层感知器,以最大化生成的嵌入向量的判别能力。除了 MLPs, 𝜖𝑘 还是在第 k 层需要训练的标量参数。我们固定了 𝜖𝑘=0 。- (3)
GraphSAGE [
17]: We used the same model as introduced in
Section 3.3.1 MEAN was excluded from the experiment because it does not differ much from the propagation rule of GCN. When using the POOL aggregator, a weight matrix was added prior to the MAX operation to increase the expressive power of the message function. The POOL aggregator is defined as follows:
GraphSAGE [17]:我们使用了第 3.3.1 节中介绍的同一种模型。由于 MEAN 与 GCN 的传播规则差异不大,因此将其排除在实验之外。在使用 POOL 聚合器时,在 MAX 操作之前添加了一个权重矩阵,以增加消息函数的表达能力。POOL 聚合器定义为如下:- (4)
DWGNN: The model developed by the authors and introduced in
Section 3.3.2 was implemented. MAX, MEAN, SUM, and LSTM were used for the AGGREGATE function in our experiment.
DWGNN:作者在 3.3.2 节中开发的模型已实现。在实验中,我们使用了 MAX、MEAN、SUM 和 LSTM 作为 AGGREGATE 函数。
4.3. Implementation Details
4.3. 实现细节
In our experiment, each floor plan image of the datasets was vectorized and labeled according to the class conditions described earlier. The parameters used in the vectorization process were the minimum area parameter
m as 20 and
t as 2. All the node and edge features in the graphs were scaled using the standardization technique. To train the GNN models, we used the Adam optimizer with an initial learning rate of 0.01. Batch normalization [
30] was applied to every hidden layer for CubiCasa. The number of hidden layers was six for every GNN model, and the MLPs had two layers for the GIN [
31]. The hyper-parameters for experiments were: (1) The number of hidden dimensions for the hidden layers was fixed to 128; (2) for CubiCasa, mini-batches of 10 graphs were set for each iteration and no mini-batches were set for UOS, as we used cross-validation strategy for it; (3) the number of epochs was set to 1000 for all GNN models except inductive learning-based models with a LSTM aggregator (set to 300). Since the LSTM has more parameters to train, the epochs of the inductive learning-based models with a LSTM aggregator was set lower than that of other models.
在我们的实验中,数据集的每一张楼层平面图都根据前面描述的类别条件进行了矢量化并标注。矢量化过程中使用的参数是面积参数 m 的最小值 20 和 2。图中所有节点和边特征都使用标准化技术进行了缩放。为了训练 GNN 模型,我们使用了初始学习率为 0.01 的 Adam 优化器。对于 CubiCasa,在每个隐藏层应用了批量归一化[30]。每个 GNN 模型的隐藏层数量为六个,而 GIN[31]的 MLPs 有两个层。实验的超参数如下:(1)隐藏层的隐藏维度数固定为 128;(2)对于 CubiCasa,每个迭代设置 10 个图的迷你批次,而对于 UOS 没有设置迷你批次,因为我们对其使用了交叉验证策略;(3)所有 GNN 模型除了基于 LSTM 聚合器的归纳学习模型(设置为 300)外,均将迭代次数设置为 1000。由于 LSTM 有更多的参数需要训练,因此具有 LSTM 聚合器的基于归纳学习模型的迭代次数低于其他模型。The hardware characteristics used for the experiments were an Intel i7-9700KF CPU, an NVIDIA GeForce GTX 1660 Ti GPU, and 64 Gb of RAM. For the code implementation, we used the Rasterio package for vectorization and the Shapely, GeoPandas, NetworkX packages for the creation and management of polygon vectors and graphs. GNN models were built using the Deep Graph Library [
32] with PyTorch backend. The code is available at
https://github.com/LymanSong/FP_GNN (accessed on 22 February 2021).
实验中使用的硬件特性包括英特尔 i7-9700KF CPU、NVIDIA GeForce GTX 1660 Ti GPU 和 64 Gb 的 RAM。对于代码实现,我们使用了 Rasterio 包进行向量化,以及 Shapely、GeoPandas、NetworkX 包用于创建和管理多边形向量和图。使用 Deep Graph Library [32]和 PyTorch 后端构建了 GNN 模型。代码可在 https://github.com/LymanSong/FP_GNN(2021 年 2 月 22 日访问)获取。 4.4. Experiment on the Cubicasa Dataset
4.4. 在 Cubicasa 数据集上进行实验
shows the results of the predicted classes of elements in the CubiCasa test set using different GNN models and aggregate methods. Among the GNN models, GraphSAGE showed the highest accuracy. In addition, the LSTM aggregate method showed the highest results.
表 1 显示了使用不同 GNN 模型和聚合方法预测 CubiCasa 测试集中元素类别的结果。在 GNN 模型中,GraphSAGE 的准确率最高。此外,LSTM 聚合方法的结果最高。
Table 1.
Class-wise accuracy comparison by different GNN models on the CubiCasa dataset (micro-averaged F1 score). AGG stands for the AGGREGATE method.
表 1. 不同 GNN 模型在 CubiCasa 数据集上的类别准确率比较(微平均 F1 分数)。AGG 代表聚合方法。
The accuracy for stairs was relatively low in all models. This is because, given that stairs are depicted as a set of rectangular polygons, rectangles often appear in different elements’ classes. In addition, stair polygons with different shapes share one single class, and the number of plans including stairs is significantly lower. On the other hand, windows and doors have high accuracy rates, apparently because each of them share a highly defined structure shape in the drawing style of CubiCasa.
