InstructPix2Pix:用指令给图像做修改

论文:InstructPix2Pix: Learning to Follow Image Editing Instructions
代码:GitHub - timothybrooks/instruct-pix2pix
这项工作号称是可以用“咒语”直接编辑图像,连局部涂抹都不需要。看效果:


作者说是用监督学习训练的,那监督学习的数据集从何而来?绝了,用了 GPT-3 和 Stable Diffusion。个人认为文章最大的亮点就在于数据集的收集和制作。

文章用到的先进技术有:GPT-3、Stable Diffusion、Prompt-to-prompt、Classifier-free guidance;其中Prompt-to-prompt 是图像局部修改的原理性基础,也是数据生成的关键之一,强烈推荐阅读!读完别忘回来。
实验对比的技术:SDEdit、Text2Live。
加州伯克利大学2022年11月出品。
1 Abstract & Introduction
摘要首先说,训练数据完全来源于训好的 GPT3 和 Stable Diffusion。而且由于前向传播中执行编辑并且不需要每个示例的微调或反转,因此我们的模型可以在几秒钟内快速编辑图像【说人话就是,只需要单次推理,并不需要拿单个物体做微调训练】。
模型可以根据指令改目标、改风格、改艺术媒介等等【不像以往其他模型,要么只能改固定的风格,要么只能改目标,我们不一样,想改什么改什么】。
2 Prior work【以往相关工作】
【这部分可以不看】
构建大型预训练模型:最近的很多工作展示了大模型合并可以完成一些单个模型无法完成的任务,比如跨模态的各种图像描述(image captioning)、视觉问答,这些任务都需要模型同时掌握语言和图像的知识。
很多进展都用了这种合并技术,比如:在新任务上联合微调、通过prompt交流、构建基于能量的模型的概率分布、利用另一个模型的反馈来指导一个模型、和迭代优化。我们的做法也类似,用了GPT3和Stable Diffusion,不同的是我们用这两个模型来生成多模态训练数据。
基于Diffusion的生成模型:最近的基于扩散的生成模型进展有很多,还有其他模态的生成模型,比如视频、音频、文本、和网络参数。文生图模型也有很多改进工作,可以从任一文本生成逼真图像。
用生成模型做图像编辑:传统上图像编辑模型的目标是一个单个的编辑任务,比如只编辑风格、或者的图像域之间转换。很多图像编辑工作把图像编码进潜空间(比如StyleGAN)然后再修改特征。最近的模型利用 CLIP 嵌入来指导使用文本进行图像编辑。我们与其中一种方法 Text2Live 进行比较,它是一个编辑模型,一种优化附加图像层的编辑方法,可最大化 CLIP 相似性目标。
最近的研究也用了预训练的文生图Diffusion模型来做图像编辑。一些文生图模型天然自带图像编辑啊能力,使用这些模型进行有针对性的编辑并非易事,因为大部分情况下他们不保证相似的文本提示会产生相似的图像。最近Hertz等人的工作 Prompt-to-Prompt 的解决了这个问题,这是一种将生成的图像同化为类似的文本提示的方法,这样可以对生成的图像进行单独的编辑。我们用这种方式生成训练数据。
为了生成非生成的图像(比如真实图像),SDEdit 模型用一个预训练模型把噪声图去噪到目标图,过程中加入目标prompt。我们用了SDEdit 作为baseline。
其他的近期工作比如局部图像修复,给图和用户画的mask,在mask的部位生成新的目标,或者通过反转(和微调)单个图像来执行编辑,随后重新生成新的文本描述。
跟这些工作相反,我们的模型只吃一张图和一个指令,然后直接编辑图,无需用户画mask来添加额外图像,无需对每个样本进行反转或微调。
学习遵循指示:我们的模型不同于现存的基于文本的图像编辑工作,只需要告诉模型做什么修改,无需对输入和输出图像做描述。这样做的关键好处是用户可以只用语言告诉模型要做什么。不需要提供额外信息,比如样例或其他描述。命令可以是富有表现力、精确且直观的,这就允许用户很容易地隔离特定对象或说明要改变的视觉属性。
我们用指令编辑图像的灵感来源于近期的工作,这项工作教会了大模型更好地执行人的指令。
用生成模型生成训练数据:深度学习通常要求很大的训练数据。从网络收集通常很合适,但不太适合监督学习,比如只在特定位置有变化的配对的图像。随着生成模型的不断改进,人们越来越有兴趣将其用作下游任务的廉价且丰富的训练数据来源。这篇文章汇总,我们用两个不同的模型来得到训练数据。
3 Method【方法】
这章就讲两件事:1)如何生成数据集(章节3.1);2)如何基于上一步生成的训练数据,训练一个图像编辑扩散模型(章节3.2);
下面是论文给的模型结构图:

这里再贴一个我自己画的模型结构图,方便理解。
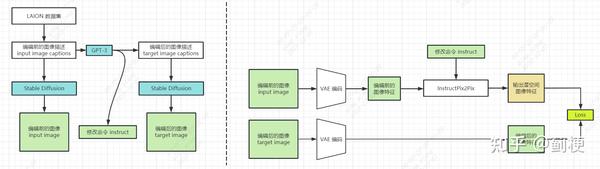
3.1 生成一个多模态训练数据集
这一节的目标是要生成配对的数据集,每组数据包括一个文本命令(instruct)和对应的两张图片(intput 和 target)。
生成过程分为两步,第一,如何微调 GPT3 来生成配对的文本编辑的命令:给一张图的图像描述,生成一个命令来说明要改的内容,同时生成一个对应的编辑后的图片描述(章节3.1.1,上面结构图的左半部分);第二,使用文生图模型,根据两个文本提示(编辑前图像描述和编辑后图像描述)生成一对相应图像(章节3.1.2,上面结构图的有半部分)。
3.1.1 生成命令和配对的图片描述
大语言模型GPT3需要吃一个图像描述,吐一个修改图像的命令和目标图像的描述。例如,给gpt3喂一个图像描述:“一个女孩骑着马的图片”,语言模型可以生成合理的编辑命令:“让她骑龙”和编辑后的图像描述:“一个女孩骑着龙的图片”。这个语言模型就能生成多样的编辑,同时保持图像的变化点跟命令文本是匹配的。
我们的语言模型GPT3是在一个小的手写数据集上微调的,这个数据集包括:1)编辑前的图像描述;2)图像编辑命令;3)编辑后的图像描述。为了处理微调数据集,我们从LAION-Aesthetics V2 6.5+ 数据集里采集了700个输入图像描述(captions),手写了命令和输出图像描述。下表是我们写命令和输出图像描述的样例。

用这个数据集,我们微调了GPT-3 Davinci 模型一个epoch,参数是默认的训练参数。
受益于GPT3巨大的知识和生成能力,我们微调的模型可以生成有创意但又合理的命令和图像描述。用这个模型我们的生成大量的编辑和输出图像描述,而且输入图像描述还来源于LAION-Aesthetics。我们选这个数据集是因为它量大、多样(包括专有名词和流行文化),和大量媒介(照片、画、数字艺术)。LAION 潜在缺点是有很多噪声,包含大量无意义或者难以描述的图像描述文本,然而我们发现数据集噪声可以通过组合一些过滤操作来缓解(看章节3.2.1,也就是Classifier-free Guidance)。我们最终的语料库包含生成的命令454条,图像描述445条。
3.1.2 用配对的描述生成配对的图像
这一步用训练好的 stable diffusion 根据配对的图像描述生成对应的图像。
有一个挑战是,文生图模型生成出来的图像非常不确定,非常微小的条件变化可能会让生成的图很不一样。比如下面这张图(a),“骑马的女孩”和“骑龙的女孩”,不仅骑的东西变了,连画面视角、草场颜色、远处背景都变了。这显然不适合作为目标。本文的目标是想让生成的配对图就像下图右边(b)这样,什么都没变,只有骑的东西变了。