楼梯在所有模型中的准确性相对较低。这是因为,由于楼梯被描绘为一系列矩形多边形,矩形经常出现在不同元素类中。此外,不同形状的楼梯多边形共享一个单一类别,并且包含楼梯的平面数量显著较低。另一方面,窗户和门的准确性率很高,这显然是因为它们在 CubiCasa 的绘图风格中共享一个高度定义的结构形状。
We can find that, compared to the transductive learning-based models (GCN and GIN), the inductive learning-based models (GraphSAGE and DWGNN) performed well on recognizing spatial elements. In , DWGNN with the SUM method slightly underperformed compared to GIN with the SUM method, but in the case of spatial elements (rooms, porches, and outer spaces) it classified better than GIN with SUM. If we divide the element classes into two classes (spatial and non-spatial) the inductive learning-based models found the spatial classes much better than the transductive learning-based models did. This means that inductive models can generalize the characteristics of classes well and easily find the dominant features on unseen data, such as predicting whether it is spatial or non-spatial by looking at the area attribute.
我们可以发现,与基于归纳学习的模型(GraphSAGE 和 DWGNN)相比,基于归纳学习的模型在识别空间元素方面表现良好。在表 1 中,与 SUM 方法相比,DWGNN 略逊于 GIN,但在空间元素(房间、门廊和外部空间)的分类上优于 GIN。如果我们把元素类别分为两类(空间和非空间),归纳学习模型在空间类别上的表现比基于归纳学习的模型要好得多。这意味着归纳模型可以很好地泛化类别的特征,并容易在未见数据中找到主导特征,例如通过查看面积属性来预测它是空间还是非空间。
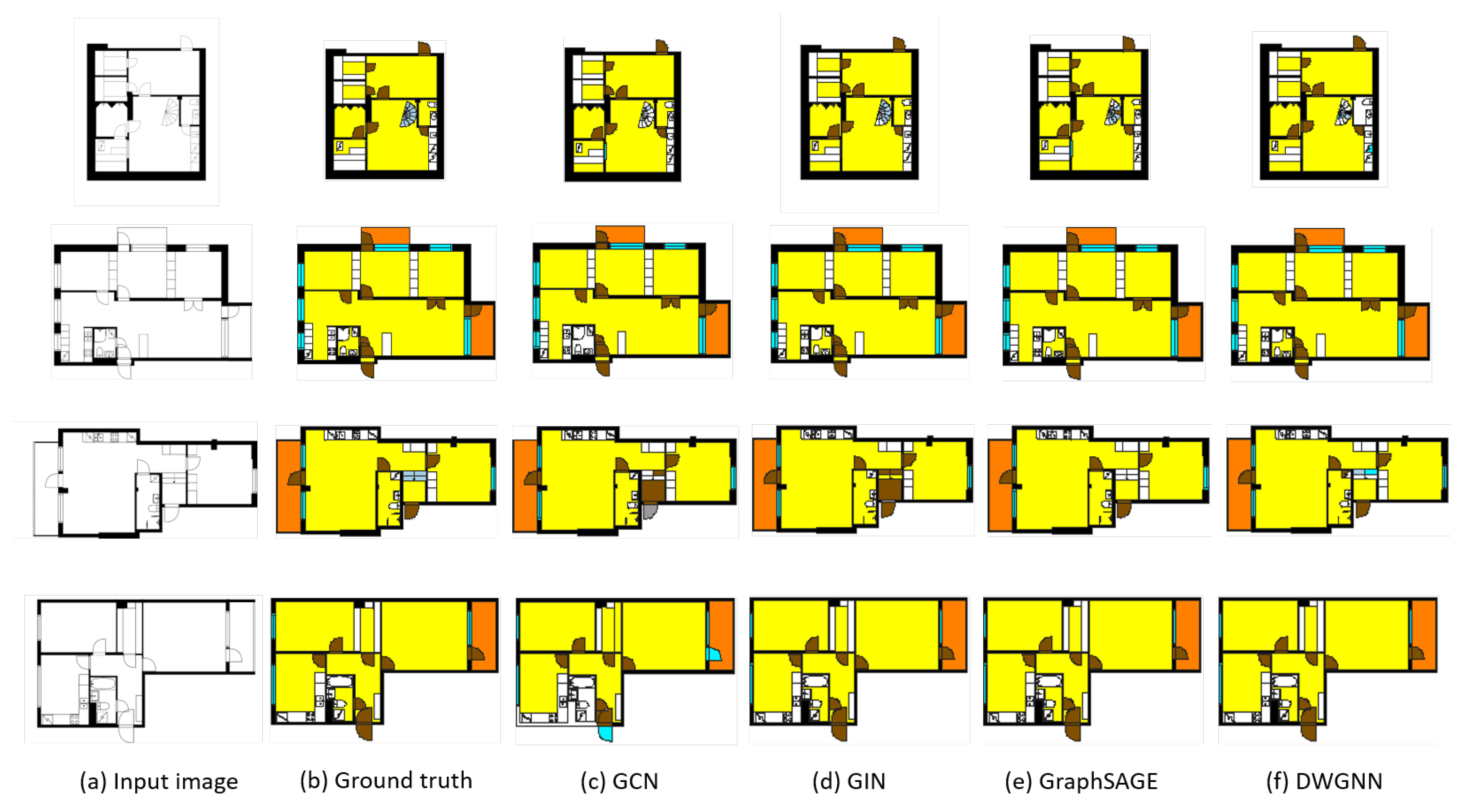
shows the results of visualizing examples of floor plans analyzed through the proposed framework. The framework first vectorizes the input images and converts them into RAGs. The trained GNN models then take these graphs as inputs and extract features to predict the classes of polygons. Compared to the ground truths, inductive learning-based models can classify the basic classes and spatial elements well. On the other hand, the transductive learning-based models fail to predict some basic and spatial element classes. In particular, GCN and GIN were unable to find the doors and walls correctly. As stated earlier, all models classified the stairs incorrectly.
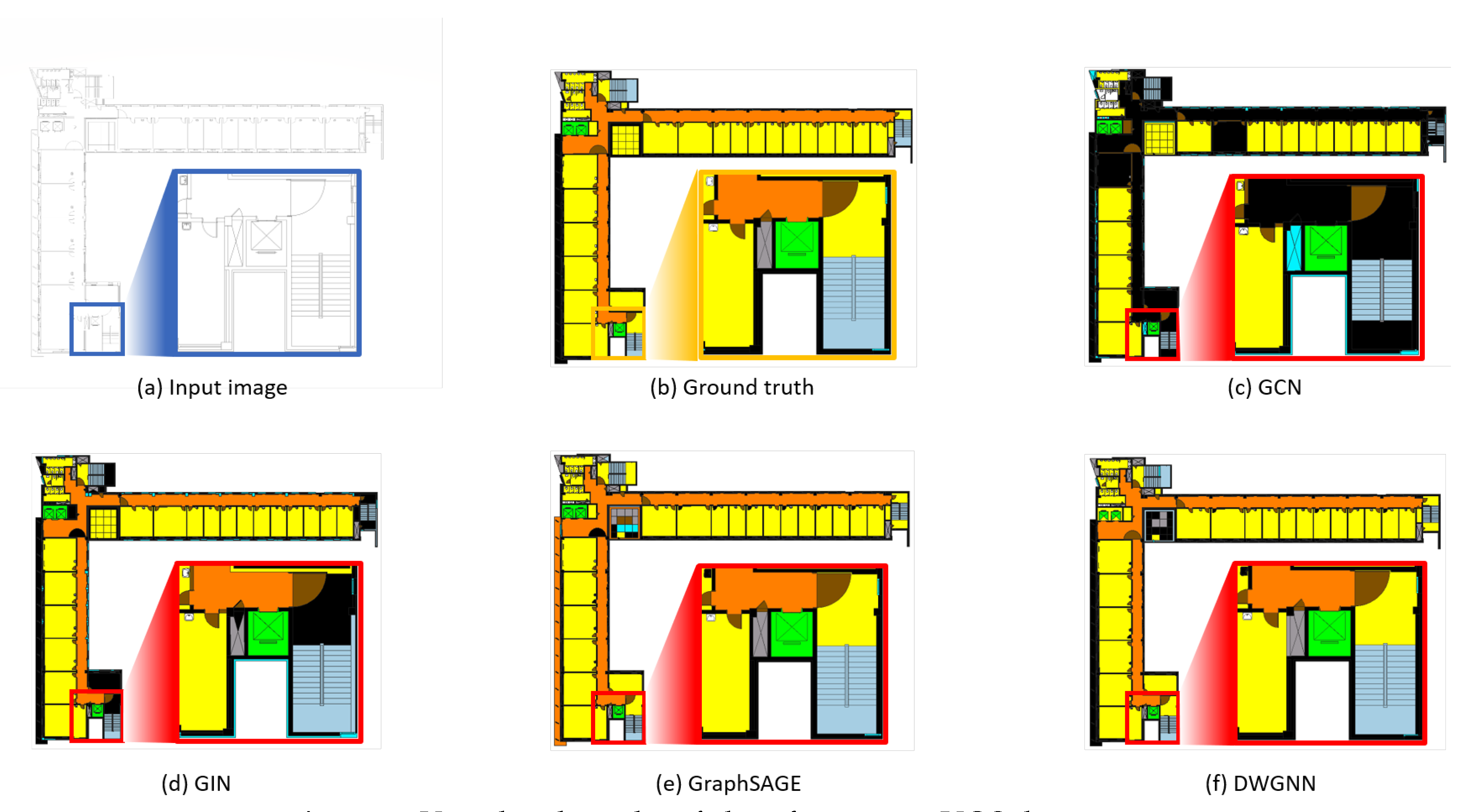
图 5 显示了通过所提出框架分析的地板平面示例的可视化结果。该框架首先将输入图像向量化并转换为 RAGs。训练好的 GNN 模型将这些图作为输入并提取特征以预测多边形的类别。与真实情况相比,基于归纳学习的模型在分类基本类别和空间元素方面表现良好。另一方面,基于归纳学习的模型无法预测一些基本和空间元素类别。特别是,GCN 和 GIN 无法正确找到门和墙。如前所述,所有模型都将楼梯分类错误。
Figure 5.
Examples of input image (a) and ground truth (b), and visual comparison of indoor element classification results by GNN models for transductive learning (c,d) and inductive learning models (e,f). The element class “outer space” is erased for visibility.
图 5. 输入图像(a)和真实情况(b)的示例,以及 GNN 模型在归纳学习(c,d)和演绎学习模型(e,f)对室内元素分类结果的视觉比较。为了可见性,元素类别“外太空”已被删除。
4.5. Experiment on Large and Complicated Floor Plans: Uos and Uos-Aug
4.5. 在大型和复杂的平面图上进行实验:Uos 和 Uos-Aug
Small-area floor plans have fewer polygons and their RAGs have a relatively simple structure compared to large and complex buildings. We conducted experiments on large and complicated floor plans to test our framework. The floor plans of the UOS dataset were large and complicated, thus resulting in many polygons with complex relationships. The number of floor plans in the UOS dataset was seven, so we used a seven-fold cross-validation strategy. Each session consisted of six plans for training and one for testing. shows the results of the experiment on the UOS dataset.
小面积平面图多边形较少,与大型复杂建筑相比,它们的 RAG 结构相对简单。我们对大型复杂的平面图进行了实验,以测试我们的框架。UOS 数据集的平面图大且复杂,因此产生了许多具有复杂关系的多边形。UOS 数据集中的平面图数量为七个,因此我们采用了七折交叉验证策略。每个会话包括六个用于训练的平面图和一个用于测试的平面图。表 2 显示了 UOS 数据集上实验的结果。
Table 2.
Class-wise accuracy comparison on different GNN models on the UOS data set.
表 2. 在 UOS 数据集上不同 GNN 模型按类别准确率比较。
The overall accuracy score was lower than that of the CubiCasa dataset. The spatial element class underperformed compared to the CubiCasa dataset since non-spatial classes in the UOS dataset had large doors and lifts, whose area was large and could be added to the spatial class. Like the CubiCasa dataset, transductive learning-based models underperformed compared to the inductive learning-based models. Unlike the previous experiment, GraphSAGE with the LSTM aggregator was not ranked first place in every element class, and for stairs and hallways, DWGNN did better than GraphSAGE with LSTM (see ). This is because the shapes of stair elements are more defined compared to that of CubiCasa, and DWGNN could generalize the structured set of polygons and find the patterns of their formation better than GraphSAGE. For the hallways, they tend to be linked to many other elements with respective distances, and thus make DWGNN easy to generalize regarding the characteristics of hallways by taking the attention values into account (shown in ).