如何解决这个问题呢,作者采用最近提出的 Prompt-to-Prompt 方法,这个方法的目标是鼓励文生图扩散模型的多个生成结果更相似,它是在一些去噪步骤中借用了交叉注意力权重。上面这张图的(b)就是 Prompt-to-Prompt 的效果。
尽管这个方式在生成图像方面帮了很大忙,还有个问题是不同的编辑操作对图像空间的修改粒度不一样。例如,一些大尺度的修改,比如移除或替换画面中的目标,会让生成的配对图像有比较小的相似度。幸运的是,Prompt-to-Prompt 有这样一个参数来控制两张图之间的相似度:具有共享注意力权重的去噪步骤 p 的分数。不幸的是,仅从图像描述和编辑命令里获得合适的p值很困难。因此,这里给每对图像描述都生成了100张图,其中每次生成时都用随机的 p~U(0.1,0.9),然后用基于CLIP的指标过滤一下:这个指标是计算在CLIP空间中的定向相似度。这个指标测量两张配对图的CLIP空间的一致性和配对的图像描述在CLIP空间的一致性。这个过滤的结果不仅帮助最大化了图片对儿的多样性和质量,而且使生成的数据对故障更鲁棒【这块好像没说过滤阈值?】。
3.2 InstructPix2Pix
这一步是用生成数据来训一个条件扩散模型,模型框架基于 Stable Diffusion。
扩散模型通过学习一系列去噪编码过程来生成数据。潜空间扩散模型(Latent diffusion)用预训练的带编码器E和解码器D的自编码器AE,把图像编码到潜空间,来提高扩散模型的质量和效率。对于一张图x,先编码到潜空间,编码成z,再根据时间步t添加不同程度的噪声,让扩散模型学习从噪声图中预测噪声,过程中加入条件文本命令C_T。然后最小化潜空间目标:
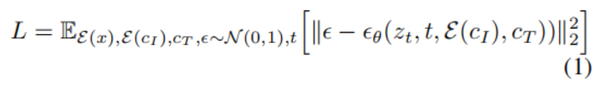
王等人表示,对于图到图的翻译任务,微调大型图像扩散融合模型优于从头开始训练模型,特别是当配对训练数据有限时。因此作者用Stable Diffusion 做为模型的权重初始化,充分利用它庞大的文生图的能力。为了支持图像条件,还给卷积层添加了额外的输入通道,把z_t和E(c_I)concat到一起。所有的扩散模型权重初始化都来源于预训练checkpoints,与新加的输入通道相关的权重初始化为0。我们重用最初用于图像描述的相同文本条件机制,以文本编辑指令 cT 作为输入。
3.2.1 对两个条件的 Classifier-free Guidance
Classifier-free Guidance 是扩散模型中一种权衡生成样本质量和多样性的方法。它通常用于类别条件和文本条件图像生成,来提高生成图像的视觉质量,使生成的图像与条件更加匹配。Classifier-free Guidance 有效地将概率质量转移到隐式分类器 pθ(c|zt) 为条件 c 分配高可能性的数据上。Classifier-free Guidance 的实现涉及联合训练条件和无条件去噪的扩散模型,并在推理时结合两个分数估计。无条件去噪的训练只需在训练期间以某个频率将条件设置为固定空值 c = ∅ 即可完成。在推理时,在指导尺度 s ≥ 1 的情况下,修改后的分数估计 e~θ(zt, c) 沿朝向条件 eθ(zt, c) 并远离无条件 eθ(zt, ∅) 的方向外推 。
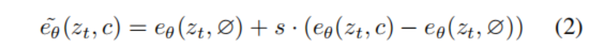
在这里的任务中,分数网络 e_\theta(z_t, c_I, c_T) 有两个条件:输入图像 c_I 和文本命令 c_T。我们发现对于这两种条件来说,利用无分类器指导是有益的。Liu等人阐述了一个条件扩散模型可以根据多个不同的条件值组成分数估计。我们把这个概念应用到具有两个独立条件输入的模型。在训练过程中,我们随机设置5%的样例为仅 c_I= ∅ ,5%的样例为仅 c_T= ∅, 5%的样例为既c_I= ∅ 又 c_T= ∅。因此,我们的模型能够对两个或其中一个条件输入进行有条件或无条件去噪。我们介绍两个引导尺度s_I 和s_T,它们可以被用来权衡输出图像与输入图像的相似度和输出图像与质量的匹配度。我们的分数估计公式是:
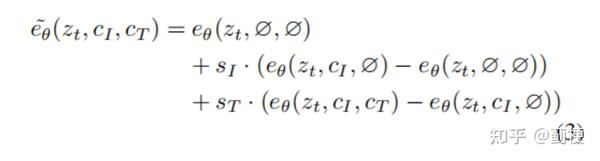
后面的把大卫雕像图编辑为机器人的图例,展示了生成样本上这两个参数的影响。
4 Results【实验部分】
实验部分展示了基于指令的图像编辑模型的生成效果,包括在多种真实照片和艺术作品上的效果,和多种类型的编辑命令的效果。模型成功完成了很多有挑战性的编辑,包括替换目标、改变季节、替换背景、修改材质、转换艺术媒介、及其他。
作者对比了该方法与另外两个近期工作的质量,SDEdit 和 Text2Live。由于这个方法跟之前的方法有区别,这里的图像编辑方法只用命令来编辑图像,之前的方法都需要对图像做描述。因此,作者为他们提供“编辑后”文本描述,而不是编辑指令。作者也定性地对比了模型与SDEdit的质量,用了两个指标来测量图像一致性和编辑质量,这块的描述在章节4.1。最后,用消融实验展示了生成的训练数据的大小和质量如何影响我们模型的性能(章节 4.2 )。
4.1 对比基线
作者提供了与 SDEdit 和 Text2Live 的定性和定量对比。
SDEdit 是图像编辑方面的用了预训练扩散模型的技术,其中部分加噪的图像被喂给模型,然后去噪生成新的编辑后的图像。本文方法与 SDEdit 的公共稳定扩散实现进行比较。
Text2Live 是一种通过生成颜色+不透明度增强层来编辑图像的技术,以文本提示为条件。这里拿本文方法与Text2Live的作者发布的公开模型实现进行比较。
先比较定性效果,请看下图:

注意到,虽然 SDEdit 对于内容大致保持不变而样式发生变化的情况相当有效,它还是会努力保持身份、隔离单个对象,特别是改变很大时。此外,它要求对整个输出图像进行描述,而不只是编辑命令。另一方面,尽管Text2Live可以通过编辑附加增来让结果更令人信服,它的公式限制了它可以编辑的类别。
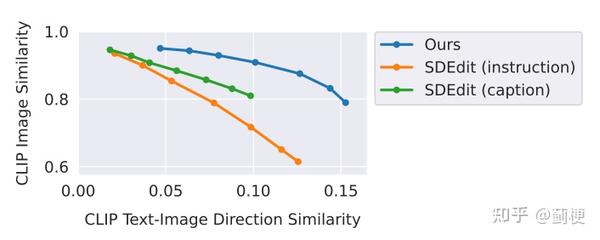
定量评价结果可以看下图。作者画了两个指标的权衡,CLIP图像编码的cos相似度(输出图像和输入图像的一致程度),和定向CLIP相似度(输出图像和文本的一致性)。这两个是竞争指标,让输出图像更贴近命令,会导致输出图像与输入图像更不一致。然而,作者发现拿本文模型跟SDEdit比,对于相同的方向相似度值,本文的结果具有明显更高的图像一致性(CLIP 图像相似度)。
4.2 Ablations【消融实验】
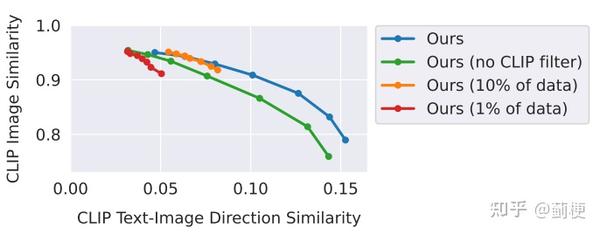
下图中,作者提供了定量的消融实验,看看选的数据集size和在3.1章说的过滤对于最终效果的影响。
作者发现减少数据通常会导致图像编辑能力的下降,而不仅仅是进行细微或风格化的图像调整(因此会导致高相似度分数,低一致性分数)。从生成的数据中移除过滤操作,有个不同的影响:整体图像与输入图像的一致性降低。
作者也提供了两个classifier-free guidance scales的影响,看下图。

增加s_T值会让编辑能力更强(让输出与命令更一致),增加s_I会保持输入图像的特有结构(输出与输入会更一致)。作者发现s_T值在5~10之间、s_I值在1~1.5之间通常会有比较好的结果。
在实践中,对于论文中显示的结果,发现调整每个示例的指导权重以在一致性和编辑强度之间获得最佳平衡是有益的【意思是每个样本都得单独调参?】。
5 Discussion
我们阐述了一个方法,结合两个大预训练模型,来生成一个扩散模型的数据集,用来训练一个根据命令编辑图像的模型。尽管我们的模型可以进行广泛的编辑,包括风格、媒介、纹理,它还是有很多局限性。
【局限性】我们的模型被生成图像的视觉质量所限制,因此也受限于生成图像的扩散模型。此外,模型泛化到新编辑,以及在视觉变化和文本指令之间建立正确关联的能力,受限于微调 GPT-3 的人工编写指令,受限于GPT-3 生成指令和图像描述的能力,受限于Prompt-to-Prompt 修改图像的能力。特别地,我们的模型在计算目标数量和空间推理时遇到困难(例如“把它移到图像左边”“交换它们的位置”“把两个杯子放在桌子上,一个放在椅子上”),正如Prompt-to-Prompt 在 Stable Diffusion 的那样。失败的样例如下:

此外,本文方法所基于的数据和预训练模型中存在有据可查的偏见,因此该方法中编辑后的图像可能会继承这些偏见或引入其他偏见。

【未来工作】除了减轻上述限制之外,此项工作也引出新问题,比如:如何遵循空间推理的指令,如何将指令与其他条件模式(例如用户交互)相结合,以及如何评估基于指令的图像编辑。结合人类反馈来改进模型是未来工作的另一个重要领域,并且可以应用诸如人机循环强化学习之类的策略来改善我们的模型和人类意图之间的一致性。
(InstructPix2Pix done.)

有一个问题 在训练InstructPix2Pix模型的时候本文给的那副过程图是不是不对,论文里并没有给出额外的loss,只有预测噪声的loss。我的理解是在训练过程中将数据集中的输出照片和指令作为输入进行训练,原始图片作为条件插入到一个卷积层中。而不是像您图中描述的那样两张输出图片做比较![[发呆]](https://pic2.zhimg.com/v2-7f09d05d34f03eab99e820014c393070.png)
是哦,流程图上的标记写错了,是图像经过VAE编码后得到的潜空间特征之间计算loss。感谢提醒,已修正。
请问一下作者大大,我的这个理解对吗![[害羞]](https://pic4.zhimg.com/v2-52f8c87376792e927b6cf0896b726f06.png)