总体准确率得分低于 CubiCasa 数据集。与 CubiCasa 数据集相比,空间元素类别表现不佳,因为 UOS 数据集中的非空间类别有大型门和电梯,其面积较大,可以添加到空间类别中。与 CubiCasa 数据集类似,基于归纳学习的模型在表现上不如基于归纳学习的模型。与之前的实验不同,GraphSAGE 使用 LSTM 聚合器在每个元素类别中并未排名第一,对于楼梯和走廊,DWGNN 比 GraphSAGE 使用 LSTM 表现更好(见表 2)。这是因为楼梯元素的形状比 CubiCasa 更明确,DWGNN 能够更好地泛化结构化的多边形集合并找到其形成模式,比 GraphSAGE 更好。对于走廊,它们往往与许多其他元素通过相应的距离相连接,因此通过考虑注意力值(如图 6 所示),DWGNN 可以轻松泛化走廊的特征。
Figure 6.
Visualized results of classification on UOS dataset.
图 6. UOS 数据集上分类的可视化结果。
As the number of plans in the UOS dataset was limited, the generalization of the characteristics of classes was difficult. If a GNN model has a node that has never been seen before, the node will not only affect itself, but also the neighboring nodes up to K hops away. This occurs because GNN aggregates the feature of a much wider range of nodes as the number of layers increases. In addition, the GNN model may simply memorize the training dataset as the number of plans is limited. To alleviate these problems, we augmented the UOS dataset using an affine transformation. For all points in the set of floor plan polygons, a point was scaled about the origin with a scale factor of 0.7, then flipped over the y-axis. After that, we rotated the polygons 90 degrees counterclockwise (see ). The transformation formula is as follows.
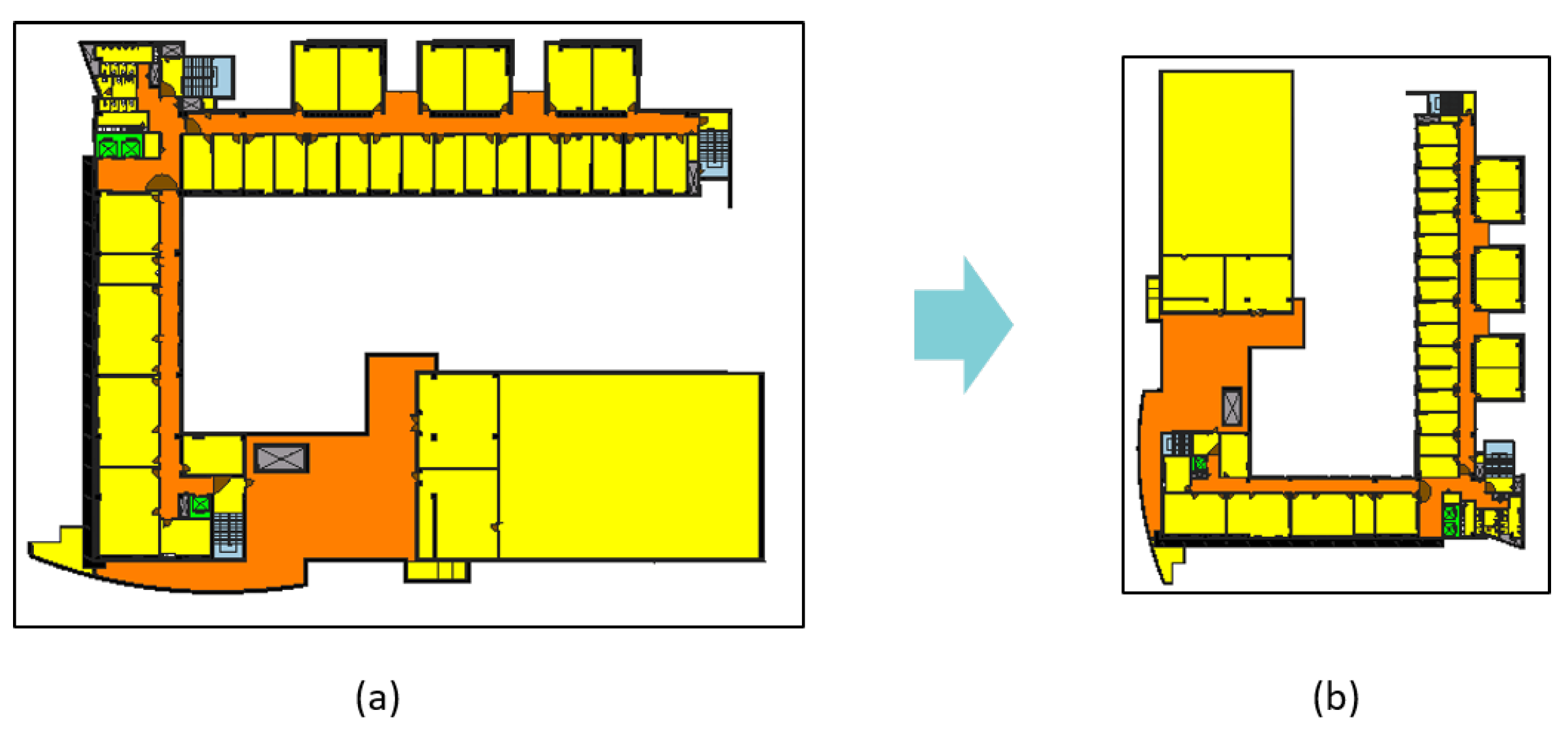
由于 UOS 数据集中计划的数量有限,类别的特征泛化困难。如果一个 GNN 模型有一个之前从未见过的节点,该节点不仅会影响自身,还会影响距离 K 跳的邻近节点。这是因为随着层数的增加,GNN 会聚合更广泛范围内节点的特征。此外,由于计划数量有限,GNN 模型可能只是简单地记忆训练数据集。为了缓解这些问题,我们使用仿射变换对 UOS 数据集进行了增强。对于楼层平面多边形集合中的所有点,以原点为中心进行缩放,缩放因子为 0.7,然后沿 y 轴翻转。之后,我们将多边形逆时针旋转 90 度(见图 7)。变换公式如下。
Figure 7.
Example of data augmentation. The original plan (
a) gets transformed by Equation (
9), and returns an augmented plan (
b).
图 7. 数据增强示例。原始计划(a)通过方程(9)变换,并返回增强计划(b)。
We formed a new dataset UOS-aug consisting of the seven augmented plans with the original plans from UOS. Because classification performance was improved through data augmentation, we can derive that the results of the GNN model are invariant to scale and rotation. In addition, this proves that the GNN model learns a pattern of updating the embedding vectors of that node in relationship with the neighbors of each node, rather than memorizing the structure of the drawing. The results are shown in .
我们构建了一个新的数据集 UOS-aug,它由 UOS 的原始计划和七个增强计划组成。由于数据增强提高了分类性能,我们可以得出结论,GNN 模型的结果对尺度和旋转是不变的。此外,这也证明了 GNN 模型学习了一种更新节点嵌入向量的模式,这种模式与每个节点的邻居相关,而不是记住图形的结构。结果如表 3 所示。
Table 3.
Class-wise accuracy comparison on different GNN models on the UOS-aug data set.
表 3. 在 UOS-aug 数据集上不同 GNN 模型按类别准确率比较。
The results improved compared to . Though the augmented plans have gone through many changes, they worked in a complementary manner with the original plans, which means that the GNN models are invariant to scale and rotation. This proves that the GNN models classify their nodes using the relationship and patterns among nodes and features within each graph, not the formation and arrangement of nodes.
与表 2 相比,结果有所改善。尽管增强计划经历了许多变化,但它们与原始计划以互补的方式工作,这意味着 GNN 模型对规模和旋转不变。这证明了 GNN 模型是通过每个图中的节点之间的关系和模式以及节点内的特征来分类它们的节点,而不是节点的形成和排列。
5. Discussion 5. 讨论
The contributions of our work are as follows. First, we developed a raster to vectorization process for floor plan images independent of the drawing style. With appropriate image pre-processing methods, it can convert any type of floor plan image into polygon vector data. By vectorizing the floor plan image before pixel segmentation, we were able to capture not only structural elements, but symbols and spatial elements without losing shape information. Second, to classify the polygons, we employed the Graph Neural Network approach. The GNN models are invariant to scale and rotation since GNN takes input as a graph, and the graph data structure has no fixed permutation of nodes. Utilizing GNN makes the framework robust and easy to generalize floor plan datasets of any style. Third, we defined the need for inductive learning GNN models for floor plan element classification tasks and, among many GNN models, we chose an appropriate one (GraphSAGE). Further, we developed a new GNN model taking the distance weight value into account in the message passing process using the softmin function.
我们的工作贡献如下。首先,我们开发了一种独立于绘图风格的楼层平面图像光栅到矢量化过程。通过适当的图像预处理方法,它可以转换任何类型的楼层平面图像为多边形矢量数据。通过在像素分割之前矢量化楼层平面图像,我们不仅能够捕捉到结构元素,还能捕捉到符号和空间元素,而不丢失形状信息。其次,为了对多边形进行分类,我们采用了图神经网络(GNN)方法。由于 GNN 将输入作为图,并且图数据结构没有节点固定排列,因此 GNN 模型对尺度和旋转不变。利用 GNN 使框架鲁棒且易于泛化任何风格的楼层平面数据集。第三,我们定义了在楼层平面元素分类任务中需要归纳学习 GNN 模型,并在众多 GNN 模型中选择了适当的一个(GraphSAGE)。进一步地,我们开发了一个新的 GNN 模型,在消息传递过程中使用软最大(softmax)函数考虑距离权重值。
While the results showed that our framework can detect and classify multi-labeled floor plan elements, a few limitations were derived as follows. The features currently used in the feature matrix of polygons are significant, but if we use additional feature information that fully describes individual polygons among different types of floor plan elements, it would be possible to do additional classification. The proposed framework outputs the result in a vector format, which facilitates its use in additional research or real-world applications. For example, Zeng et al. [
10] demonstrated the 3D models of the results from their method, and the output of the proposed framework is already vector-type data, making it even easier for 3D modeling.
虽然结果表明我们的框架可以检测和分类多标签平面图元素,但以下是一些局限性。目前用于多边形特征矩阵中的特征是显著的,但如果我们使用能够完全描述不同类型平面图元素中各个多边形的附加特征信息,则可以进行额外的分类。所提出的框架以矢量格式输出结果,这有助于其在额外研究或实际应用中的使用。例如,Zeng 等人[10]展示了他们方法的结果的 3D 模型,而所提出的框架的输出已经是矢量类型数据,这使得 3D 建模更加容易。Unlike CNN-based models, which are robust to noisy images, the application of the proposed framework to noisy or low-resolution images is difficult. Especially in the image pre-processing phase, the output is highly dependent on the noise and the resolution. For example, if the pixel values of the symbol are uneven due to low resolution, doors tend to lose the exact arc line and fail to get converted into a polygon. To overcome these limitations, an image generation model can be applied and used in the pre-processing step. However, due to the nature of the generative model, it is difficult to expect detailed improvement at the pixel level. In addition, our framework does not utilize text information in the image, thus rendering impossible the use of semantic information, that explicitly indicates the nature of each object.
与基于 CNN 的模型相比,这些模型对噪声图像具有鲁棒性,将所提出的框架应用于噪声或低分辨率图像是困难的。特别是在图像预处理阶段,输出高度依赖于噪声和分辨率。例如,如果由于低分辨率导致符号的像素值不均匀,门往往会失去精确的弧线,并且无法转换为多边形。为了克服这些限制,可以应用图像生成模型并在预处理步骤中使用。然而,由于生成模型的本性,很难期望在像素级别上实现详细的改进。此外,我们的框架没有利用图像中的文本信息,因此使得使用明确指示每个对象性质的语义信息变得不可能。
In most experiments, the DWGNN showed slightly lower accuracy than GraphSAGE. It is because, on the RAG conversion stage, the node of the graph corresponds to the centroids of the polygons and the weight value is calculated between the coordinates of the pair of nodes, thus preventing them from holding the shape information of the polygons. Especially for walls or outer space, most of the node coordinates that represent polygons are often situated where the actual polygon is not located. To alleviate this, DWGNN uses the softmin function to assign the attention values; however, the meaningless edge features still prevent the model from being trained and predicting the classes correctly. With the nature of DWGNN, we think that it can be an appropriate model for solving combinatorial optimization problems in spatial networks, such as the traveling salesman problem or vehicular routing problems, rather than for graphs with polygon nodes.
在大多数实验中,DWGNN 的准确率略低于 GraphSAGE。这是因为,在 RAG 转换阶段,图中的节点对应于多边形的质心,权重值是在节点对的坐标之间计算的,从而阻止它们保留多边形的形状信息。特别是对于墙壁或外部空间,代表多边形的节点坐标通常位于实际多边形不存在的位置。为了缓解这一点,DWGNN 使用 softmax 函数分配注意力值;然而,无意义的边特征仍然阻止模型进行训练和正确预测类别。根据 DWGNN 的性质,我们认为它可以是解决空间网络中组合优化问题(如旅行商问题或车辆路径问题)的适当模型,而不是多边形节点图。
6. Conclusions 6. 结论
This paper presents a new framework for extracting and classifying the elements in a floor plan. Unlike previous approaches that first segment the floor plan image, our method vectorizes the floor plan images and converts the polygon set into an RAG. The model then employs a GNN to classify the nodes in the graph according to their unique features and neighborhood relationship. Inductive learning was conducted on the floor plan graphs in order to predict completely unseen graphs. Our framework classifies not only basic element and symbol classes but also spatial elements such as rooms, with resulting vector format outputs to minimize the abstraction and loss of shape information. To evaluate the performance of the proposed framework, we performed experiments on two floor plan datasets with different areas and distributions and one data augmented dataset. Results showed high accuracy rate on the classification task with the expressive power of the final output. By comparing various GNN models, we also found that inductive learning-based GNN models outperform transductive learning-based models. As further research, we will find a way to handle low-resolution floor plan images and improve the classification performance by extracting additional features.
本文提出了一种提取和分类平面图元素的新框架。与先前的先对平面图图像进行分割的方法不同,我们的方法将平面图图像矢量化,并将多边形集转换为 RAG。然后,模型使用 GNN 根据节点的独特特征和邻域关系对图中的节点进行分类。在平面图图上进行归纳学习,以预测完全未见过的图。我们的框架不仅对基本元素和符号类别进行分类,还对空间元素(如房间)进行分类,以最小化抽象和形状信息的损失。为了评估所提出框架的性能,我们在具有不同面积和分布的两个平面图数据集和一个数据增强数据集上进行了实验。结果表明,在分类任务中具有较高的准确率,并且最终输出的表达能力较强。通过比较各种 GNN 模型,我们还发现基于归纳学习的 GNN 模型优于基于归纳学习的模型。 作为进一步研究,我们将找到一种处理低分辨率平面图的方法,并通过提取额外特征来提高分类性能。
Author Contributions 作者贡献
Conceptualization, Jaeyoung Song; methodology, Jaeyoung Song; software, Jaeyoung Song; validation, Jaeyoung Song; investigation, Jaeyoung Song; data curation, Jaeyoung Song; writing—original draft preparation, Jaeyoung Song; writing—review and editing, Jaeyoung Song and Kiyun Yu; visualization, Jaeyoung Song; supervision, Kiyun Yu; project administration, Kiyun Yu; funding acquisition, Kiyun Yu. All authors have read and agreed to the published version of the manuscript.
概念化,宋佳映;方法,宋佳映;软件,宋佳映;验证,宋佳映;调查,宋佳映;数据整理,宋佳映;写作—原始草案准备,宋佳映;写作—审阅和编辑,宋佳映和鱼基云;可视化,宋佳映;监督,鱼基云;项目管理,鱼基云;资金获取,鱼基云。所有作者已阅读并同意手稿的发表版本。
Funding 资助
This research was supported by a grant(21NSIP-B135746-05) from National Spatial Information Research Program (NSIP) funded by Ministry of Land, Infrastructure and Transport of Korean government.
这项研究得到了韩国政府国土交通部资助的国家空间信息研究计划(NSIP)的资助(21NSIP-B135746-05)。
Data Availability Statement
数据可用性声明
No applicable. 无适用项。
Conflicts of Interest 利益冲突
The authors declare no conflict of interest.
作者声明不存在利益冲突。
References 参考文献
- Dosch, P.; Tombre, K.; Ah-Soon, C.; Masini, G. A complete system for the analysis of architectural drawings. Int. J. Doc. Anal. Recog. 2000, 3, 102–116. [Google Scholar] [CrossRef]
Dosch, P.; Tombre, K.; Ah-Soon, C.; Masini, G. 完整的建筑图纸分析系统。国际文档分析与识别杂志,2000,3,102–116。[谷歌学术][交叉引用] - Macé, S.; Locteau, H.; Valveny, E.; Tabbone, S. A system to detect rooms in architectural floor plan images. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010; pp. 167–174. [Google Scholar]
Macé, S.; Locteau, H.; Valveny, E.; Tabbone, S. 一种用于检测建筑平面图像中房间的系统。在第九届 IAPR 国际文档分析系统研讨会论文集中,波士顿,马萨诸塞州,美国,2010 年 6 月 9-11 日;第 167-174 页。[谷歌学术] - Lu, T.; Yang, H.; Yang, R.; Cai, S. Automatic analysis and integration of architectural drawings. Int. J. Doc. Anal. Recog. 2007, 9, 31–47. [Google Scholar] [CrossRef]
卢,T.;杨,H.;杨,R.;蔡,S. 建筑图纸的自动分析与集成。国际文档分析与识别杂志,2007,9,31–47。[谷歌学术][交叉引用] - Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Automatic room detection and room labeling from architectural floor plans. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems. Gold Coast, Queensland, Australia, 27–29 March 2012; pp. 167–174. [Google Scholar]
艾哈迈德,S.;利维克,M.;韦伯,M.;邓格尔,A. 从建筑平面图中自动检测和标记房间。在 2012 年第 10 届 IAPR 国际文档分析系统研讨会论文集中。澳大利亚昆士兰州黄金海岸,2012 年 3 月 27-29 日;第 167-174 页。[谷歌学术] - Barducci, A.; Marinai, S. Object recognition in floor plans by graphs of white connected components. In Proceedings of the 21st International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012; pp. 298–301. [Google Scholar]
巴杜奇,A.;马里奈,S. 通过白色连通组件图在平面图中进行物体识别。在 2012 年 11 月 11 日至 15 日于日本茨城举行的第 21 届国际模式识别会议论文集;第 298-301 页。[谷歌学术] - De, P. Vectorization of Architectural Floor Plans. Twelfth Int. Conf. Contemp. Comput. 2019, 10, 1–5. [Google Scholar]
德,P. 建筑平面图的矢量化。第十二届国际当代计算机会议,2019,10,1–5。[谷歌学术] - De las Heras, L.P.; Ahmed, S.; Liwicki, M.; Valveny, E.; Sánchez, G. Statistical segmentation and structural recognition for floor plan interpretation. Int. J. Doc. Anal. Recog. 2014, 17, 221–237. [Google Scholar] [CrossRef]
德拉斯埃拉斯,L.P.;艾哈迈德,S.;利维克,M.;瓦伦尼,E.;桑切斯,G. 地面图解释的统计分割和结构识别。国际文档分析与识别杂志,2014,17,221–237。[谷歌学术][交叉引用] - Liu, C.; Wu, J.; Kohli, P.; Furukawa, Y. Raster-to-vector: Revisiting floorplan transformation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 142–149. [Google Scholar]
刘, C.; 吴, J.; 科利, P.; 古鲁卡瓦, Y. 栅格到矢量:重新审视布局转换。在 IEEE 国际计算机视觉会议论文集中,威尼斯,意大利,2017 年 10 月 22 日至 29 日;第 142-149 页。[谷歌学术] - Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Toyoda Auditorium, Nagoya University, Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar]
道奇,S.;徐,J.;斯特恩,B. 解析平面图。在 2017 年第十五届 IAPR 国际机器视觉应用会议(MVA)论文集中,名古屋大学丰田讲堂,名古屋,日本,2017 年 5 月 8-12 日;第 358-361 页。[谷歌学术] - Zeng, Z.; Li, X.; Yu, Y.K.; Fu, C.W. Deep Floor Plan Recognition Using a Multi-Task Network with Room-Boundary-Guided Attention. In Proceedings of the IEEE International Conference on Computer Vision, COEX Convention Center, Seoul, Korea, 2 October–11 November 2019; pp. 9096–9104. [Google Scholar]
曾,Z.;李,X.;余,Y.K.;傅,C.W. 基于房间边界引导注意力的多任务网络深度楼层平面识别。在 2019 年 10 月 2 日至 11 月 11 日韩国首尔 COEX 会议中心举行的 IEEE 国际计算机视觉会议论文集中;第 9096-9104 页。[谷歌学术] - Zlatanova, S.; Li, K.J.; Lemmen, C.; Oosterom, P. Indoor Abstract Spaces: Linking IndoorGML and LADM. In Proceedings of the 5th International FIG 3D Cadastre Workshop, Athens, Greece, 18–20 October 2016; pp. 317–328. [Google Scholar]
Zlatanova, S.; Li, K.J.; Lemmen, C.; Oosterom, P. 室内抽象空间:连接室内 GML 和 LADM。在第 5 届国际国际测量师联合会 3D 地籍研讨会论文集中,希腊雅典,2016 年 10 月 18-20 日;第 317-328 页。[谷歌学术] - Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 2016, 46 (Suppl. 1), 234–240. [Google Scholar] [CrossRef]
Tobler, W.R. 模拟底特律地区城市增长的计算机电影。经济地理学,2016,46(增刊 1),234–240。[谷歌学术][交叉引用] - Dominguez, B.; García, Á.L.; Feito, F.R. Semiautomatic detection of floor topology from CAD architectural drawings. Comput. Aided Des. 2012, 44, 367–378. [Google Scholar] [CrossRef]
Dominguez, B.; García, Á.L.; Feito, F.R. 从 CAD 建筑图纸中半自动检测地板拓扑结构。计算机辅助设计。2012,44,367–378。[谷歌学术][交叉引用] - Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
戈里,M.;蒙法迪尼,G.;斯卡塞利,F. 图域学习的新模型。在 2005 年 IEEE 国际神经网络联合会议论文集,加拿大魁北克省蒙特利尔,2005 年 7 月 31 日至 8 月 4 日;第 2 卷,第 729-734 页。[谷歌学术] - Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. Learn. Syst. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. 图神经网络模型。IEEE 交易神经网路学习系统 2009,20,61–80。[谷歌学术][交叉引用][PubMed][绿色版本] - Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
Kipf, T.N.; Welling, M. 基于图卷积网络的半监督分类。在 2017 年 4 月 24 日至 26 日在法国图尔永举行的国际学习表示会议(ICLR)论文集中。[谷歌学术] - Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
汉密尔顿,W.;英,Z.;莱斯科夫,J. 大图上的归纳表示学习。在《神经信息处理系统进展 30(NIPS 2017)》会议论文集中,美国加州长滩,2017 年 12 月 4-9 日;第 1024-1034 页。[谷歌学术] - Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
徐,K.;胡,W.;莱斯科夫,J.;耶格尔卡,S. 图神经网络有多强大?arXiv 2018,arXiv:1810.00826. [谷歌学术] - Hu, R.; Huang, Z.; Tang, Y.; van Kaick, O.; Zhang, H.; Huang, H. Graph2Plan: Learning Floorplan Generation from Layout Graphs. arXiv 2020, arXiv:2004.13204. [Google Scholar] [CrossRef]
胡,R.;黄,Z.;唐,Y.;范凯克,O.;张,H.;黄,H. 图 2 计划:从布局图中学习平面图生成。arXiv 2020,arXiv:2004.13204。[谷歌学术][交叉引用] - Renton, G.; Héroux, P.; Gaüzère, B.; Adam, S. Graph Neural Network for Symbol Detection on Document Images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 20–25 September 2019; Volume 1, pp. 62–66. [Google Scholar]
Renton, G.; Héroux, P.; Gaüzère, B.; Adam, S. 文档图像符号检测的图神经网络。在 2019 年国际文档分析与识别研讨会(ICDARW) workshops 会议论文集中,悉尼,澳大利亚,2019 年 9 月 20-25 日;第 1 卷,第 62-66 页。[谷歌学术] - Pfoser, D.; Jensen, C.S.; Theodoridis, Y. Novel approaches to the indexing of moving object trajectories. In Proceedings of the 26th VLDB Conference, Cairo, Egypt, 10–14 September 2000; pp. 395–406. [Google Scholar]
Pfoser, D.; Jensen, C.S.; Theodoridis, Y. 移动物体轨迹索引的新方法。在 2000 年 9 月 10 日至 14 日在埃及开罗举行的第 26 届 VLDB 会议论文集;第 395-406 页。[谷歌学术] - Zernike, F. Diffraction theory of the cut procedure and its improved form, the phase contrast method. Physica 1934, 1, 56. [Google Scholar]
Zernike, F. 切割过程衍射理论及其改进形式,相位对比法。物理学报 1934,1,56。[谷歌学术] - Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
张, Z.; 崔, P.; 朱, W. 图上的深度学习:综述。IEEE 知识数据工程杂志,2020。[谷歌学术][交叉引用][绿色版本] - Hamilton, W.L. Graph representation learning. Synth. Lect. Artif. Intell. Mach. Learn. 2020, 14, 1–159. [Google Scholar] [CrossRef]
汉密尔顿,W.L. 图表示学习。综合讲座:人工智能与机器学习,2020,14,1–159。[谷歌学术][交叉引用] - Barthélemy, M. Spatial networks. Phys. Rep. 2011, 499, 1–101. [Google Scholar] [CrossRef] [Green Version]
巴塞莱米,M. 空间网络。物理报告。2011,499,1-101。[谷歌学术][交叉引用][绿色版本] - Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. arXiv 2017, arXiv:1704.01212. [Google Scholar]
吉尔默,J.;肖恩霍兹,S.S.;瑞利,P.F.;维尼亚尔斯,O.;达尔,G.E. 神经消息传递在量子化学中的应用。arXiv 2017,arXiv:1704.01212。[谷歌学术] - Gong, L.; Cheng, Q. Exploiting edge features for graph neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9211–9219. [Google Scholar]
公,L.;程,Q. 利用边缘特征进行图神经网络。在 IEEE 计算机视觉与模式识别会议论文集中,美国加州长滩,2019 年 6 月 16-20 日;第 9211-9219 页。[谷歌学术] - Kalervo, A.; Ylioinas, J.; Häikiö, M.; Karhu, A.; Kannala, J. Cubicasa5k: A dataset and an improved multi-task model for floorplan image analysis. In Scandinavian Conference on Image Analysis; Springer: Cham, Switzerland, 2019; pp. 28–40. [Google Scholar]
Kalervo, A.; Ylioinas, J.; Häikiö, M.; Karhu, A.; Kannala, J. Cubicasa5k:一个数据集和用于平面图图像分析的改进的多任务模型。在斯堪的纳维亚图像分析会议;施普林格:瑞士日内瓦,2019;第 28-40 页。[谷歌学术] - Weisfeiler, B.; Lehman, A.A. A reduction of a graph to a canonical form and an algebra arising during this reduction. Nauchno-Tech. Inform. 1968, 2, 12–16. [Google Scholar]
Weisfeiler, B.; Lehman, A.A. 图的约简到规范形式及其在约简过程中出现的代数。科学技术信息 1968,2,12-16。[谷歌学术] - Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
Ioffe, S.; Szegedy, C. 批标准化:通过减少内部协变量偏移来加速深度网络训练。arXiv 2015,arXiv:1502.03167。[谷歌学术] - Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Kingma, D.P.; Ba, J. Adam: 随机优化的方法。arXiv 2014, arXiv:1412.6980. [谷歌学术] - Wang, M.; Yu, L.; Zheng, D.; Gan, Q.; Gai, Y.; Ye, Z.; Huang, Z. Deep graph library: Towards efficient and scalable deep learning on graphs. arXiv 2019, arXiv:1909.01315. [Google Scholar]
王,M.;余,L.;郑,D.;甘,Q.;盖,Y.;叶,Z.;黄,Z. 深度图库:迈向高效且可扩展的图上深度学习。arXiv 2019,arXiv:1909.01315。[谷歌学术]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
出版者声明:MDPI 对已发表地图中的司法权主张和机构隶属关系保持中立。 |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
© 2021 由作者所有。许可方 MDPI,瑞士巴塞尔。本文为开放获取文章,根据创意共享署名(CC BY)许可协议的条款和条件分发(http://creativecommons.org/licenses/by/4.0/)。










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






